







一、 基础知识
你会如何处理实时或准实时数据流?
在大数据时代,有很多方案可以帮助你完成这项任务。
接下来,我将通过一个系列的教程,我将利用Storm、Kafka、ElasticSearch逐步教你搭建一个实时计算系统。
搭建系统之前,我们首先需要了解一些定义。
通过考虑四个不同的属性,帮助你更好地理解大数据:数据量,速度,多样性和准确性。
-
数据量:海量数据
-
速度:数据处理的速度
-
多样性:任何类型的数据,包括结构化和非结构化
-
准确性:传入和传出数据的准确性
存在具有不同用途的大数据工具:
-
数据处理工具对数据执行某种形式的计算
-
数据传输工具将数据收集和引入数据处理工具
-
数据存储工具在不同处理阶段存储数据
数据处理工具可进一步分类为:
-
批处理:批处理是要一起处理的数据的集合。批处理允许你将不同的数据点连接、合并或聚合在一起。在整个批处理完成之前,其结果通常不可用。批处理越大,等待从中获取有用信息的时间越长。如果需要更直接的结果,流处理是更好的解决方案。
-
流处理:流处理器作用于无限制的数据流,而不是连续摄取的一批数据点(“流”)。与批处理过程不同,流中没有明确定义的数据流起点或终点,而且,它是连续的。
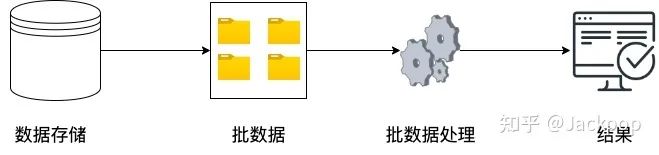
批处理
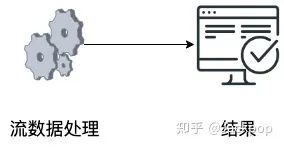
流梳理
示例数据和方案
我们将使用一些实际数据来数据规约系统(DRS)。根据维基百科,“数据规约是将数字或字母数字信息…转换为校正,有序和简化的形式。基本概念是将大量数据规约为有意义的形式。”
数据源将是实际的航空公司历史飞行数据,我们的最终目标是能够在地图上显示航班历史数据。
我们将构建的最终数据处理链路如下图所示:

可以使用SMACK替代上述方案:
-
Spark:引擎(替代Storm)
-
Mesos:容器
-
Akka:模型
-
Cassandra:存储(替代ElasticSearch)
-
Kafka:消息队列
或者,你可以尝试自己使用自己喜欢的编程语言来实现它。
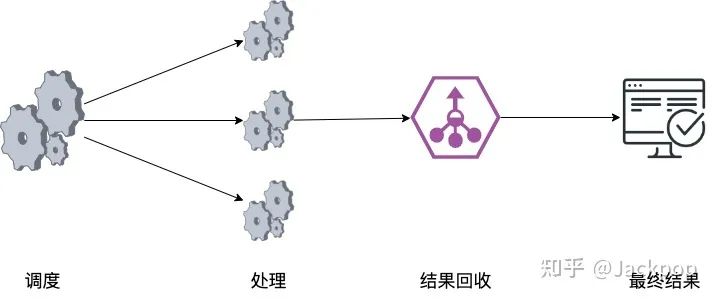
单线程调度程序使用以下方式以循环方式将工作分配给多个处理器(例如,可以是Raspberry Pi的阵列)。MQTT用于数据交换。每个处理器并行处理数据并产生结果,这些结果由收集器收集,收集器负责将其存储到数据库,NAS或实时呈现。
由于我们没有与用于接收实时飞行数据的真实传感器(例如雷达)建立任何连接以演示实际流处理,因此我们只能选择批处理(即下载历史飞行数据并离线处理它们)。
我们将首先将数据直接存储到ElasticSearch并在Kibana或其他UI应用程序中可视化它们。
ElasticSearch
ElasticSearch是一个面向文档的分布式搜索引擎,用于处理以文档形式存储数据。
ElasticSearch具有如下优势:
-
跨多个节点可扩展
-
搜索结果速度非常快
-
多语种
-
面向文档
-
支持即时搜索
-
支持模糊搜索
-
开源,不收费
ElasticStack由许多产品组成:
-
ElasticSearch:我们将在本文中重点介绍的
-
Kibana:一个分析和可视化平台,可让你轻松地可视化Elasticsearch中的数据并进行分析
-
LogStash:数据处理管道
-
Beats:数据传输集合
-
X-pack:可为Elasticsearch和Kibana添加其他功能,例如安全性(身份验证和授权),性能(监控),报告和机器学习
综上所述,可以使用Beats和/或Logstash将数据导入Elasticsearch,也可以直接通过ElasticSearch的API。Kibana用于可视化ElasticSearch中的数据。
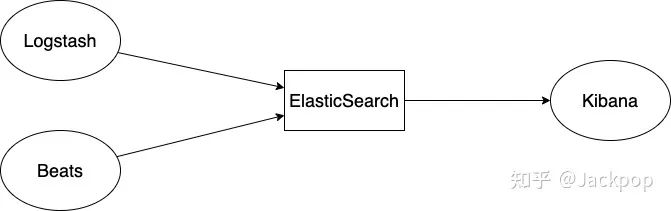
接下来,我们将学习如何安装,启动和停止ElasticSearch和Kibana。
1. 安装ElasticSearch & Kibana
访问ElasticSearch网站,下载安装包,解压,然后进行接下,你会发现它包含如下内容:
bin
config
data
jdk
lib
logs
modules
plugins它的主要配置文件是config/elasticsearch.yml。
通过如下命令,可以运行ElasticSearch,
cd <elasticsearch-installation>
bin/elasticsearch使用浏览器打开链接http:// localhost:9200/,如果看到类似以下的内容,那么恭喜你,你已经正常运行ElasticSearch实例了。
{
"name" : "MacBook-Pro.local",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "jyxqsR0HTOu__iUmi3m3eQ",
"version" : {
"number" : "7.9.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "a479a2a7fce0389512d6a9361301708b92dff667",
"build_date" : "2020-08-11T21:36:48.204330Z",
"build_snapshot" : false,
"lucene_version" : "8.6.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
