







基础知识
看过我博客的朋友可以知道,之前我一直在搞Java,但是由于去了实习公司后,技术栈是 py 和 go,之前也是一直挺想学习 go的,接下来便开启新的征程吧。
部分内容参考:李文塔老师编著的《Go语言核心编程》
1.语言简介
1.1 Go 语言诞生原因
- 并发不友好
- 编译速度慢
- 编程复杂
Go 语言的诞生就是为了解决以上三个问题。
1.2 Go 应用领域
- 区块链的应用开发
- 后台的服务应用
- 云计算/云服务后台应用
我本人对后台开发的方向比较感兴趣,学习 Java 的时候便一直在学习后台开发,在公司时,旁别的小姐姐就是从事 Go 的后台开发。
1.3 Go 的特点
Go 语言保证了既能达到静态编译语言的安全和性能,又达到了动态语言开发维护的高效率,使用一个表达式来形容Go语言:Go = C + Python,说明 Go 语言既有 C 静态语言程序的运行速度,又能达到 Python 动态语言的快速开发。
- 从 C 语言中继承了很多理念,包括表达式语法,控制结构,基础数据类型,调用参数传值,指针等,也保留了和 C 语言一样的编译执行方式及弱化的指针。
- 引入包的概念,用于组织程序结构,Go语言的每一个文件都要属于一个包,而不能单独存在。
- 垃圾回收机制,内存自动回收,不需要开发人员管理
- 天然并发
- 函数可以返回多个值
- 新的创新:比如切片 slice、延时执行 defer 等
1.3 Hello World
学习任何语言的第一个程序相比都是 "Hello,World“吧,接下来让我们看下 Go 下的该程序。
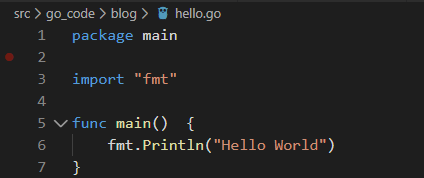
第一行,定义一个包,在 Go 中,任何一个 .go 文件都要保含在一个包中。与 Java 不同的是,包名并不要求是所在的文件夹名。
第三行,导入一个包 fmt,可以是标准库提供的包,也可以是自定义的包。
第五行,func 表示这是一个函数。main 表示这是 go 程序的执行入口,程序的执行便从这里开始。
第六行,调用 fmt 包下的 Println 函数,将 “Hello World”输出到标准输出流即显示器。
1.3.1 编译运行
- 方式一(不生成可执行文件)

2. 方式二(生成可执行文件)

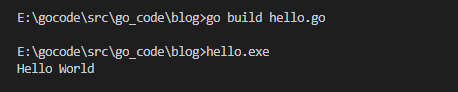
两种执行流程的方式区别
1)如果我们先编译生成了可执行文件,那么我们可以将该可执行文件拷贝到没有go开发环境的机器上运行。
2)如果我们执行go run 源码,那么在另一台机器运行,需要有go 的开发环境。
3)在编译时,编译器会将程序运行依赖的库文件包含在可执行文件中,所以,可执行文件变大了很多。
1.4 Go 开发注意事项
- Go 源文件以 “go”为扩展名
- Go 应用程序的执行入口是 main() 方法
- Go 语言严格区分大小写
- Go 方法由一条条语句构成,每个语句后不需要分号(Go 语言会自动在每行后自动加分号)
- Go 编译器是一行行进行编译的,因此我们一行就写一条语句,不能把多条语句写在同一行,否则报错
- Go 语言定义的变量或者 import 的包没有使用到,代码不能编译通过
- 大括号都是成对出现的,缺一不可
- 源程序默认为 UTF-8 编码
- main 函数所在的包名必须是 main
1.5 Go 词法单元
1.5.1 标识符
标识符用来标识变量、类型、常量等语法对象的符号名称。
标识符分为两类:一类是语言设计者预留的标识符,另一类是编程者自定义的标识符,自定义的标识符应该避开预留的标识符。
标识符的命名规则:
- 由 26 个英文字母大小写,0-9,_组成
- 不可以以数字开头
- 严格区分大小写
- 标识符不能包含空格
- 下划线“_”本身在 Go 中是一个特殊的标识符,称为空标识符,可以代表任何其他的标识符,但是它对应的值会被忽略(比如:忽略某个返回值),所以仅能呗作为占位符使用,不能作为标识符使用
Go 语言预声明的标识符包括关键字、内置数据类型标识符、常量值标识符、零值、内置函数和空白标识符。
关键字(25)

