







1、搜索

搜索:计算机根据用户输入的关键词进行匹配,从已有的数据库中摘录出相关的记录反馈给用户。
若使用传统关系型数据库:
1、对于传统的关系性数据库对于关键词的查询,只能逐字逐行的匹配,性能非常差。
2、匹配方式不合理,比如搜索“小密手机” ,如果用like进行匹配, 根本匹配不到。但是考虑使用者的用户体验的话,除了完全匹配的记录,还应该显示一部分近似匹配的记录,至少应该匹配到“手机”。
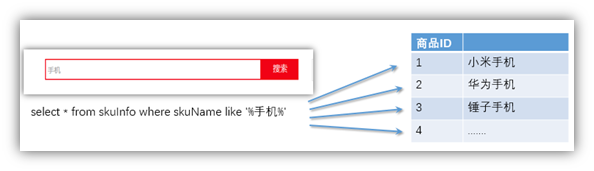
使用专业全文索引进行搜索:
全文搜索引擎目前主流的索引技术就是倒排索引的方式。-----用内容去匹配索引
传统的保存数据的方式都是:记录→单词
而倒排索引的保存数据的方式是:单词→记录

搜索引擎匹配搜索:
处理分词、构建倒排索引都通过Lucene实现。
1、基于分词技术构建倒排索引:-----在内容上建立索引,用内容去匹配索引---B+树
首先每个记录保存数据时,都不会直接存入数据库。
系统先会对数据进行分词,然后以倒排索引结构保存。
2、等到用户搜索的时候,会把搜索的关键词也进行分词,会把“红海行动”分词分成:红海和行动两个词。
这样的话,先用红海进行匹配,得到id=1和id=2的记录编号,再用行动匹配可以迅速定位id为1,3的记录。
那么全文索引通常,还会根据匹配程度进行打分,显然1号记录能匹配的次数更多。
所以显示的时候以评分进行排序的话,1号记录会排到最前面。而2、3号记录也可以匹配到。
2、全文检索工具Elasticsearch
lucene只是一个提供全文搜索功能类库的核心工具包,而真正使用它还需要一个完善的服务框架搭建起来的应用。------lucene是类似于jdk,而搜索引擎软件就是tomcat
Elasticsearch是一个基于Apache Lucene™的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。
特点:
1、分布式的实时文件存储,每个字段都被索引并可被搜索
2、分布式的实时分析搜索引擎–做不规则查询
3、可以扩展到上百台服务器,处理PB级结构化或非结构化数据
Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
ES能做什么?
全文检索(全部字段)、模糊查询(搜索)、数据分析(提供分析语法,例如聚合)
elasticsearch和solr,----都是基于lucene搭建的,可以独立部署启动的搜索引擎服务软件
国内百度、京东、新浪都是基于elasticSearch实现的搜索功能。
国外就更多了 像维基百科、GitHub、Stack Overflow等等也都是基于ES的
区别:
1. Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能;
2. Solr 支持更多格式的数据,而 Elasticsearch 仅支持json文件格式;
3. Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供;
4. Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch--附近的人
将ES 配置在虚拟机上:
–比较烦人,要切换root和其它用户。修改默认线程数、最大文件数、最大内存数
修改四个地方:
elasticSearch.yml es的启动host地址
jvm.options配置es的虚拟机内存
limits.conf配置linux的线程内存和文件
sysctl.conf配置系统允许的软件运行内存
ES基本概念:

1、cluster 整个elasticsearch 默认就是集群状态,整个集群是一份完整、互备的数据。
2、node 集群中的一个节点,一般只一个进程就是一个node
3、shard 分片,即使是一个节点中的数据也会通过hash算法,分成多个片存放,默认是5片。
4、Index(库) 相当于rdbms的database, 对于用户来说是一个逻辑数据库,虽然物理上会被分多个shard存放,也可能存放在多个node中。
5、Type(表) 类似于rdbms的table,但是与其说像table,其实更像面向对象中的class , 同一Json的格式的数据集合。
6、Document(一条数据) 类似于rdbms的 row、面向对象里的object
7、Field(字段) 相当于字段、属性
通过(9200端口)http协议进行交互:http://192.168.199.129:9200/_cat/indices?v
开发工具 Kibana(5601端口):配置host、es.url,—nohup ./kibana &
ES简单的增删改查
PUT、DELETE、POST、GET

中文分词
elasticsearch本身自带的中文分词,就是单纯把中文一个字一个字的分开,根本没有词汇的概念。
安装中文分词器ik。
ik(中英文分词器)有两个:
1 ik_smart(简易分词–最少切分)我、是、中国人
2 ik_max_word(尽最大可能分词–最细粒度划分)我、是、中国人、中国、人
相关性算分
指文档与查询语句间的相关度,通过倒排索引可以获取与查询语句相匹配的文档列表
如何将最符合用户查询需求的文档放到前列呢?
