







Abstract
论文提出了一种新颖的方法,通过赋予代理想象力,使其能够完成创造性任务。作者将代理分解为想象器和控制器,其中想象器负责将语言指令转换为具体的任务结果想象,而控制器则根据当前状态、想象和语言指令采取行动。论文提出了两种想象器变体(基于大型语言模型和基于扩散模型的视觉想象器)以及两种控制器变体(行为克隆控制器和基于GPT-4(V)的控制器)。实验证明,所提出的创造性代理能够在Minecraft的生存模式中创建各种多样化且视觉上令人满意的建筑,这在以前的研究中从未实现过。
Preliminaries
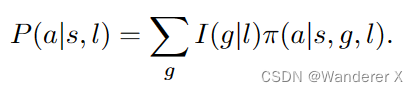
这个公式表示了创造性智能体的核心概念:将代理分解为想象器(imaginator)和控制器(controller)。公式中的各个部分如下:
P(a|s, l):代理在状态s和语言指令l下采取动作a的概率。
g:表示对所有可能的想象结果g进行求和。
I(g|l):想象器I将指令l转换为想象结果g的概率。
π(a|s, g, l):控制器π根据当前状态s、想象结果g和语言指令l选择动作a的概率。
这个公式意味着,在给定状态s和语言指令l的情况下,代理采取动作a的概率取决于所有可能的想象结果g的概率和在给定状态s、想象结果g和语言指令l下选择动作a的概率。这样,我们可以将不确定性和创造性从创造性任务中分离出来,并通过想象器和控制器的设计选择来构建创造性智能体。
Architecture
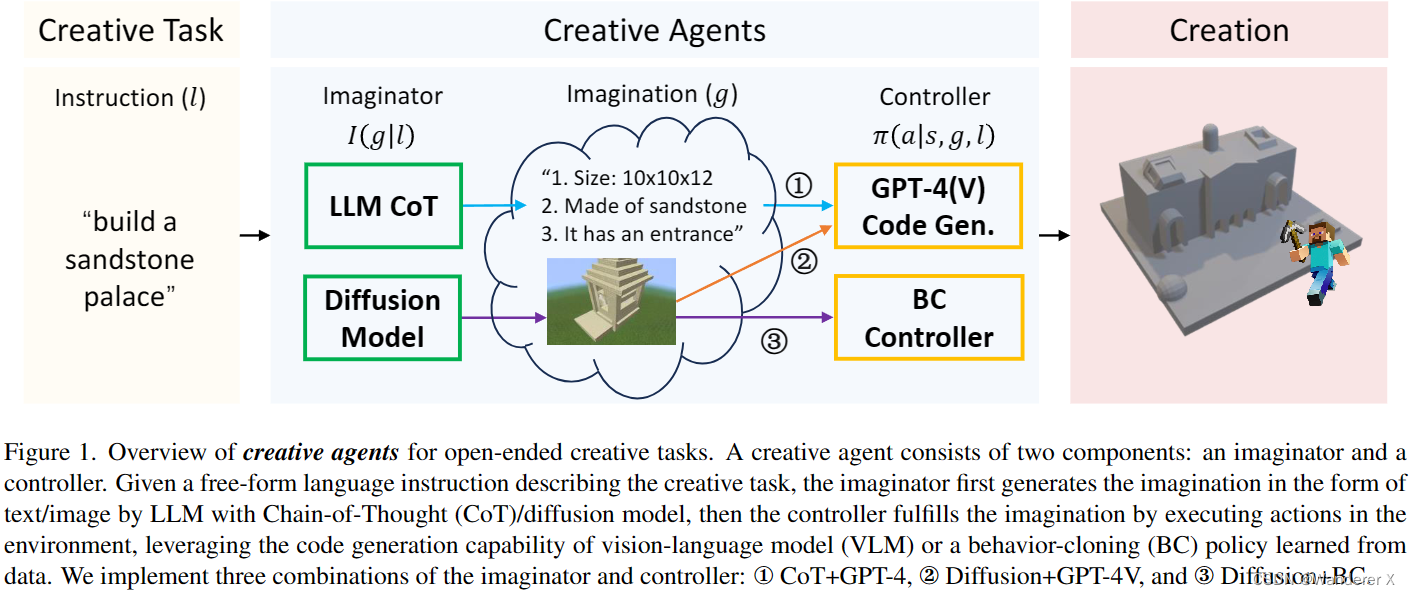
开放式创意任务的创意代理概述。创造性代理由两个部分组成:想象者和控制者。给定描述创造性任务的自由形式的语言指令,想象者首先通过具有思维链(CoT)/扩散模型的LLM以文本/图像的形式生成想象,然后控制器利用视觉语言模型(VLM)的代码生成能力或从数据中学习的行为克隆(BC)策略,通过在环境中执行动作来实现想象。我们实现了三种想象器和控制器的组合:①CoT+GPT-4,②Diffusion+GPT-4V,③Diffusion+BC。
Imginator
用语言模型实现文本空间的想象(LLM CoT):这种方法利用大语言模型GPT-4的文本推理能力,以文本形式生成对任务细节的想象。作者利用思维链推理(Chain-of-Thought),在提示词中设计与任务细节相关的五个问题(如下所示),要求GPT-4想象建筑不同方面的特征。
用扩散模型(Diffusion Model)实现图像空间的想象:在图像生成领域,扩散模型能够基于文本生成高质量、多样的图像,可以作为想象模块生成目标建筑的视觉形态,比文本形式的想象具有更丰富的细节。作者收集整理了14K带有语言描述的Minecraft建筑图像数据集,微调Stable Diffusion[3]模型,实现了从语言指令生成真实的Minecraft建筑图像。
Controller