内置数据类型标识符(20)

内置函数(15)

内置函数是语言内置的,不需要 import 引入,可以直接调用。
常量(3)

itoa 用在连续的枚举类型的声明中。
零值(1)

nil 是指针/引用类型的变量的默认值,类似于 Java 中的 NULL。
空白标识符(1)
_
空标示符”_”是一个占位符,它用于在赋值操作的时候将某个值赋值给空标示符号,从而达到丢弃该值的目的。空标示符不是一个新的变量,因此将它用于:=操作符号的时候,必须同时为至少另一个值赋值。
1.5.2 运算符
算术运算符

在 Go 中,++ 以及 – 只能放在变量的后面,即只能 a++,不能 ++a。
比较运算符

逻辑运算符

赋值运算符

位运算符

其他运算符

1.5.3 字面常量
编程语言源程序中标识固定值的符号叫做字面常量,简称字面量。
- 整性字面量
42
0600
0xAb
- 浮点型字面量
0.0
5.2
- 复数类型字面量
0i
2.7i
- 字符型字面量
‘a’
‘人’
- 字符串型字面量
“Hello”
“中国”
1.6 变量和常量
1.6.1 变量
变量:使用一个名称来绑定一块内存地址,该内存地址中存放的数据类型由定义变量时指定的类型决定,该内存地址里面存放的内容可以改变。
变量基本类型的声明有两种方式方式:
- 显式的完整声明
var varName dataType [ = value]
说明:
- 关键字 var 用于变量声明
- dataType 基本类型
- val 是变量的初始值,初始值可以是字面量,也可以是其他变量名,还可以是表达式。如果不指定初始值,则各基本类型有自己的零值。
- Go 变量声明后会立即为其分配空间。
package main
import (
"fmt"
)
func main() {
var a int
var b float32 = 10.5
fmt.Println("a = ", a)
fmt.Println("b = ", b)
}

- 类型推导声明
varName := value
说明:
- := 声明只能出现在方法或者函数内
- Go 编译器会自动进行数据类型推断
- Go 支持多个类信息变量同时声明且赋值
package main
import (
"fmt"
)
func main() {
a, b := 20.5, "Hello"
fmt.Println("a = ", a)
fmt.Println("b = ", b)
}

1.6.2 变量的属性
- 变量名
变量名:Go 中使用自定义标识符来声明一个变量。
- 变量值
变量实际指向的是地址里存放的值,变量的值具体怎么解析由变量的类型决定。
-
变量存储和生存期
Go 提供自动内存管理,通常不需要程序员关注变量的生存期和存放位置。编译器使用栈逃逸技术能够自动为变量分配空间:可能在栈上,也可能在堆上。 -
类型信息
类型决定了该变量存储的值怎么解析,以及支持哪些操作和运算,不同类型的变量支持的操作和运算是不一样的。
- 可见性和作用域
Go 内部使用统一的命名空间堆变量进行管理,每隔变量都有一个唯一的名字,包名是这个名字的前缀。
1.6.3 常量
常量使用一个名称来绑定一块内存地址,该内存地址中存放的数据类型由定义常量时指定的类型决定,而且该内存地址里面存放的内容不可以改变。Go 中常量分为布尔型、字符串型和数值型常量。常量存储在程序的只读段里。
语法:const identifier [type] = value
package main
import (
"fmt"
)
func main(){
const a int = 10
const b string = "hello"
fmt.Println("a = ", a)
fmt.Println("b = ", b)
}
预声明标识符 iota 用在常量声明中,其初始值为0。一组多个常量同时声明其值逐行增加,iota 可以看作自增的美剧变量,专门用来初始化常量。
package main
import (
"fmt"
)
func main(){
const (
c0 = iota // c0 = 0
c1 = iota // c1 = 1
c2 = iota // c2 = 2
)
// 简写模式
const (
c3 = iota // c3 = 0
c4 // c4 = 1
c5 // c5 = 2
)
const (
c6 = iota // c6 = 0
c7 = 3 // c7 = 3
c8 // c8 = 3
)
// iota 逐行增加
const (
a = 1 << iota // a = 1, iota = 0
b = 1 << iota // b = 2, iota = 1
c = 3 // c = 3, iota = 2
d = 1 << iota // d = 8, iota = 3
)
const(
u = iota * 42 // u = 0
v float64 = iota * 42 // v = 42.0
w = iota * 42 // w = 84
)
// 分开的 const 语句,iota 每次都从 0 开始
const x = iota // x = 0
const y = iota // y = 0
}
常量在定义的时候必须初始化