本质问题是一个排序的问题,排序的依据是相关性算分,确定倒排索引哪个文档排在前面
影响相关度算分的参数:
1、TF(Term Frequency):词频,即单词在文档中出现的次数,词频越高,相关度越高
2、Document Frequency(DF):文档词频,即单词出现的文档数
3、IDF(Inverse Document Frequency):逆向文档词频,与文档词频相反,即1/DF。
即单词出现的文档数越少,相关度越高(如果一个单词在文档集出现越少,算为越重要单词)
4、Field-length Norm:文档越短,相关度越高
TF/IDE模型、BM25模型
ElasticSearch集群
克隆一个虚拟机做集群。–修改配置文件elasticserach.yml
1、简介
一个节点(node)就是一个Elasticsearch实例,
而一个集群(cluster)由一个或多个节点组成,它们具有相同的cluster.name,它们协同工作,分享数据和负载。
当加入新的节点或者删除一个节点时,集群就会感知到并平衡数据(同步)。
几个基本概念:
1、节点:一个节点就是一个es的服务器,
es集群中,主节点负责集群的管理和任务的分发,一般不负责文档的增删改查
2、片:分片是es的实际物理存储单元(一个lucene的实例)
3、索引:索引是es的逻辑单元,一个索引一般建立在多个不同机器的分片上
4、复制片:每个机器的分片一般在其他机器上会有两到三个复制片(目的是提高数据的容错率)
5、容错:一旦集群中的某些机器发生故障,那么剩余的机器会在主机点的管理下,重新分配资源(分片)
6、分片的路由:写操作(新建、删除)只在主分片上进行,然后将结果同步给复制分片
Sync 主分片同步给复制成功后,才返回结果给客户端
Async 主分片在操作成功后,在同步复制分片的同时返回成功结果给客户端
读操作(查询)可以在主分片或者复制分片上进行
2、节点
1、集群中一个节点会被选举为主节点(master)
2、主节点临时管理集群级别的一些变更,例如新建或删除索引、增加或移除节点等。
3、主节点不参与文档级别的变更或搜索,这意味着在流量增长的时候,该主节点不会成为集群的瓶颈。
4、任何节点都可以成为主节点。
5、用户,我们能够与集群中的任何节点通信,包括主节点。
6、每一个节点都知道文档存在于哪个节点上,它们可以转发请求到相应的节点上。
7、我们访问的节点负责收集各节点返回的数据,最后一起返回给客户端。这一切都由Elasticsearch处理。
3、集群健康
集群健康有三种状态:green、yellow或red。
green 所有主要分片和复制分片都可用
yellow 所有主要分片可用,但不是所有复制分片都可用
red 不是所有的主要分片都可用
4、集群分片
索引只是一个用来指向一个或多个分片(shards)的“逻辑命名空间(logical namespace)”.
