







Description
艾利斯顿商学院篮球队要参加一年一度的市篮球比赛了。拉拉队是篮球比赛的一个看点,好的拉拉队往往能帮助球队增加士气,赢得最终的比赛。所以作为拉拉队队长的楚雨荨同学知道,帮助篮球队训练好拉拉队有多么的重要。拉拉队的选拔工作已经结束,在雨荨和校长的挑选下,
n
位集优秀的身材、舞技于一体的美女从众多报名的女生中脱颖而出。这些女生将随着篮球队的小伙子们一起,和对手抗衡,为艾利斯顿篮球队加油助威。一个阳光明媚的早晨,雨荨带领拉拉队的队员们开始了排练。
Input
输入为标准输入。第一行为两个正整数
Output
输出为标准输出。输出一个整数,代表题目描述中所写的乘积除以19930726的余数,如果总的和谐小群体个数小于
K
<script type="math/tex" id="MathJax-Element-49">K</script>,输出一个整数-1。
Sample Input
5 3
ababa
Sample Output
45
样例说明
和谐小群体女生所拿牌子上写的字母从左到右按照女生个数降序排序后为ababa, aba, aba, bab, a, a, a, b, b,前三个长度的乘积为。
HINT
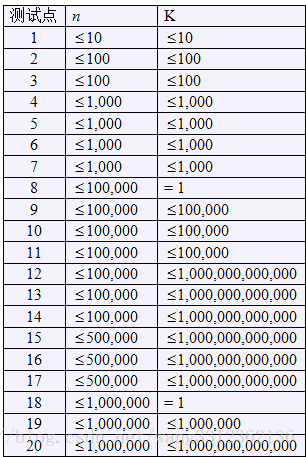
总共20个测试点,数据范围满足:
Source
#include <cstdio>
const int maxn=1000000;
const int mo=19930726;
int n,p[maxn+10],id,rmax;
long long ans=1,k,sum[maxn+10];
char s[maxn+10],a[maxn+10];
long long quickpow(long long a,long long b,int mo)
{
long long res=1;
while(b)
{
if(b&1)
{
res=res*a%mo;
}
b>>=1;
a=a*a%mo;
}
return res;
}
int main()
{
scanf("%d%lld%s",&n,&k,s+1);
a[0]='!';
for(register int i=1; i<=n; ++i)
{
a[i]=s[i];
}
a[n+1]='*';
p[1]=id=rmax=1;
for(register int i=2; i<=n; ++i)
{
if(rmax<i)
{
p[i]=1;
}
else
{
if(p[(id<<1)-i]<rmax-i)
{
p[i]=p[(id<<1)-i];
}
else
{
p[i]=rmax-i;
}
}
while(a[i-p[i]]==a[i+p[i]])
{
++p[i];
}
if(i+p[i]-1>rmax)
{
rmax=i+p[i]-1;
id=i;
}
}
for(register int i=1; i<=n; ++i)
{
++sum[1];
--sum[p[i]<<1|1];
}
for(register int i=3; i<=(n|1); i+=2)
{
sum[i]+=sum[i-2];
}
for(register int i=n|1; i>=1; i-=2)
{
if(k<=sum[i])
{
ans=ans*quickpow(i,k,mo)%mo;
k=0;
break;
}
else
{
k-=sum[i];
ans=ans*quickpow(i,sum[i],mo)%mo;
}
}
if(k>0)
{
puts("-1");
return 0;
}
printf("%lld\n",ans);
return 0;
}














 395
395

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









