







写在开头:本文的写作值得学习,实验极其详尽。本篇博文按照作者的写作思路过一遍摘要和引言,对于我们大多数人写文章按照这个套路都没什么问题。
摘要
切入点:鲁棒性和判别性都很重要
现有问题:孪生网络无法判别性的建模目标和干扰
提出新方法:target-dependent feature network
做法:通过 attention,将跨图像的特征相关性嵌入特征网络的多个层中。
好处:
- 在多个层进行匹配,压制非目标特征,得到实例感知的特征提取;
- 输出的搜索特征可以直接用于预测定位,无需互相关操作;
- 可以在大量不成对数据上预训练,加速收敛
引言
指出跟踪中两个竞争的需求:1. 在剧烈形变下识别目标(鲁棒性);2. 区分目标和背景干扰物(判别性)
当前方法:提取更具有表达力的 Siamese 特征;设计更鲁棒的相关操作。
当前方法的问题:很少注意到两个竞争的需求会使得网络陷入目标 - 干扰物困境,主要体现在三个方面
-
Siamese 特征编码过程无法感知 template 和 search 中的的实例级信息
-
backbone 没有明确建模区分两个竞争的决策边界,陷入次优结果
-
每个训练视频只标注一个目标,但是跟踪过程中为包含干扰物的任意目标。这个差距进一步扩大了问题 2
本文观点:特征提取应该具有动态感知实例变化的能力,为跟踪生成适当的 embeddings。具体包括:为视频中的同一对象生成连贯的特征,以及对具有相似外观的目标和干扰物生成对比特征
本文提出方法:
一个基于注意力的动态特征网络 Single Branch Transformer (SBT) network,允许模板和搜索图像的特征在特征提取的每个阶段进行深度交互。
如图 2 所示,传统的孪生网络堆叠卷积,最后接一个互相关层进行特征交互。而 SBT 堆叠注意力模块 Extract-or-Correlation (EoC) blocks,其中 EoC-SA 融合同一图像的特征,EoC-CA 交互模板和搜索图的特征。最后将搜索图像特征直接输出给预测头。
直观地,交叉注意力逐层过滤掉与目标无关的特征,自注意力增强了目标的特征表示。由于特征提取过程是 target-dependent 且非对称的,因此 SBT 将目标和干扰物进行区分的同时保持不同目标之间的连贯特征。如图 2d 所示,属于目标的特征 (绿色) 与背景 (粉色) 和干扰物 (蓝色) 越来越分离,而孪生网络提取的搜索特征是 target-unaware 的。

关键创新
为模板和搜索图像对的处理引入一个单一流,通过注意力模块联合特征提取和特征关联。
SBT 本质上还是一个特征提取的 backbone,因此可以在 ImageNet 等非成对数据上进行预训练,在跟踪数据中微调快速收敛。
方法

整体结构如图 3 所示,包含三个 stage。前两个 stage 通过 patch embedding 降维,后面接自注意力 EoC-SA;第三个 satge 交替使用自注意力 EoC-SA 和交叉注意力 EoC-CA。该框架没有额外的互相关层,通过在在网络的不同阶段使用交叉注意力实现了信息交互融合。最后将融合后的搜索特征直接输入预测头做分类和回归。
Patch Embedding
使用 7×7 步长为 4 的卷积 + LN 层,降低空间分辨率。
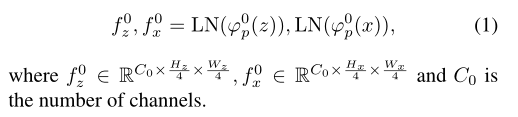
Extract-or-Correlation Block
EoC 模块如图 3b,c 所示,包括两个 LN 层一个 MLP 层以及一个注意力,注意力包含自注意力 (SA) 和交叉注意力 (CA).。SA 输入的 ij 是同源的,CA 输入的 ij 分别来自模板 z 和搜索图 x。

作者为了计算高效,尝试了 Vanilla Global attention (VG);Spatial-Reduction Global attention (SRG),对 k,v 降分辨率;Vanilla Local window attention (VL) ,计算局部块的注意力;Shift window vanilla Local attention (SL),即 Swin Transformer。最后使用 SRG。