常量不能修改

1.7 数据类型

1.7.1 布尔类型:bool
- bool 类型占1个字节
- 不可以使用 0 或非 0 的整数代替 false 和 true
- 声明的布尔型如不指定初始值,则默认为 false
1.7.2 整型
Go 语言内置了 12 种 整数类型,分别是 byte、int、int8、int16、int32、int64、uint、uint8、uint16、uint32、uint64、uintptr。其中 byte 是 uint8 的别名,不同类型的整型必须进行强制类型转换。
1.7.3 浮点型
浮点型用于表示包含小数点的数据,Go 语言内置两种浮点数类型,分别是 float32 和 float64.
浮点数有两个注意事项:
- 浮点数字面量被自动类型推导为 float64 类型
- 计算机很难进行浮点数的精确表示和存储,因此两个浮点数之间不应该使用 == 或 != 进行比较操作,高精度科学计算应该使用 math 标准库。
1.7.4 复数类型
Go 语言内置的复数类型有两种,分别是 complex64 和 complex128,符数在计算机里面使用两个浮点数表示,一个表示实部,一个表示虚部。complex64 是由两个 float32 构成,complex 使用两个 float64 构成。
package main
import (
"fmt"
)
func main() {
var value1 complex64 = 3.1 + 5i
value2 := 3.1 + 6i
fmt.Println("value1 = ", value1)
fmt.Println("value2 = ", value2)
// Go 有三个内置函数处理复数
var value = complex(2.1, 3) // 构造一个复数
a := real(value) // 返回复数实部
b := imag(value) // 返回复数虚部
fmt.Println("a = ", a)
fmt.Println("b = ", b)
}

1.7.5 字符串
Go 语言将字符串作为一种原生的基本数据类型。
- 字符串是常量,可以通过类似数组索引访问其字节单元,但是不能修改某个字符串的字面量值。
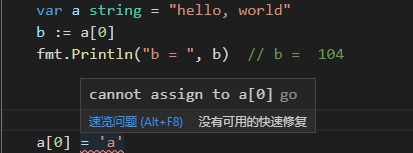
- 字符串转换为切片
[]byte(str)要慎用,尤其是当数据量较大时(每转换一次都需要复制内容)。

- 字符串尾部不包含
\0字符,这点和 C/C++ 不一样 - 字符串类型底层实现是一个二元的数据结构,一个是指针指向字节数组的起点,另一个是长度。
type stringStruct struct{
str unsafe.Pointer // 指向底层字节数组的指针
len int // 字节数组的长度
}
- 基于字符串创建的切片和原字符串指向相同的底层字符串数组,一样不能修改,堆字符串的切片操作返回的子串仍然是 string,而非 slice。

