







Unsupervised Domain-Specific Deblurring via Disentangled Representations
写在最前面:主要是对阅读的文献记录一下,博文书写主要参考推文点我
1.概述
这是一篇2019CVPR的文章。
在本文中,主要提出了一种基于解缠结表示的域特定单图像去模糊的无监督方法。通过分割内容来实现解开使用内容编码器和模糊图像模糊功能模糊编码器。同时,来处理不成对的训练数据,模糊的分支和添加循环一致性损失以保证去模糊结果的内容结构与原始图像匹配。我们还在deblurred上添加了对抗性损失结果产生视觉上逼真的图像和感知损失,以进一步减轻伪影。
也就是说,提出了一种基于解缠表示的无监督域特定图像去模糊方法,通过将模糊图像中的内容和模糊特征解开,以将模糊信息准确地编码到去模糊框架中。
背景
大多数传统方法将图像去模糊任务公式化为模糊核估计问题,在过去的十年中,已经开发了各种自然图像和先验核来规范潜在锐利图像的解空间,包括重尾梯度先验,稀疏核先验,梯度先验,归一化稀疏性和暗通道。
然而,这些先验是通过有限的观察来估计的,并且不够准确。结果,去模糊的图像通常欠去模糊(图像仍然模糊)或过度去模糊(图像包含许多伪像)。
近年来深度神经网络和 GAN 的巨大成功,已经提出了一些基于 CNN 的方法用于图像去模糊,例如 Nimisha 在 ECCV 2018 发表的 Unsupervised Class-Specific Deblurring 是一种基于 GAN 的无监督图像去模糊方法,在模型上增加了重复损失和多尺度梯度损失。虽然它们在合成数据集上取得了良好的性能,但它们对一些真实模糊图像的结果并不令人满意。
另一类方法是基于现有的图像到图像的模型,例如 CycleGAN [2] 这类无监督端到端的模型,然而,这些通用方法通常编码其他因素(例如:颜色、纹理)而不是将信息模糊到发生器中,因此不会产生良好的去模糊图像。
创新
1、内容编码器和模糊编码器将模糊图像的内容和模糊特征区分开,实现了高质量的图像去模糊;
2、对模糊编码器添加 KL 散度损失以阻止模糊特征对内容信息进行编码;
3、为了保留原始图像的内容结构,在框架中添加了模糊图像构造和循环一致性损失,同时添加的感知损失有助于模糊图像去除不切实际的伪像。
2.实现
网络框架

