







Abstract
我们使用CLIP编码作为标题的前缀,通过使用一个简单的映射网络,然后微调一个语言模型来生成图像标题。最近提出的CLIP模型包含丰富的语义特征,经过文本上下文的训练,使其最适合视觉语言感知。我们的关键思想是,结合预先训练的语言模型(GPT2),我们可以获得对视觉数据和文本数据的广泛理解。因此,我们的方法只需要相当快速的训练,以产生一个合格的字幕模型。无需额外的注释或预先训练,它可以有效地为大规模和多样化的数据集生成有意义的标题。令人惊讶的是,即使只训练了映射网络,我们的方法也能很好地工作,而CLIP和语言模型都保持冻结状态,允许使用较少可训练参数的轻量级架构。
Introduction
这项任务带来了两大挑战。首先是语义理解。这方面的任务范围从简单的任务,如检测主要对象,到更复杂的任务,如理解图像中所描述的部分之间的关系。例如,在图1左上角的图像中,模型知道这个物体是一个礼物。第二个挑战是描述一张图片的方法太多了。在这方面,训练数据集通常指定给定图像的最佳选项。
our method produces a prefix for each caption by applying a mapping network over the CLIP embedding. This prefix is a fixed size embeddings sequence, concatenated to the caption embeddings. These are fed to a language model, which is fine-tuned along with the mapping network training. At inference, the language model generates the caption word after word, starting from the CLIP prefix. 在CLIP嵌入上应用映射网络为每个标题生成一个前缀。这个前缀是一个固定大小的嵌入序列,连接到标题嵌入。这些数据被输入到一个语言模型中,该模型与映射网络训练一起进行微调。在推断时,语言模型从CLIP前缀开始生成一个接一个的标题词。
we train only the mapping network, while both CLIP and the language model are kept frozen. 我们只训练映射网络,而CLIP和语言模型都被冻结。
Method
CLIPCap模型的关键思想其实就是利用CLIP模型所构造的丰富的语义embedding。受到【47】的启发,模型将这个embedding当作是caption的前缀。由于前缀中已经包含了所要求的语义信息,那么就可以使用自回归语言模型来预测下一个token而不用考虑未来的token。
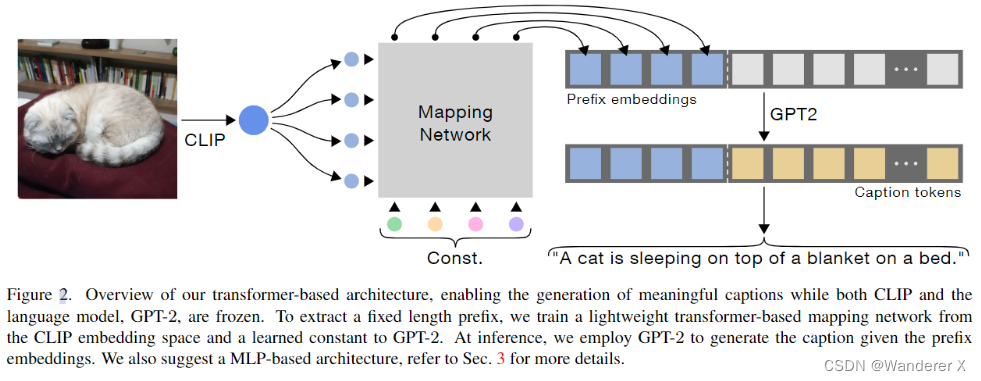
为了提取固定长度的前缀,我们从CLIP嵌入空间和GPT-2的学习常数中训练一个轻量级的基于transformer的映射网络。在推理时,我们使用GPT-2在给定前缀嵌入的情况下生成标题。我们还建议采用基于mlp的体系结构,更多细节请参阅第3节。
LM的微调
在训练期间,我们的主要挑战是在CLIP表示和语言模型之间进行转换。尽管两种模型对文本的表达都丰富多样,但它们的潜在空间是独立的,因为它们不是共同训练的。此外,每个标题数据集合并了不同的风格,这对于预先训练的语言模型可能不太自然。因此,我们建议在训练映射网络的过程中对语言模型进行微调。这为网络提供了额外的灵活性,并产生了更有表现力的结果。
但是这样做参数量太大了,所以使用前缀,网络参数是冻结的
将语言模型冻结,而只训练mapping网络。经过实验证明,通过这种方式训练出来的模型能够在某些实验当中获得不错的效果。
同时,作者提到,对CLIP进行fine-tuning的话并不会提高结果的质量,反而会增加训练时间以及复杂度。一种猜想是CLIP的隐空间中已经包含了所需要的信息,导致微调丧失作用。
映射网络 mapping network
模型的关键组成部分是中间的映射网络。映射网络的作用是将 CLIP 嵌入转换为 GPT-2 空间。
当语言模型同时进行微调时,映射的挑战性较小,因为可以很容易控制两个网络。 因此,在这种情况下,作者使用了多层感知器(MLP)。 即使用单个隐藏层,模型也能够生成已经获得了逼真且有意义的Caption。
但是当语言模型被冻结的时候,就不能再使用MLP了。此时作者选择使用Transformer。
transformer有两个输入,CLIP的视觉编码和可学习的常量(constant)。
常量有两个作用,首先,通过多头注意力从 CLIP 嵌入中检索有意义的信息。 其次,它可以学习去调整固定的语言模型到新数据上。
Inference
在推理过程中,模型通过 CLIP 编码器和映射网络 F 提取输入图像 x 的视觉前缀(visual prefix)。然后开始生成以视觉前缀为条件的caption,并在语言模型输出的指导下逐个预测下一个token。 对于每个token,语言模型输出所有词汇标记的概率,这些概率用于通过采用贪心方法或束搜索来确定下一个token。
结论
我们认为我们的方法是一个新的图像标题范式的一部分,专注于利用现有的模型,而只训练一个最小的映射网络这种方法本质上是学习使预先训练的模型的现有语义理解适应目标数据集的风格,而不是学习新的语义实体。
我们相信,利用这些强大的预训练模型将在不久的将来获得吸引力。














 299
299











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









