







#coding=utf-8
#加载必要的库
import numpy as np
import sys,os
#import caffe
#设置当前目录
caffe_root = '/mnt/caffe/'
sys.path.insert(0, caffe_root + 'python')
import caffe
os.chdir(caffe_root)
net_file=caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt'
caffe_model=caffe_root + 'data/ilsvrc12/bvlc_reference_caffenet.caffemodel'
mean_file=caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy'
net = caffe.Net(net_file,caffe_model,caffe.TEST)
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
transformer.set_raw_scale('data', 255)
transformer.set_channel_swap('data', (2,1,0))
im=caffe.io.load_image(caffe_root+'examples/images/cat.jpg')
net.blobs['data'].data[...] = transformer.preprocess('data',im)
out = net.forward()
imagenet_labels_filename = caffe_root + 'data/ilsvrc12/synset_words.txt'
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t')
top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i], labels[top_k[i]]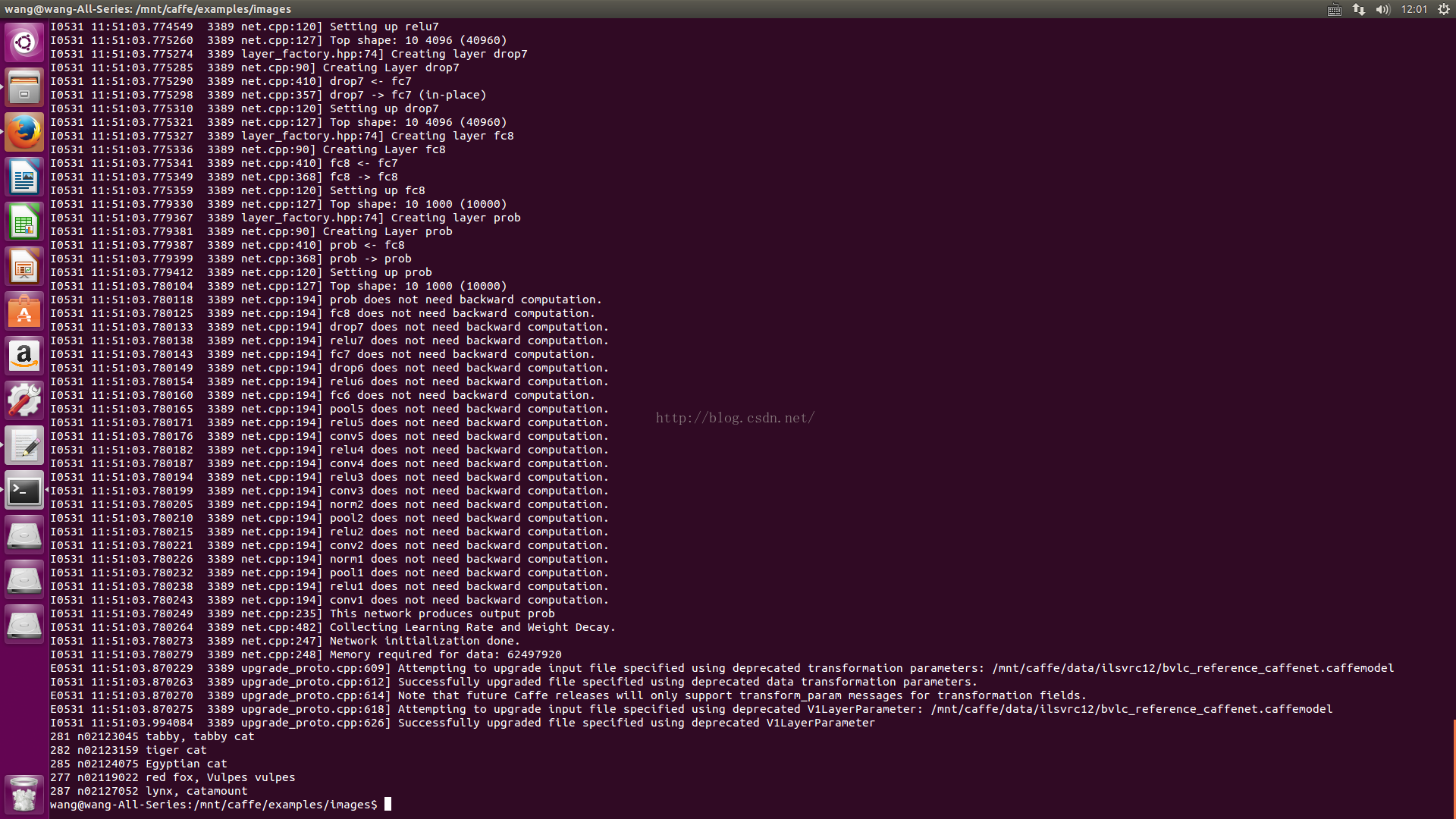
结果输出排名前五的图像概率。如图~














 3413
3413











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









