






1、体系结构
1、连接层 : tcp/ip、udp等
2、服务层 :
解析器 : 2.1、词法解析 --> 把sql解析成一个解析树
2.2、语法解析 --> sql是否关键字是否写错
预处理器: 处理表是否存在、解析 *号
优化器: 生成最小的开销执行计划
执行计划: 可以通过explain 查看执行计划(这里只生成执行计划,不跟引擎关联,所以执行
计划很快),你建立的索引不一定会走索引,有建立的索引可能还走全表扫描.
引入概念:散列度 count(hvg(xx))
存储引擎 : 存储那个表?及有谁去执行
3、存储引擎层 : 执行引擎 -- 调用对应的api,如下图
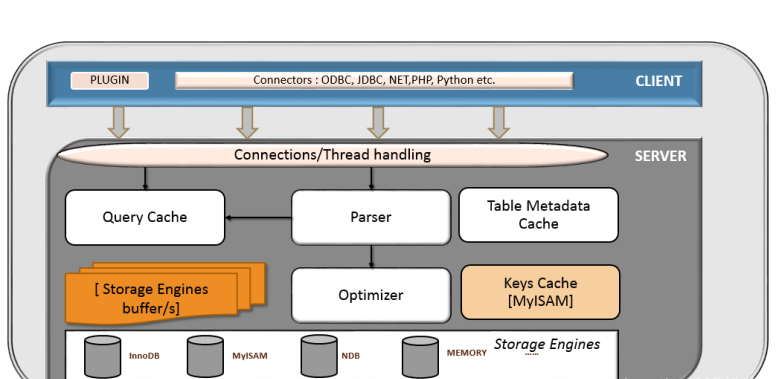
2、存储引擎

重点说下Myisam和innodb的索引:
Myisam的索引文件和数据文件是分离的,索引文件是存放数据文件的一个地址。
而innodb的索引文件本身就保存了数据完整的data。
3、InnerDB架构
1、内存结构
1.1、Buffer Pool --> a、Buffer Pool
存储页数据,索引等
预读数据:当select的时候,不是只读取where条件后的数据,会预加载数据
到Buffer Pool中,
Buffer Pool 有大小限制(根据mysql配置),分为了冷热数据,
比例3:5,也是根据lru算法来的,get了数据,数据放在前面
b、Change Buffer -- > 写缓冲,节省随机获取磁盘IO
1.2、Adaptive Hash Index : 哈希索引
1.3、Log Buffer: a、redo Log刷盘时机 --> 1、延迟写
2、适时写
3、每秒写
4、刷盘越快,消耗的性能越高
b、Log Buffer作用 --> 记录redo log写入缓冲区
2、磁盘结构
2.1、系统表结构
a、数据字典:存储表与索引的元数据
b、双写缓冲区:redo备份、系统一页4k,而innerdb一页16K,需要写4次才完成一页写入
宕机后, 存在刷脏,需要通过
c、change buffer
d、undo log :记录数据修改前的内容、回滚
2.2、通用表空间
2.3、临时表空间
2.4、redo log :保存的是修改后的数据;在执行更新造作都是在内存中进行,假如:断电了,或者mysql宕机了;redo log buffer就会慢慢的刷新到磁盘中。
2.5、bin log : 记录所有DDL跟DML语句、做删库恢复, 先有bin log 后有redo log
3、隐藏字段?