分片(shard)是一个最小级别“工作单元(worker unit)”,它只是保存了索引中所有数据的一部分,是一个Lucene实例,并且它本身就是一个完整的搜索引擎。
文档存储在分片中,并且在分片中被索引,但应用程序不会直接与分片通信,而是直接与索引通信。
1、主分片
索引中的每个文档属于一个单独的主分片,所以主分片的数量决定了索引最多能存储多少数据。
理论上主分片能存储的数据大小是没有限制的,限制取决于你实际的使用情况。
分片的最大容量完全取决于你的使用状况:硬件存储的大小、文档的大小和复杂度、如何索引和查询你的文档,以及你期望的响应时间。
2、副分片
复制分片只是主分片的一个副本,它可以防止硬件故障导致的数据丢失,
同时可以提供读请求,比如搜索或者从别的shard取回文档。
当索引创建完成的时候,主分片的数量就固定了,但是复制分片的数量可以随时调整。
3、搜索模块
1、整合es到项目
以Rest Api为主的missing client,最典型的就是jest。
Jest客户端可以直接使用dsl语句拼成的字符串,直接传给服务端,然后返回json字符串再解析。
在search-service中引入jest和jna的pom依赖。
在parent中将版本号纳入管理。
spring-boot-starter-data-elasticsearch不用管理版本号,版本跟随springboot。
配置文件中配置jest:spring.elasticsearch.jest.uris=http://192.168.199.129:9200
2、得到商品列表
1、通过首页的3级分类进入,按照分类id查询对应的属性和属性值列表。
2、直接通过搜索栏输入文字进入,根据sku的查询结果涉及的属性值,再去查询数据库显示属性文字列表。
实现步骤:
1、数据结构的准备
通过ES的mapping定义商品的数据结构:
ES的mapping定义-----基于整个库
MySQL数据结构字段定义------基于整个表
数据结构:
1 商品名称(展示/查询)
2 商品价格(展示/查询)
3 商品图片(展示)
4 平台属性和属性值的列表(查询)
5 商品描述(展示/查询)
6 热度值(查询)
7 三级分类id(查询)
8 商品id
9 主键
参数结构:
关键字(商品名称(展示/查询) 5 商品描述(展示/查询) 2 商品价格(展示/查询))
平台属性和属性值的列表(查询)
三级分类id(查询)

代码实现:

PUT gmall
{
"mappings": {
"PmsSkuInfo":{//表名
"properties": {//属性
"id":{
"type": "keyword",
"index": true
},
"skuName":{
"type": "text",
"analyzer": "ik_max_word"
},
"skuDesc":{
"type": "text"
, "analyzer": "ik_smart"
},
"catalog3Id":{
"type": "keyword"
},
"price":{
"type": "double"
},
"skuDefaultImg":{
"type": "keyword",
"index": false
},
"hotScore":{
"type": "double"
},
"productId":{
"type": "keyword"
},
"skuAttrValueList":{
"properties": {
"attrId":{
"type":"keyword"
},
"valueId":{
"type":"keyword"
}
}
}
}
}
}
}
2、初始化项目
搜索页面平台属性列表
平台属性列表是从搜索结果中抽取出来的,不是根据三级分类id查询的所有平台属性的集合
1、es中使用aggs聚合函数抽取平台属性—aggs与query平级
对skuAttrValueList中的valueId进行聚合
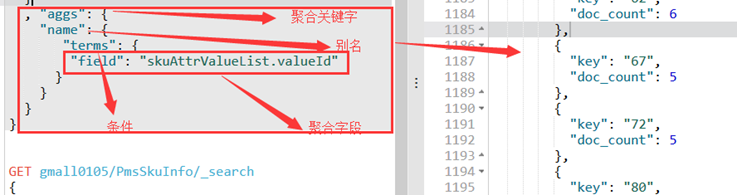
TermsBuilder groupby_attr = AggregationBuilders.terms("groupby_attr").field("skuAttrValueList.valueId");
searchSourceBuilder.aggregation(groupby_attr);
2、使用java代码抽取平台属性
A 根据skuId去mysql中查询平台属性值的id集合(不推荐)
B 直接用java集合进行处理—用set集合将不重复的属性值id抽取出来
//调用搜索服务--list,返回搜索结果
List<PmsSearchSkuInfo> pmsSearchSkuInfos = searchService.list(pmsSearchParam);
modelMap.put("skuLsInfoList", pmsSearchSkuInfos);
//根据检索的结果抽取所包含的平台属性集合 --- 不建议使用mysql查询---set性能更高
Set<String> valueIdSet = new HashSet<>();//通过哈希表完成去重
for (PmsSearchSkuInfo pmsSearchSkuInfo : pmsSearchSkuInfos) {
List<PmsSkuAttrValue> skuAttrValueList = pmsSearchSkuInfo.getSkuAttrValueList();
for (PmsSkuAttrValue pmsSkuAttrValue : skuAttrValueList) {
String valueId = pmsSkuAttrValue.getValueId();
valueIdSet.add(valueId);
}
}
//调用属性服务AttrService根据属性值id将平台属性的集合列表查询出来,通过modelMap传给页面
List<PmsBaseAttrInfo> pmsBaseAttrInfos = attrService.getAttrValueListByValueId(valueIdSet);
modelMap.put("attrList", pmsBaseAttrInfos);
SearchSeviceImpl:
@Override//通过给定搜索参数pmsSearchParam,返回查询到的商品信息
public List<PmsSearchSkuInfo> list(PmsSearchParam pmsSearchParam) {
String dslStr = getSearchDsl(pmsSearchParam);//通过辅助函数将es查询到的
System.err.println(dslStr);
// 用api执行复杂查询
List<PmsSearchSkuInfo> pmsSearchSkuInfos = new ArrayList<>();