由于模型的循环一致性设计,网络的左右是基本对称的。
其中,s 代表清晰的真实图像,b 代表模糊的真实图像,Ecs是清晰图像的内容编码器(可以理解为图像颜色、纹理、像素的编码器),EcB对应的是模糊图像的内容编码器,Eb是模糊图像的模糊编码器(仅用来提取图像的模糊信息),GB是模糊图像生成器,Gs是清晰图像生成器,bs是生成的模糊图像,sb是生成的清晰图像。经过循环的转换,ŝ 是循环生成的清晰图像,b̂ 是循环生成的模糊图像。
实现思路:
由模糊图像去模糊到清晰图像的过程中,将模糊图像内容编码和模糊编码送入清晰图像生成器重构得到去模糊的清晰图像,清晰图像到模糊图像是为了优化模糊编码和模糊图像的内容编码的作用。通过循环一致性,进行进一步的还原保证模型的鲁棒性。核心的损失是图像生成在 GAN 的对抗损失,结合感知损失达到图像下一些伪影的优化。
具体:
模糊编码器的设计,它主要的作用是用来捕获模糊图像的模糊特征,
作者采用了迂回的思路,既然清晰的图像是不含模糊信息的,如果清晰的图像通过结合模糊编码器模糊特征去生成出模糊图像,是不是可以说,模糊编码器是在对清晰图像做模糊化处理,这个模糊化的前提是什么?那就是模糊编码器确实提取到了图像的模糊特征,所以说由清晰图像生成模糊图像也保证了模糊编码器是对图像的模糊信息进行编码的作用。
同时,由清晰图像到模糊图像的生成过程中,清晰图像的内容编码器我们是有理由相信它是提取到了清晰图像的内容信息(因为清晰图像并不包含模糊信息)。
文章为了保证模糊图像的内容编码器是对模糊图像的内容进行编码,文章将清晰图像内容编码器和模糊图像内容编码器强制执行最后一层共享权重,以指导学习如何从模糊图像中有效地提取内容信息。
为了进一步尽可能多地抑制模糊编码器对内容信息的编码,通过添加一个 KL 散度损失来规范模糊特征的分布,使其接近正态分布 p(z)∼N(0,1)。这个思路和 VAE 中的限制数据编码的潜在空间的分布思路是相近的,这里将模糊编码器的编码向量限制住,旨在控制模糊编码器仅对图像的模糊信息进行编码。
3.损失函数
KL散度损失:
首先是对模糊编码的隐空间分布进行约束,这个约束通过 KL 散度去实现,这个过程和 VAE 的思路是一致的:
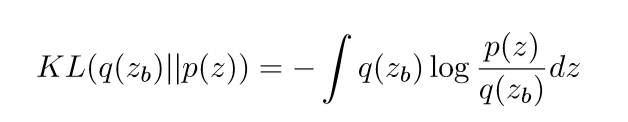
这里的 p(z)∼N(0,1),具体的损失可进一步写为:
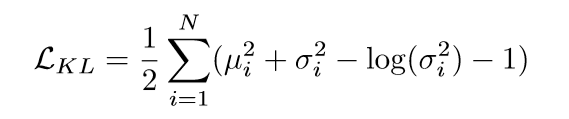 zb 可表示为 zb=μ+z∘σ
zb 可表示为 zb=μ+z∘σ
GAN的对抗损失:
清晰图像: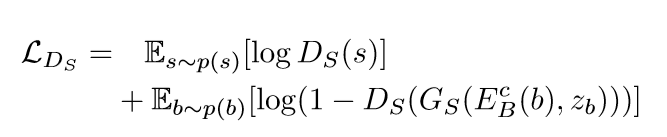
模糊图像:
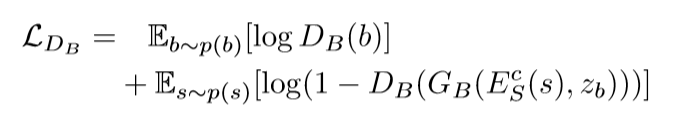
循环一致性损失
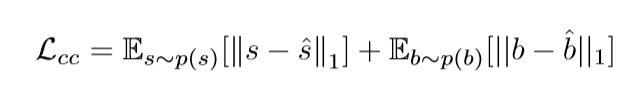
感知损失
加在预训练 CNN 的第 1 层的特征,实验中加在 ImageNet 上预训练的 VGG-19 的 conv3,3。
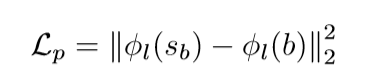
总的损失
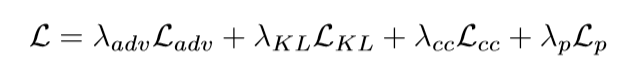
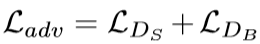
测试
给定一个测试模糊图片bt,EcB提取图片内容,Eb提取模糊特征,GS生成去模糊图像sbt:
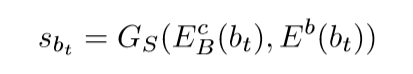
4.实验
文章的网络的设计结构:
参考了 Diverse image-to-image translation via disentangled representations [3]。内容编码器由三个卷积层和四个残差块组成。模糊编码器包含四个卷积层和一个完全连接的层。
对于发生器,该架构与内容编码器对称,具有四个残差块,后面是三个转置的卷积层。判别器采用多尺度结构,其中每个尺度的特征图经过五个卷积层,然后被馈送到 sigmoid 输出。
采用 Adam 优化损失,对于前 40 个时期,学习速率最初设置为 0.0002,然后在接下来的 40 个时期使用指数衰减。超参上 λadv=1, λKL=0.01, λcc=10, λp=0.1。
实验数据集采用三种数据集:
CelebA 数据集,BMVC 文本数据集和 CFP 数据集。
CelebA 数据集包含超过 202,000 个面部图像,文章设置了清晰图像 100k,模糊图像 100k,测试图像 2137。BMVC 文本数据集由 66,000 个文本图像组成,分配方式类似于 CelebA 数据集。CFP 数据集由来自 500 个主题的 7,000 个静止图像组成,并且对于每个主题,它具有正面姿势的 10 个图像和具有专业姿势的 4 个图像。
对于 CelebA 和 BMVC Text 数据集,我们使用标准的 debluring 指标(PSNR,SSIM)进行评估。文章还使用去模糊图像和真实图像之间的特征距离(即来自某些深层网络的输出的 L2 距离)作为语义相似性的度量,因为实验发现它是比 PSNR 和 SSIM 更好的感知度量。
对于 CelebA 数据集,使用来自 VGG-Face 的 pool5 层的输出,对于文本数据集,使用来自 VGG-19 网络的 pool5 层的输出。对于文本去模糊,另一个有意义的度量是去模糊文本的 OCR 识别率。
结果
在可视化模型和定量对比上,文章对比了各类模型的去模糊的效果:
实验也对比了各个组间的有无对实验结果的影响:

文本去模糊方面:

总结
文章提出了一种无监督的领域特定单图像去模糊方法。通过解开模糊图像中的内容和模糊特征,并添加 KL 散度损失以阻止模糊特征对内容信息进行编码。为了保留原始图像的内容结构,在框架中添加了模糊分支和循环一致性损失,同时添加的感知损失有助于模糊图像去除不切实际的伪像。每个组件的消融研究显示了不同模块的有效性。
文章的创新之处正是内容编码器和模糊编码器的设计和应用,尝试将内容和模糊信息分离,这对图像到图像的工作具有一定的指导意义。















 4111
4111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