3.1、DB_ROW_ID 6字节:行标识
3.2、BD_TRX_ID 6字节:插入或更新的最后一个事务的事务ID,自动递增(创建版本号)
3.3、DB_ROLL_PTR 7字节:回滚指针(删除版本号)指向undo log里的内容
4、redo log、redo log buffer、binlog、undo log之间的配合
更新操作都是在内存中完成;
一条更新的前世今生。
update test set name = '张三' where id = 1;
1、首先会判断是不是buffer pool有这条数据;
2、如果没有,就查询表加载到buffer pool中
3、在buffer pool中更新数据
4、在更新的时候,把旧数据存放到undo log
5、把更细后的数据存放到redo log中。中间还有一个redo log buffer
6、在更新redo log中成功后,在更新到bin log中。
7、在事务commit后,标记redo log为commit;在fasync() 刷盘操作
流程图:

8、为什么需要redo log
为mysql宕机、断电等丢失数据做的carch safe。防止数据丢失。redo log是innodb特有的
9、为什么需要redo log与bin log两段提交
假如:先redo log commit了。但是在写bin log的时候宕机了。如果有主备数据库,cluster库同步不到这条数据了,主备数据不一致了。
假如:先bin log先commit了。在写redo log宕机了。如果有主备数据库,cluster库就会被更新到了,但是主库宕机了,主库的数据没被commit,就会主备数据内容不一致。
4、索引
4.1、存储模型
a、红黑树:不够平衡,只有两路,存在哈希到同一位置,而且深度不可控
b、哈希:不是顺序存储、不能排序;哈希冲突,不能范围查找
c、B树:分叉树多、深度小(深度可控,可配置);叶子节点存储的是数据; 新增记录、修改记录导致
索引分裂和合并
d、B+树: 分叉树多、深度小;分叉节点存放的是索引; 读写更强、一次io读取更多的关键字;
叶子节点存放数据,而且每个月节点还存放的前后页的指针,做全表扫描更快;
假设一个索引的存储是16bytes/,一个页可以存储16K, 16k/16bytes = 1000
假设深度是2,那么两层可以放 1000 ^ 2 = 1千万个指针
4.2、索引存储文件
a、InnerDB:表结构.frm、索引文件.ibd
b、聚集索引:索引键值的逻辑顺序跟表数据行的物理存储顺序一致(主键),如果不设置主键,InnerDB默认会
生成一个6byte的rowid
c、非聚集索引: 分叉节点上data存储的是主键, 这里为什么不存储地址,因为主键是不会变的,但是记录
会update,导致索引被更改,导致可能分裂和聚合, 所以这里会产生"回表"io
d、索引选举: 可以根据索引的散列度来选取,散列度越高,说明越适合建立索引(不是绝对的).
e、覆盖索引: 返回字段内容与where条件(都有索引)一直
f、联合索引:
g、索引下推:select存储引擎上的内容,mysql会自动把where上有索引的条件做条件查询。
5、事物
5.1、四大特性
a、原子性 : 要么执行成功,要么全部不执行
b、隔离性 : 每个事物都是一个执行单位,互相不干扰
c、持久性 : crud的数据,提交成功都是永久性的(落地到磁盘)
d、一致性 : 执行事物后,数据保持一致
5.2、隔离级别
a、RU : 读未提 --> 读到未提交的数据 (脏读)
b、RC: 读已提-- > 读到未提交新增的数据(幻读),解决了脏读, 解决update操作
c、RR : 不可重复读 --> 解决了幻读,通过MVCC和锁解决 解决insert操作
d、串行: 锁全表?好像不是,是锁一个范围。有待验证
5.3、隔离利弊
5.4、一致性问题?
