






在SVM的推导中,我们有 [目标函数为最大化几何边距]
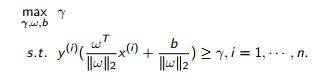
进一步根据几何边距和函数边距的关系,有
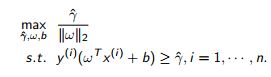
继而转化为最大化包含函数边距的目标函数
在这里,很多文章都会不加证明的给出函数边距 = 1 继而转化为仅关于w和b的凸优化问题。 本文想要回答为什么函数边距 = 1。
首先需要指出,对于 wx + b = 0 ,等比例的放缩w和b,超平面不会改变。
举个例子,原方程为wx + b = 0, 现在两边同乘10 => 10wx + 10b = 0 ,我们令 w' = 10w , b' =10b 那么 w'x +b' = 0
,与wx + b = 0,所描述的是同一个超平面
很多人都明白上面的道理。于是有的人会说,那我们就对上面的约束条件,左右同时除以函数边距,不就变成
了吗?目标函数里的函数边距也没有了。
这里我想反问一句,
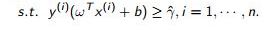
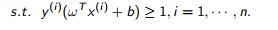
描述的真的是一件事吗?
需要指出的是,函数边距在这里是一个变量,并不是一个常量。如果这个过程就能帮助我们把一个三变量的凸优化问题轻而易举的变成一个两变量的凸优化问题,那么凸优化问题真的会简化好多了。
所以我们首先需要明确的是,这里为了 解这个三变量的凸优化问题,
是附加上了 s.t.= 1 这一个约束条件(而不是很多人心里的所谓"等价变换"),从而把它变成一个两变量(严格来说w是一个向量)的优化问题从而才能接着进行对偶求解。
确定了这件事后,接着回答为什么可以 s.t = 1 :
= y* (w x* + b) 这里(x*,y*)指support vector ,即那些构成支撑超平面的点。
这实际上是函数边距所满足的约束,对于一个确定的训练集合,如果我们等比例的放缩w和b,就是上面讨论过的过程,那么函数边距的值会随着w和b的值变得很大而很大,即使这些w和b描述的仍是同一个超平面。但是几何边距仍然是不变的,这也是我们一开始最优化的是几何边距的原因。
如果取 = 1的话,优化得出了一组w和b,再取
= 10 ,100 ,1000 ......得到了很多组的w和b,显然,随着
的变大,优化得到的w和b也相应的变的很大了,但是,它们描述的全都是一个超平面,也就是说它们是完全等价的,那么我们为什么不直接让
= 1 从而得到一组相对“平凡”的w和b呢?
如果用凸优化的观点去思考这件事:假设现在电脑上有一个凸优化的软件,只要输入目标函数和约束条件就可以解出凸优化问题,现在目标函数是一个非凸的形式,我们想方设法的想把它变凸然后解出来,这就是所要思考的方向和目标。
最后总结起来:这是一个三变量的凸优化问题,按照上面的分析,它的解是无穷多组的,但是这些解是"等价"的(描述的是同一个超平面),所以为了 解出一组解,我们加入约束 = 1















 453
453

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