Spatial-Reduction Global attention(SRG)
Position Encoding
尝试了绝对 / 相对位置编码,和 CVPT 中的条件位置编码,即一个 3×3 的 depth-wise 卷积。
Direct Prediction
分类和回归分支均由两个 MLP 层构成,分别在空间维度和通道维度
做 MLP,其中 RS 表示 reshape。

SBT 设计准则
作者做了大量实验来探究如何设计网络框架,每张实验图里都包含大量信息,微软有卡任性。这里只总结结论,具体实验可以参考原文。


- 多尺度分层结构的性能比单级结构好 (表 1 setting A)
- 不同位置编码影响不大 (表 1 setting A)
- 卷积得到的 patch embedding 比手工划分的更具表现力 (表 1 setting A)
- 全局注意力 SRG 效果和效率综合最佳 (表 1 setting A)
- EoC-CA 越多一定范围上可以提升性能 (图 4d)
- 越早使用 EoC-CA 生成与目标相关的特征越好,但是放在太前面如 stage1,2 的计算开销较大,而带来的提升较小(图 4d,b)
- 交替使用 EoC-SA 和 EoC-CA (图 4f)
- 浅层 stage1 和 2 不要设置过多参数和计算量(表 1 setting B)
- 网络步长一定,3 个 stage 比 4 个 stage 好(表 1 setting B)
- 空间分辨率越大,性能越高,但计算量大(表 1 setting B)
- 平衡 block 的数量和 channel 维度(表 1 setting B)
- SBT 可以通过预训练中受益,比基于 transformer 的跟踪器(如 transt,stark)收敛得更快(图 4e)
SBT 跟踪的理论分析
- SBT 克服了孪生跟踪器平移不变性的限制
padding 破坏平移不变性,而对于 SBT,padding 只存在于 PaE 中,attention 没有引入 padding。此外,attention 的 token 本身就具有排列不变性,即目标在图像上移动多少,则其所在的 token 也移动同样的距离。
- 交叉注意力相当于执行了两次互相关

- 在串行管道中嵌入了分层特征利用
经典的孪生跟踪器如 SiamRPN++ 是并行的的分层聚合,即对多个特征分别做互相关再叠加。SBT 探索了串行的多层次的特征相关性,即将前一层相关(交叉注意力)的输出送给下一次相关的输入。


4 种 SBT 网络

Imagenet 预训练用 4 个 stage,跟踪微调只用前 3 个 stage。
实验
Comparison to State-of-the-Art Trackers


作者将本文提出的 Correlation-Aware backbone 用在几个主流的跟踪器上,得到 SiamFCpp-CA. DiMP-CA.STARK-CA. STM-CA,观察性能提升巨大,甚至部分计算量还下降了。

Exploration Study


Correlation-embedded structure 将特征交互嵌入特征提取中的效果比单独在最后使用互相关效果要好。并且本文使用的交叉注意力的交互形式比 DCF 和 DW-Corr 要好。

Target-dependent feature embedding (a) Correlation-embedded tracker. (b) Siamese correlation with SBT. (c) Siamese correlation with ResNet-50
本文提出的方法最具有 target-dependent 的性质,即目标和干扰分的最开。

Benefits from pre-training 本文的方法可以预训练,提升性能加速收敛。
补充材料里还有一些关于计算量和结构设计方面的实验,就不一一介绍了。作者团队是真的有耐心做了这么多对比实验。


最后提下本文方法的局限性,就是对严重遮挡或者出视野不友好,这也是所有孪生跟踪器的通病了。虽然 attention 的逐点匹配一定程度上可以克服遮挡,但是对于图 13 中这些有相似属性的遮挡物还是存在很多误判。另一个局限在于本文使用了很多快速注意力,这些并不能直接通过直接调包实现。

结论
本文首次提出了一种 target-dependent 的跟踪特征网络。SBT 大大简化了跟踪管道,比最近基于 Transformer 的跟踪器收敛更快。从实验和理论两方面对 SBT 跟踪进行了系统的研究。此外,实现了四个版本的 SBT 网络,可以改进其他流行的 VOT 和 VOS 跟踪器。大量实验表明,该方法取得了良好的效果,可以作为动态特征网络应用于其他跟踪管道。















 708
708

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