当前读和快照读
什么是当前读:
像select lock in share mode(共享锁), select for update ; update, insert ,delete(排他锁)这些操作都是一种当前读,为什么叫当前读?就是它读取的是记录的最新版本,读取时还要保证其他并发事务不能修改当前记录,会对读取的记录进行加锁
什么是快照读
像不加锁的select操作就是快照读,即不加锁的非阻塞读;快照读的前提是隔离级别不是串行级别,串行级别下的快照读会退化成当前读;之所以出现快照读的情况,是基于提高并发性能的考虑,快照读的实现是基于多版本并发控制,即MVCC,可以认为MVCC是行锁的一个变种,但它在很多情况下,避免了加锁操作,降低了开销;既然是基于多版本,即快照读可能读到的并不一定是数据的最新版本,而有可能是之前的历史版本
MVCC是为了实现读写且不阻塞情况,实现数据隔离。
a、MVCC
a.1、 生成与数据一致的(read view), 通过比较事物id,比当前事物小(trx_id),本事物的修改,
可以读取,大于当前事物id,访问不到
a.2、在同一个事物无论查操作多少次,数据都是一直的
a.2、在同一个事物有dml操作,查询已修改的数据
a.3、不在同一个事物无论操作什么,如果后与快照的事物,数据还是快照中的数据
a.4、这里很好的解决insert带来的重复读带来的问题, 但是这里只针对于RR,RC还是未能解决,RR是在事务开始后,第一次select操作才会快照一次。而RC因为同一个事物每次select,都是生成新的read view (快照)
b、LBCC
b.1、在修改操作前加锁 ,阻止其他事物对其修改,读多写小情况,影响效率
5.5、MVCC下,RR与RC区别。
每个表都自动隐藏了三个字段
■1、_rowsid: 行号
■2、trx_id 事务id,插入或修改都会记录改行的事务id
■3、roll_ptr 回滚指针,指向undo_log, 插入或者修改就会记录上一次的修改记录。
| _row_id | trx_id | roll_ptr | 操作 |
| 1 | 1 | null | 插入的数据,没有上一次的undolog操作,所以为空 |
| 2 | 4 | yyy | 上一次的操作记录为null在undo_log |
| 3 | 6 | xxx | 上一次的操作记录为yyy在undo_log |
5.6.1、RR与RC隔离核心机制
●核心的逻辑:就是判断那些事务版本是当前事务可见的,针对这块inndb增加Readview(快照)。而Readview是把所有的活跃事务放在一个列表中。称为:m_ids。RR是在事务开始后,第一次select操作才会快照一次。
●而RC因为同一个事物每次select,都是生成新的read view (快照)
●活跃事务列表:在这个列表中都是未执行完成的事务,如:比当前执行事务的id大,那说明还未执行,那么相对当前事务来说,是不可见的。
●trx_id:在生成当前Readview(快照)当前行的记录事务id
●creator_trx_id: 生成Readview的事务id
●行记录:
○当行记录的记录的事务,与Readview的事务id相等,说明是本事务操作,可见
○当行记录的记录的事务,比Readview的活跃事务id任务都要打,说明当前行记录的事务还未提交,是不可见的。
○当行记录的记录是否存在活跃事务列表中,还未提交,那么不可访问。如果不存在活跃事务列表中,说明已经提交了。可以访问。
○
5.6.2、为什么默认数据是RR,但是更多互联网选择RC?
binlog格式介绍:
1statement:保存执行的sql语句。 (在5.0以前,只有这种格式)。优点:产生日志文件小,io少 ;缺点:master上执行的sql,在slave还会在执行一次。在设置隔离级别是RC情况下,会存在主从数据不一致的情况。
2row:binlog记录每行的实际变更记录。优点:准确度高,master是什么数据,slave就是什么数据。变更修改过 的数据; 缺点:日志文件大,磁盘io压力大。从性能上来看略低。
3mixed:statement及row的混合物;混合statement、row的优点及确定。
历史原因:在mysql5.0上,那时候的binlog的格式只有statement格式。
如图所示:

描述:
在通过select * from test where id < 6;
在master节点上查询,结果id=4被查询出来;
通过如上顺序:事务1先开启删除,在事务2插入。顺序是:先删除后插入;
但是从binlog上执行来解释:是插入在删除,因为事务2先commit;
所以以上情况上,会导致主从不一致情况;RC情况下,防止不了insert操作。而RR出mvcc快照是读一次;而且RR还有间隙锁的情况。所以为什么在mysql5.0情况下,默认会是用RR操作。