- 字符串和切片的转换:字符串可以转换为字节数组,也可以转换为 Unicode 的字数组。

- 字符串的运算:
package main
import (
"fmt"
)
func main() {
a := "hello"
b := "world"
c := a + b // 字符串拼接
fmt.Println("len = ", len(c)) // 内置的 len 函数获取字符串长度
d := "hello, 世界"
for i := 0; i < len(d); i++{ // 遍历字节数组
fmt.Println(d[i])
}
for i, v := range d{ // 遍历 rune 数组
fmt.Println(i, v)
}
}

- Go 程序是以 UTF-8 表示,字符串同样,而一个汉字是三个字节,所以需要注意。
1.7.6 rune 类型
Go 内置两种字符类型:一种是 byte 的字节类类型(byte 是 uint8 的别名),另一种是 Unicode 编码的字符 rune。rune 在 Go 内部是 int32 类型的别名,占用4各字节。Go 语言默认的字符编码是 UTF-8 类型的,如果需要特殊转换,则使用 Unicde/UTF-8 标准包。
1.7.7 指针
Go语言支持指针,指针的声明类型为 *T,Go同样支持多级指针 **T。通过在变量名前加 &来获取变量的地址。





指针特点:
- 结构体指针访问结构体字段仍然使用
.点操作符,Go语言没有->操作符。 - Go不支持指针的运算
- 函数种允许返回局部变量的地址。
Go编译器使用 “栈逃逸”机制将这种局部变量的空间分配在堆上。例如:
func sum(a int, b int) *int{
sum := a + b
return &sum // 允许,sum 会分配在 heap 上
}
1.7.8 数组
数组的类型名是 [n]elementType,其中 n 是数组长度,elementType 是数组元素类型。

数组初始化
 数组的特点
数组的特点
- 数组创建完长度就固定了,不可以再追加元素
- 数组是值类型,数组赋值或作为函数参数都是值拷贝
- 数组长度是数组类型的组成部分,[10]int 和 [20]int 表示不同的类型
- 可以根据数组创建切片
数组的相关操作
a := [...]int{1, 2, 3}
for i, v := range a{ // 遍历数组
fmt.Printf("a[%d] = %v\n", i, v)
}
fmt.Println("len a = ", len(a)) // 获取数组长度

1.7.9 切片
Go 语言的数组的定长性和值拷贝限制了其使用场景,Go 提供了另一种数据类型 slice,这是一种变长数组,其数据结构中有指向数组的指针,所以是一种引用类型。
type slice struct{
array unsafe.Pointer
len int
cap int
}
Go 切片维护了三个元素–指向底层数组的指针、切片的元素数量和底层数组的容量。

(1)切片的创建
- 由数组创建
创建语法如下:array[i:j],其中,array 表示数组名;i 表示开始索引,可以不指定,默认是0;j表示结束索引,可以不指定,默认是 len(array)。array[i:j] 表示创建一个包含 i-j 个元素的切片,第一个元素是 array[i],最后一个元素是 array[j-1]。
var array = [...]int {0, 1, 2, 3, 4, 5, 6}
fmt.Printf("array type = %T, value = %v \n", array, array)
s1 := array[0:4]
s2 := array[:4]
s3 := array[2:]
fmt.Printf("s1 type = %T, value = %v \n", s1, s1)
fmt.Printf("s2 type = %T, value = %v \n", s2, s2)
fmt.Printf("s3 type = %T, value = %v \n", s3, s3)

- 通过内置函数
make创建切片
var a []int
a = make([]int, 10) // len = 10, cap = 10
b := make([]int, 10, 15) // len = 10, cap = 15
fmt.Println("a = ", a)
fmt.Println("b = ", b)