ElasticSearch由一组节点组成(也就是存储数据的ElasticSearch实例),每个节点存储部分数据,同一台计算机上运行多个实例。
http://localhost:9200/_cluster/health?pretty
{
"cluster_name" : "elasticsearch",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
集群状态为green,我们看到它仅包含1个节点。数据作为JSON对象(或文档)存储在ElasticSearch中,使用索引将文档组织在群集内。索引是具有相似特征并在逻辑上相关的文档的集合,通过索引,在逻辑上将文档分组在一起,并提供与可伸缩性和可用性相关的配置选项。
数据分布在各个节点中,但是,实际上是如何实现的呢?
ElasticSearch使用分片。
分片是一种将索引分为不同部分的方法,其中每个部分称为分片,分片可水平缩放数据。
如果发生磁盘故障并且存储分片的节点发生故障,该怎么办?
如果我们只有一个节点,那么所有数据都会丢失。
默认情况下,ElasticSearch支持分片复制以实现容错功能。主碎片的副本碎片在存储主碎片的节点以外的节点中创建。主分片和副本分片都称为复制组。在我们只有一个节点的示例中,没有复制发生。如果磁盘出现故障,我的所有数据都会丢失。我们添加的节点越多,通过在节点周围散布碎片就可以提高可用性。
ElasticSearch集群暴露REST API,使得开发者可以通过GET POST PUT DELETE命令进行访问。
有多种方法可以向ElasticSearch发出命令。
-
通过在浏览器中或使用
curl命令 -
通过Kibana的控制台工具
curl的访问语法如下:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>'参数解释:
-
<VERB>:HTTP请求方法,GETPOSTPUTDELETE -
<PROTOCOL>或.:如果你在Elasticsearch前面有HTTPS代理,或者使用Elasticsearch安全功能来加密HTTP通信,请使用后者 -
<HOST>:Elasticsearch集群中任何节点的主机名 -
<PORT>:运行Elasticsearch HTTP服务的端口,默认为9200 -
<PATH>:API的endpoint -
<BODY>:JSON编码的请求正文
例如:
curl -X GET "localhost:9200/flight/_doc/1?pretty"将返回存储在索引中的所有文档,由于我们尚未在ElasticSearch中插入任何文档,因此该查询将返回错误。
前面介绍了ElasticSearch的安装方法,下面介绍一下Kibana的安装。
访问网站下载安装包,解压,通过下方命令运行Kibana:
cd <kibana-installation>
bin/kibana在启动Kibana之前,请确保ElasticSearch已启动并正在运行。
Kibana的目录结构如下:
bin
built_assets
config
data
node
node_modules
optimize
package.json
plugins
src
webpackShims
x-pack首次运行Kibana(http://localhost:5601)时,会让你提供样本数据或自行探索。
使用浏览器发送下方命令:
GET /_cat/health?v会得到下方信息:
epoch timestamp cluster status node.total node.data shards pri relo init unassign pending_tasks max_task_wait_time active_shards_percent
1585684478 19:54:38 elasticsearch green 1 1 6 6 0 0 7 0 - 100.0%_catAPI提供有关属于群集的节点的信息。
有一个更方便的API GET /_cat/indices?pretty,它提供了有关节点的更多详细信息。
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open .apm-custom-link ticRJ0PoTk26n8Ab7-BQew 1 0 0 0 208b 208b
green open .kibana_task_manager_1 SCJGLrjpTQmxAD7yRRykvw 1 0 6 99 34.4kb 34.4kb
green open .kibana-event-log-7.9.0-000001 _RqV43r_RHaa-ztSvhV-pA 1 0 1 0 5.5kb 5.5kb
green open .apm-agent-configuration 61x6ihufQfOiII0SaLHrrw 1 0 0 0 208b 208b
green open .kibana_1 lxQoYjPiStuVyK0pQ5_kaA 1 0 22 1 10.4mb 10.4mb在这一部分,
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1966
1966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