目前mysql谁知binlog_format更多是使用Row格式。这种情况不会存在主从数据不一致情况。
而且数据本身来说,已经提交了。只是第一次,第二次查询时间不同情况,数据不一致上也是可以接受。数据最终一致性,所以要看业务定义;如果接受不了主从带来的问题。那么可以在读写都使用主库查询。
6、锁
6.1、锁类型
a、基础模式
1.1、 行锁
1.1.1、 共享锁: 不同的事物共享一把锁,只读不可以写
1.1.2、 排他锁:一个事物获取到了排他锁,其他事物不能操作这条记录(增删改默认增加排他锁); 如果查下需要加则结尾加上 for update
2.1、表锁
2.1.1、 意向共享锁:事物准备对数据行加共享锁,需要获取意向共享锁的is锁
2.1.2、 意向排他锁: 事务准备给数据行加入排他锁,一个数据行加排他锁前必须先取得该表的IX锁
2.1.3、 意向锁是数据引擎自动加的,无需我们来操作
b、锁范围
b.1、记录锁 : 只锁一条记录 select ...for update
b.2、间隙锁:锁点范围 (0,5),(5,10) ,列如:select... where id > 2 and id <7 for update,那么
锁定范围0-10 ,在RR级别中存在
b.3、临界锁: 边界值是包含[0,5],[5,10],[10,15] ,包含边值
b.4、锁定范围后,目的是为了防止插入
c、锁的是什么? --> 锁住的是索引
6.2、锁粒度
a、InnerDB支持表锁、行锁;Myisam只支持表锁
b、锁定力度:表锁大于行锁
c、加锁效率:表锁小于行锁
d、冲突概率:表锁大于行锁
e、性能:表锁小于行锁
6.3、隔离级别的实现
` a、RU:没有
b、串行:所有的语句隐式加上了共享锁
c、RC : 查询 --> MVCC(不知道卵用在哪里?); DML: 记录锁
d、RR : 查询 --> MVCC;DML:记录锁,间隙锁,临界锁
6.4、如果选择?
a、RR间隙锁范围大,可能导致锁定的范围大
b、条件未使用索引,锁表,锁行
6.4、死锁的产生和预防
a、产生原因:
a.1、资源互斥
a.2、不能强制剥夺
a.3、形成循环等待
b、预防
b.1、顺序执行
b.2、申请到够级别的锁
b.3、where条件增加能命中索引的条件
b.4、能等值查询就用等值,范围锁定的记录更多
7、驱动
mysql5用的驱动com.mysql.jdbc.Driver
mysql6用的驱动com.mysql.cj.jdbc.Driver,增加了时区
8、mysql命令
8-1、隔离级别
●SELECT @@global.tx_isolation;
●SHOW VARIABLES LIKE 'tx_isolation';
8-2、最大设置连接数
●SHOW VARIABLES LIKE 'max_connections';
●show variables like '%max_user_connections%' -- 单个用户最大连接数,设置0,表示不限制。
8-3、当前连接数
show status like 'Threads%';
Threads_cached 471 线程缓存
Threads_connected 75 当前连接数量
Threads_created 814 已创建过的连接数量
Threads_running 2
8-4、最大连接超时时间
●SHOW VARIABLES LIKE '%connect_timeout%';
8-5、存放目录
●show variables like 'datadir'
8-6、端口
●show variables like 'port'
8-7、引擎
●show variables like '%storage_engine%'
8-8、暂存连接数
●show variables like '%back_log%' ;表示连接数能最大的暂存数量;当连接数达到了max_connections时,就会把连接暂存;超过back_log的设置,则拒绝连接。
8-9、表关联缓存大小
当 MySQL 执行一个联接查询时,它需要将两个或多个表中的数据进行匹配。为了提高连接操作的性能,MySQL 会将其中一个表中的数据先读入缓存中,然后在缓存中执行连接操作,而不是每次都从磁盘读取数据默认情况下:
●show variables like '%join_buffer_size%'
8-10、inndb缓存区大小
●SHOW VARIABLES LIKE '%innodb_buffer_pool_size%';
8-11、排序缓冲大小
●SHOW VARIABLES LIKE '%sort_buffer_size%';
若有收获,就点个赞吧















 9万+
9万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









