







搭建Hadoop平台
1. 安装Hadoop和JDK
-
首先大家要有Hadoop的Linux版本和JDK1.8,可以在官方网站上下载
-
下载完成后解压到指定的位置
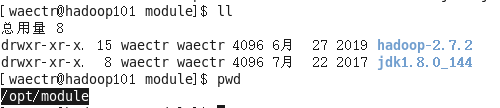
-
在这里首先清除之前系统自带的JDK,这里我使用的是
sudo yum -y remove java
- 然后就是配置JDK和Hadoop的系统配置
sudo vi /etc/profile
## 详细的配置如下所示
##JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_144
export PATH=$PATH:$JAVA_HOME/bin
##HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-2.7.2
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
- 然后让配置文件生效
source /etc/profile
2. 准备三个虚拟机
假设我们之前已经配置好一台虚拟机,此时我们将它克隆三个
- 克隆好三台虚拟机后,我们首先要进行网络配置
vim /etc/udev/rules.d/70-persistent-net.rules
进入后就是个样子,然后我们把上面的 ‘eth0’那行删掉,把下面‘eth1’改为‘eth0’,并且复制记下ATTR{address}列

- 设置IP
vim /etc/sysconfig/network-scripts/ifcfg-eth0
进入后,将刚才复制的ATTR{address}粘贴到HWADDR,设置对应的IPADDR
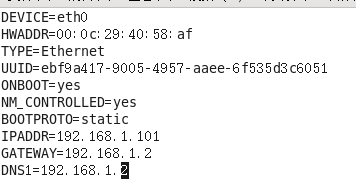
DEVICE(接口名,默认eth0)
HWADDR(MAC地址,默认)
TYPE(网络类型,默认Ethernet)
UUID(随机id,不用管它)
ONBOOT(系统启动时网络接口是否有效;默认是no,改为yes)
BOOTPROTO(IP的配置方法,后面需要用固定ip连接虚拟机,所以设置为静态ip,改为static),
IPADDR(虚拟机的IP地址,手动添加,注意网段要与win中ip网段一致)
- 设置主机名
vim /etc/sysconfig/network
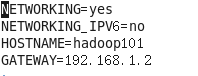
每台主机设置不同的主机名
在 vim /etc/hosts 中设置好对应,方便直接用名字连接
- 关闭防火墙
查看防火墙
service iptables status
关闭防火墙
service iptables stop
查看防火墙开机启动状态
chkconfig iptables --list
关闭防火墙开机启动
chkconfig iptables off
- 给予用户root权限
vim /etc/sudoers 加入一行
hadoop(此为用户名hadoop) ALL=(ALL) NOPASSWD:ALL
做完,记得重启!
到这里,大家就可以Ping一下了看三台机子之间通不通
3. 配置集群
- 集群部署规划
| hadoop101 | hadoop102 | hadoop103 | |
|---|---|---|---|
| HDFS | NameNode,DataNode | DataNode | SecondaryNameNode,DataNode |
| YARN | NodeManager | ResourceManager,NodeManager | NodeManager |
- 核心文件
配置core-site.xml
[waectr@hadoop101 hadoop]$ vi core-site.xml
在该文件中编写如下配置
<!-- 指定HDFS中NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop101:9000</value>
</property>
<!-- 指定Hadoop运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop-2.7.2/data/tmp</value>
</property>
- HDFS配置文件
配置hadoop-env.sh
[atguigu@hadoop102 hadoop]$ vi hadoop-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置hdfs-site.xml
[atguigu@hadoop102 hadoop]$ vi hdfs-site.xml
在该文件中编写如下配置
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<!-- 指定Hadoop辅助名称节点主机配置 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>hadoop103:50090</value>
</property>
- YARN配置文件
配置yarn-env.sh
[atguigu@hadoop102 hadoop]$ vi yarn-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置yarn-site.xml
[atguigu@hadoop102 hadoop]$ vi yarn-site.xml
在该文件中增加如下配置
<!-- Reducer获取数据的方式 -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 指定YARN的ResourceManager的地址 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop102</value>
</property>
- MapReduce配置文件
配置mapred-env.sh
[atguigu@hadoop102 hadoop]$ vi mapred-env.sh
export JAVA_HOME=/opt/module/jdk1.8.0_144
配置mapred-site.xml
[atguigu@hadoop102 hadoop]$ cp mapred-site.xml.template mapred-site.xml
[atguigu@hadoop102 hadoop]$ vi mapred-site.xml
在该文件中增加如下配置
<!-- 指定MR运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 发送出去
sudo scp -r xxx root@hadoop103:xxx
4. 配置SSH
找到家目录下的.shh文件夹(这是一个影藏的文件夹)

生成秘钥的指令时
ssh-keygen -t rsa
然后分发出去
ssh-copy-id hadoop102
为每个服务器都配置
5. 集群群起
启动集群前要先格式化集群,注意格式化之前,一定要先停止上次启动的所有namenode和datanode进程,然后再删除data和log数据,用jps查看现在的java进程
bin/hdfs namenode -format
启动HDFS,启动的时候在NameNode配置的机器上群起HDFS
start-dfs.sh / stop-dfs.sh
启动Yarn,启动的时候在ResouceManager配置的机器上启动Yarn
start-yarn.sh / stop-yarn.sh
注:以上群起的时候都要配置SSH连接
此时集群启动完成,要在 http://hadoop101:50070/dfshealth.html#tab-startup-progress 上查看HDFS的信息
HDFS的相关操作
这里在网上查询了相关的操作指令做了整理
上传文件到集群
- 上传小文件
hdfs dfs -mkdir -p /user/atguigu/input
hdfs dfs -put wcinput/wc.input /user/atguigu/input
- 上传大文件
bin/hadoop fs -put /opt/software/hadoop-2.7.2.tar.gz /user/atguigu/input
上传文件后查看文件存放在什么位置
查看HDFS在磁盘存储文件内容
cat blk_1073741825
下载
bin/hadoop fs -get /user/atguigu/input/hadoop-2.7.2.tar.gz ./















 2186
2186











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