(2)切片支持的操作
- 内置函数 len() 返回切片长度
- 内置函数 cap() 返回切片底层数组容量
- 内置函数 append() 堆切片追加
- 内置函数 copy() 用于复制一个切片
a := [...]int{0, 1, 2, 3, 4, 5, 6}
b := make([]int, 2, 4)
c := a[0:3]
fmt.Println(len(b)) // 2
fmt.Println(cap(b)) // 4
b = append(b, 1)
fmt.Println(b) // [0 0 1]
fmt.Println(len(b)) // 3
fmt.Println(cap(b)) // 4
b = append(b, c...)
fmt.Println(b) // [0 0 1 0 1 2]
fmt.Println(len(b)) // 6
fmt.Println(cap(b)) // 8 底层数组发生扩展
d := make([]int, 2, 2)
copy(d, c)
fmt.Println(d) // [0 1]
fmt.Println(len(d)) // 2
fmt.Println(cap(d)) // 2
(3)字符串和切片的相关转换
str := "hello,世界"
a := []byte(str) //
fmt.Printf("a type = %T, value = %v\n", a, a)
// a type = []uint8, value = [104 101 108 108 111 44 228 184 150 231 149 140]
b := []rune(str)
fmt.Printf("b type = %T, value = %v\n", b, b)
// b type = []int32, value = [104 101 108 108 111 44 19990 30028]
(4)切片注意事项和细节说明
- 切片初始化时,仍然不能越界。范围在 [0-len(arr)] 之间,但是可以动态增长
- var slice = arr[0 : end],可以简写var slice = arr[ : end]
- var slice = arr[start : len(arr)],可以简写var slice = arr[ start : ]
- var slice = arr[0 : len(arr)],可以简写var slice = arr[ : ]
- cap 是一个内置函数,用于统计切片的容量,即最大可以存放多少个元素
- 切片定义完毕后,还不能使用,因为本身是一个空的,需要让其引用到一个数组,或者 make 一个空间供切片来使用
- 切片可以继续切片
- 切片是引用类型,所以在传递时,遵守引用传递机制
(5)切片 append 操作的底层原理分析:
- 切片 append 操作的本质就是对数组扩容
- go 底层会创建一个新的数组 newArr(按照扩容后大小)
- 将 slice 原来包含的元素拷贝到新的数组 newArr
- slice 重新引用到newArr
1.7.10 map
Go 语言内置的字典类型叫 map。map 的类型格式是 map[K]T,其中 K 可以是任意可以进行比较的类型,T 是值类型。map 也是一种引用类型。
(1)map 的创建
- 使用字面量创建
ma := map[string]int{"a" : 1, "b" : 2}
fmt.Println("ma[a] = ", ma["a"]) // ma[a] = 1
fmt.Println("ma[b] = ", ma["b"]) // ma[b] = 2
- 使用内置的 make 函数创建
// make(map[K]T) map 的容量使用默认值
// make(map[K]T, len) map 的容量使用给定的 len 值
// make 表示分配内存空间,len 表示可以存放见指对的个数
mp1 := make(map[int]string)
mp2 := make(map[int]string, 10)
mp1[1] = "tom"
mp2[1] = "pony"
fmt.Println("mp1[1] = ", mp1[1]) // mp1[1] = tom
fmt.Println("mp2[1] = ", mp2[1]) // mp2[1] = pony
(2)map 支持的操作
- map 的增加和更新
map[key] = value,如果 key 还没有,就是增加,如果 key 存在就是修改。 - map 删除
delete(map, key),delete 是一个内置函数,如果key存在,就删除该 key-value,如果 key 不存在,不操作,但是也不报错。
-
map 的查找

第二个返回值表示是否存在该键值对,如果存在,则为 true,否则为 false。 -
map 的遍历
map 的遍历使用 for-range 的结构遍历。

(3)map 切片
切片的数据类型如果是 map,则我们称为 slice of map,map 切片,这样使用则 map 的个数就可以动态变化了。

 (4)map 注意事项和使用细节
(4)map 注意事项和使用细节
- map 是引用类型,遵守引用类型传递的机制,在一个函数接收 map,修改后,会直接修改原来的 map
- map 的容量达到后,在想 map 增加元素,会自动扩容,并不会发生 panic,也就是说 map 动态的增长键值对