基于模仿学习的控制器(BC Controller):对专家行为的数据集做模仿学习是训练控制器的常用做法。作者在Minecraft建造任务上实现了一种分为两步的模仿学习控制器:首先收集了1M成对的建筑图像和建筑的3D体素数据集,通过训练Pix2Vox++模型,将想象模块生成的图像转换为建筑的蓝图(即3D体素);然后,作者收集了6M个在游戏中建造目标建筑体素的专家动作,用模仿学习得到了根据目标体素规划动作序列的控制器策略。
基于大模型生成代码的控制器(GPT-4(V) Code Gen.):这个方法利用大模型GPT-4(V) 任务推理和写代码的能力,将底层控制转化为生成代码的问题。使用Mineflayer提供的对Minecraft中基本动作的封装,作者将文本/图像形式的想象输入给GPT-4(V),要求生成代码调用Mineflayer的接口、在游戏中创造相应建筑。
variants
• Vanilla GPT-4. This is the baseline method without imagination using GPT-4 as the controller. We simply replace the textual imagination with the original task instruction and ask GPT-4 to perform code generation.
• CoT+GPT-4. We implement this agent by adding a CoTimagination on the basis of Vanilla GPT-4, which means we use GPT-4 for both textual imagination and code generation (method ① in Figure 1).
• Diffusion+GPT-4V2. We use a finetuned Stable Diffusion to generate images as imagination and use GPT-4V as the controller to generate codes based on the visual imagination (method ② in Figure 1).
• Diffusion+BC. The finetuned Stable Diffusion is used as the imaginator while the behavior-cloning controller is used to convert images into voxel blueprints and execute actions.(method ③ in Figure 1).
Results
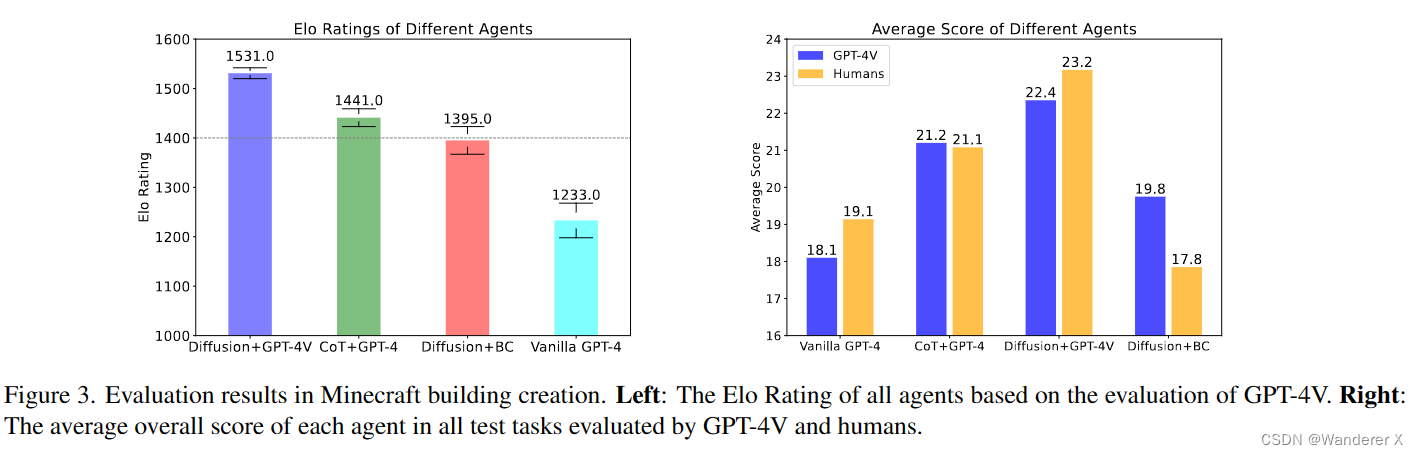
Diffusion+GPT-4V 在视觉想象和 CoT 的优势方面都具有优势,因此具有更好的性能。














 1558
1558











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