Search search = new Search.Builder(dslStr).addIndex("gmall0105").addType("PmsSkuInfo").build();
SearchResult execute = null;
try {
execute = jestClient.execute(search);
} catch (IOException e) {
e.printStackTrace();
}
List<SearchResult.Hit<PmsSearchSkuInfo, Void>> hits = execute.getHits(PmsSearchSkuInfo.class);
for (SearchResult.Hit<PmsSearchSkuInfo, Void> hit : hits) {
PmsSearchSkuInfo source = hit.source;//从结果中取出数据本身
Map<String, List<String>> highlight = hit.highlight;//从es查询到的结果中,hit中取出高亮字段--highlight里面的是红的
if(highlight != null){
String skuName = highlight.get("skuName").get(0);
source.setSkuName(skuName);//取出红色的字放到source中
}
pmsSearchSkuInfos.add(source);
}
System.out.println(pmsSearchSkuInfos.size());
return pmsSearchSkuInfos;
}
//定义复杂查询的辅助函数--给定查询参数,返回字符串
private String getSearchDsl(PmsSearchParam pmsSearchParam) {
//从给定的查询参数pmsSearchParam中取出这三个内容
String[] skuAttrValueList = pmsSearchParam.getValueId();
String keyword = pmsSearchParam.getKeyword();
String catalog3Id = pmsSearchParam.getCatalog3Id();
// jest的dsl的封装工具类 ---//使用jest将写好的dsl语句包装起来,传给es运行
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
/**
* dsl-查询前过滤格式:
*
* Query{
* Bool:{// 先过滤,后查询
* Filter:{term,term}
* must:{match}
* }
* }
*
*/
// bool
BoolQueryBuilder boolQueryBuilder = new BoolQueryBuilder();//将filter和must封装在bool里面
// filter
if(StringUtils.isNotBlank(catalog3Id)){
TermQueryBuilder termQueryBuilder = new TermQueryBuilder("catalog3Id",catalog3Id);//term条件
boolQueryBuilder.filter(termQueryBuilder);
}
if(skuAttrValueList!=null){
for (String pmsSkuAttrValue : skuAttrValueList) {
TermQueryBuilder termQueryBuilder = new TermQueryBuilder("skuAttrValueList.valueId",pmsSkuAttrValue);
boolQueryBuilder.filter(termQueryBuilder);//过滤
}
}
// must
if(StringUtils.isNotBlank(keyword)){
MatchQueryBuilder matchQueryBuilder = new MatchQueryBuilder("skuName",keyword);//match条件
boolQueryBuilder.must(matchQueryBuilder);//必须符合
}
// query
searchSourceBuilder.query(boolQueryBuilder);//将bool放在query里面
// highlight----将查到的keyWord进行高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.preTags("<span style='color:red;'>");//前缀
highlightBuilder.field("skuName");//字段-----对skuName进行高亮
highlightBuilder.postTags("</span>");//后缀
searchSourceBuilder.highlight(highlightBuilder);
// sort -- 对查询到的结果进行排序,按照id降序 SortOrder是一个常量类
searchSourceBuilder.sort("id", SortOrder.DESC);
// from
searchSourceBuilder.from(0);
// size
searchSourceBuilder.size(20);
//aggs
//--- es中使用aggs聚合函数抽取平台属性 ---损失查询性能
//es中aggs与query平级---"groupby_attr"是别名,"skuAttrValueList.valueId"是聚合字段
TermsBuilder groupby_attr = AggregationBuilders.terms("groupby_attr").field("skuAttrValueList.valueId");
searchSourceBuilder.aggregation(groupby_attr);
return searchSourceBuilder.toString();//将查询到的结果封装成字符串
}
面包屑:

1 当前请求url中所包含的属性=面包屑中所包含的属性
2 属性列表中的属性是排除了当前请求(面包屑请求)中的属性的剩余属性
3 去除一个选中属性:当点击面包屑后,新请求url=当前请求url-被点击面包屑
4 增加一个选中属性:当点击属性列表后,新请求url=当前请求+被点击的属性列表
当前请求的url的参数就是pmsSearchParam是所提交的参数


@Controller