- Go 内置的 map 不是并发安全的,并发安全的 map 可以使用标准包
sync中的 map - 不能直接修改 map value 内某个元素的值,如果想修改 map 的某个键值,则必须整体赋值。
userMap := make(map[int]User)
user := User{
Name : "wangzhao",
Age : 21,
}
userMap[1] = user
// userMap[1].Age = 20 cannot assign to struct field userMap[1].Age in map
user.Age = 20
userMap[1] = user // 必须整体替换value
1.7.11 struct
Go 中的 struct 类型和 C 类似,由多个不同类型元素组合而成。struct 结构体中的类型可以是任意类型,struct 的存储空间是连续的,其中字段按照声明时的顺序存放。
(1)struct 类型声明
type typeName struct{
FieldName FieldType
FieldName FieldType
FieldName FieldType
}
(2)创建结构体变量和访问结构体字段

- 方式一:直接声明

- 方式二:{}

- 方式3:&

- 方式4:{}

(3)结构体使用细节和注意事项 - 结构体的所有字段在内存中是连续的
- 结构体是用户单独定义的类型,和其他类型进行转换时需要有完全相同的字段(名字、个数和类型)

- 结构体进行 type 重新定义(相当于取别名),Golang 认为是新的数据类型,但是相互间可以强转

- struct 每个字段上,可以写上一个 tag,该 tag 可以通过反射机制获取,常见的使用场景就是序列化和反序列化。



1.7.12 其他复合类型
接口和管道后面的博客进行介绍。
1.8 控制结构
1.8.1 if 语句
- 单分支
if 条件表达式 {
执行代码块
}
- 双分支
if 条件表达式 {
执行代码块
}
else{
执行代码块
}
- 多分支
if 条件表达式 {
执行代码块
}
else if 条件表达式{
执行代码块
}
......
else{
执行代码块
}
特点:
- if 后面的条件判断子句不需要用小括号括起来
- { 必须放在 行尾,和 if 或 if else 放在一行
- if 后面可以带一个带简单的初始化语句,并以分号分割,作用域是整个 if 语句块,包括后面的 else if 和 else 分支
- Go 语言没有条件运算符(a > b ? a:b)
1.8.2 switch 语句
基本语法
switch 表达式{
case 表达式1,表达式2,... :
语句块1
case 表达式3,表达式4, ... :
语句块2
default:
语句块
}
switch 使用细节和注意事项
- case 后是一个表达式(常量、变量、一个有返回值的函数等都可以)
- case 后的各个表达式的数据类型,必须和 switch 的表达式数据类型一致
- case 后面可以有多个表达式,使用逗号分隔
- case 后面的表达式如果是常量值,则不能重复
- case 后面不需要带 break
- default 语句不是必须的
- switch 后也可以不带表达式,类型 if - else 分支来使用

- switch 后也可以直接声明/定义一个变量,分号结束

- switch 穿透
fallthrough,如果case 语句块后增加 fallthrough,则会继续执行下一个case

1.8.3 for 语句
- 类 C 的 for 循环语句
for init; condition; post{}
- 类 C 的 while 语句
for condition{}
- 类 C 的 while(1) 语句
for{}
1.8.4 标签和跳转
标签
Go 语言使用标签(Lable)标识一个语句的位置,用于 goto、break、continue 语句的跳转,标签的语法是:
Lable:Statement
goto
goto 语句用于函数的内部跳转,需要配合标签一起使用。
goto Lable
Go 语言的 goto 语句可以无条件地转移到程序中指定地行
goto 语句通常与条件语句配合。
在 Go 程序设计中一般不主张使用 goto 语句,以免造成程序流程混乱。
break
break 语句出现在多层嵌套的语句块中时,可以通过标签指明要终止的是哪一层语句块。

单独使用,跳出当前 break 所在的 for、switch、select 语句的执行。
continue
continue 语句出现在多层嵌套的语句块中时,可以通过标签指明要跳过哪一层循环。
单独使用,跳出当前所在 for 循环的本次迭代。
return和函数调用
return 语句也能引发控制流程的跳转,用于函数和方法的退出。函数和方法的调用也能引发程序控制流的跳转。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