public class SearchController {
@Reference
SearchService searchService;
@Reference
AttrService attrService;
@RequestMapping("list.html")
public String list(PmsSearchParam pmsSearchParam, ModelMap modelMap) {//三级分类ID、关键字
//调用搜索服务--list,返回搜索结果
List<PmsSearchSkuInfo> pmsSearchSkuInfos = searchService.list(pmsSearchParam);
modelMap.put("skuLsInfoList", pmsSearchSkuInfos);
//根据检索的结果抽取所包含的平台属性集合 --- 不建议使用mysql查询---set性能更高
Set<String> valueIdSet = new HashSet<>();//通过哈希表完成去重
for (PmsSearchSkuInfo pmsSearchSkuInfo : pmsSearchSkuInfos) {
List<PmsSkuAttrValue> skuAttrValueList = pmsSearchSkuInfo.getSkuAttrValueList();
for (PmsSkuAttrValue pmsSkuAttrValue : skuAttrValueList) {
String valueId = pmsSkuAttrValue.getValueId();
valueIdSet.add(valueId);
}
}
//调用属性服务AttrService根据属性值id将平台属性的集合列表查询出来,通过modelMap传给页面
List<PmsBaseAttrInfo> pmsBaseAttrInfos = attrService.getAttrValueListByValueId(valueIdSet);
modelMap.put("attrList", pmsBaseAttrInfos);
//---------面包屑------------------
//对平台属性集合进一步处理,去掉当前条件中valueId所在的属性组
String[] delValueIds = pmsSearchParam.getValueId();
if (delValueIds != null) {
//面包屑:用户所点击过的平台属性
//面包屑请求 :当前请求 – 当前面包屑的属性 = 新url
List<PmsSearchCrumb> pmsSearchCrumbs = new ArrayList<>();
for (String delValueId : delValueIds) {//将面包屑功能进行整合 ===循环前后的顺序可以换
//--这里要将iterator放进循环里面
// Iterator是一个独立的迭代器,不是集合本身,只负责用游标指向集合某一个元素,适合做检查式的删除
//平台属性集合,每次都要重新扫一遍,迭代器循环完一遍就没了,会导致第二个面包屑扫不到值---要把迭代器放里面
Iterator<PmsBaseAttrInfo> iterator = pmsBaseAttrInfos.iterator();
//生成面包屑的参数PmsSearchCrumb包含属性值、属性Id和地址参数
PmsSearchCrumb pmsSearchCrumb = new PmsSearchCrumb();
pmsSearchCrumb.setValueId(delValueId);
pmsSearchCrumb.setUrlParam(getUrlParamForCrumb(pmsSearchParam, delValueId));
while (iterator.hasNext()) {
PmsBaseAttrInfo pmsBaseAttrInfo = iterator.next();
List<PmsBaseAttrValue> attrValueList = pmsBaseAttrInfo.getAttrValueList();
for (PmsBaseAttrValue pmsBaseAttrValue : attrValueList) {
String valueId = pmsBaseAttrValue.getId();
if (valueId.equals(delValueId)) {
//查找面包屑的属性值名称
pmsSearchCrumb.setValueName(pmsBaseAttrValue.getValueName());
//删除当前valueId所在的属性组
iterator.remove();
}
}
}
pmsSearchCrumbs.add(pmsSearchCrumb);
}
modelMap.put("attrValueSelectedList", pmsSearchCrumbs);//把面包屑集合传给页面
}
//如果使用ArrayList去删除,最后一个元素会报下标越界问题,,并且这样删除,效率低
//错误代码,没办法删除
// for (PmsBaseAttrInfo pmsBaseAttrInfo : pmsBaseAttrInfos) {
// List<PmsBaseAttrValue> attrValueList = pmsBaseAttrInfo.getAttrValueList();
// for (PmsBaseAttrValue pmsBaseAttrValue : attrValueList) {
// String valueId = pmsBaseAttrValue.getId();
// for (String delValueId : delValueIds) {
// if (valueId.equals(delValueId)){
// //删除当前valueId所在的属性组
// }
// }
// }
// }
//当前请求的url的参数就是pmsSearchParam是所提交的参数
String urlParam = getUrlParam(pmsSearchParam);
modelMap.put("urlParam", urlParam);//需要做的就是计算出这个urlParam
String keyword = pmsSearchParam.getKeyword();
if (StringUtils.isNotBlank(keyword)) {
modelMap.put("keyword", keyword);
}
// //面包屑:用户所点击过的平台属性
// //面包屑请求 :当前请求 – 当前面包屑的属性 = 新url
//
// List<PmsSearchCrumb> pmsSearchCrumbs = new ArrayList<>();
// if (delValueIds != null) {
// //如果delValueIds参数不为空,说明当前请求中包含属性的参数,每一个属性参数都会生成一个面包屑
// for (String delValueId : delValueIds) {
// //生成面包屑的参数
// PmsSearchCrumb pmsSearchCrumb = new PmsSearchCrumb();
// pmsSearchCrumb.setValueId(delValueId);
// pmsSearchCrumb.setValueName(delValueId);
// pmsSearchCrumb.setUrlParam(getUrlParamForCrumb(pmsSearchParam, delValueId));
// pmsSearchCrumbs.add(pmsSearchCrumb);
// }
// }
//
// modelMap.put("attrValueSelectedList", pmsSearchCrumbs);
/**
* 与页面对接
<a class="select-attr" th:each="baseAttrValueSelected:${attrValueSelectedList}"
th:href="'list.html?'+${baseAttrValueSelected.urlParam}" th:utext=" ${baseAttrValueSelected.valueName} +'<b> ✖ </b>'" > 2G<b> ✖ </b>
<!-- 这里是面包屑的显示部分 -->
<li th:each="attrValue:${attrInfo.attrValueList}">
<a th:href="'/list.html?'+${urlParam}+'&valueId='+${attrValue.id}" th:text="${attrValue.valueName}">属性值</a></li>
<!-- // 当点击属性列表后=属性列表url是当前请求+被点击的属性列表的新请求
urlParam是当前请求 &valueId='+${attrValue.id}是属性列表的值 当前请求的url的参数就是pmsSearchParam是所提交的参数 -->
*/
return "list";
}
//单独为面包屑写一个方法
//返回面包屑的地址参数--给定查询参数和要删除的属性Id,因为要删除这个面包屑,因此这个地址参数要加上这个属性Id=
private String getUrlParamForCrumb(PmsSearchParam pmsSearchParam, String delValueId) {
String keyword = pmsSearchParam.getKeyword();
String catalog3Id = pmsSearchParam.getCatalog3Id();
String[] skuAttrValueList = pmsSearchParam.getValueId();
String urlParam = "";
//拼接关键字和三级分类ID,通过&连接
if (StringUtils.isNotBlank(keyword)) {
if (StringUtils.isNotBlank(urlParam)) {
urlParam = urlParam + "&";
}
urlParam += "keyword=" + keyword;
}
if (StringUtils.isNotBlank(catalog3Id)) {
if (StringUtils.isNotBlank(urlParam)) {
urlParam = urlParam + "&";
}
urlParam = urlParam + "catalog3Id=" + catalog3Id;
}
if (skuAttrValueList != null) {
for (String pmsSkuAttrValue : skuAttrValueList) {
if (!pmsSkuAttrValue.equals(delValueId)) { //面包屑功能。。
urlParam = urlParam + "&valueId=" + pmsSkuAttrValue;
}
}
}
return urlParam;
}
//给定传给的搜索参数,返回新请求的url
private String getUrlParam(PmsSearchParam pmsSearchParam, String... delValueId) {//可变形参。合并两个方法
String keyword = pmsSearchParam.getKeyword();
String catalog3Id = pmsSearchParam.getCatalog3Id();
String[] skuAttrValueList = pmsSearchParam.getValueId();
String urlParam = "";
if (StringUtils.isNotBlank(keyword)) {
if (StringUtils.isNotBlank(urlParam)) {
urlParam = urlParam + "&";
}
urlParam += "keyword=" + keyword;
}
if (StringUtils.isNotBlank(catalog3Id)) {
if (StringUtils.isNotBlank(urlParam)) {
urlParam = urlParam + "&";
}
urlParam = urlParam + "catalog3Id=" + catalog3Id;
}
//将所有获取到的属性Id都拼接起来
if (skuAttrValueList != null) {
for (String pmsSkuAttrValue : skuAttrValueList) {
urlParam = urlParam + "&valueId=" + pmsSkuAttrValue;
}
}
return urlParam;
}
@RequestMapping("index")
//这里在搜索的首页,如果用户主动登录
@LoginRequired(loginSuccess = false)//如果购物车及以后需要对用户的身份进行验证或者验证token都可以使用这个注解
public String index() {
return "index";
}
}
不想写了,写注释了。















 876
876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









