







1、安装scrapy
pip install scrapy
2、新建一个项目
root@ubuntu:~# scrapy --help
Scrapy 1.0.5 - no active project
Usage:
scrapy <command> [options] [args]
Available commands:
bench Run quick benchmark test
commands
fetch Fetch a URL using the Scrapy downloader
runspider Run a self-contained spider (without creating a project)
settings Get settings values
shell Interactive scraping console
startproject Create new project
version Print Scrapy version
view Open URL in browser, as seen by Scrapy
[ more ] More commands available when run from project directory
Use "scrapy <command> -h" to see more info about a command查了下命令,使用startproject
scrapy startproject qiubai

可以看到这里生成了名为qiubai的文件
3、打开浏览器进入糗事百科网站,我们看到有每页有很多条糗事

我们主要获取:作者名,作者头像、文字内容、附加图片、好笑(赞次数)、评论次数
4、修改items.py文件, 新建一个itme类
import scrapy
class QiubaiItem(scrapy.Item):
# define the fields for your item here like:
author = scrapy.Field() # 作者
author_logo = scrapy.Field() # 作者头像
content = scrapy.Field() # 内容
thumb = scrapy.Field() # 内容图片
vote = scrapy.Field() # 赞人数
comments = scrapy.Field() # 评论数5、添加一个spiders文件,这里我新建文件qiubai_spi.py
右键审查元素
每条糗事为以div包裹,我们点开其中的div
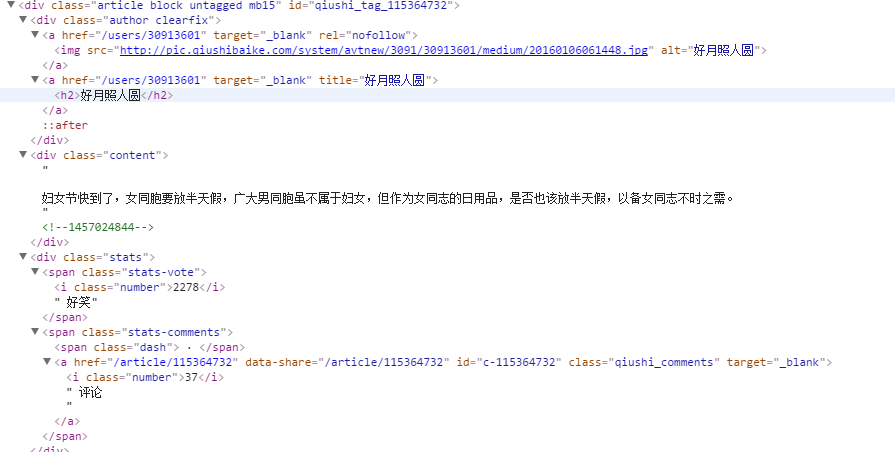
由此我们先进QiubaiSpider类用于抓取数据
import scrapy
from scrapy.http import Request
from qiubai.items import QiubaiItem
class QiubaiSpider(scrapy.Spider):
name = "qiubai"
start_urls = (
'http://www.qiushibaike.com',
)
def parse(self, response):
item = QiubaiItem()
for mb in response.xpath('//div[@class="article block untagged mb15"]'):
author = mb.xpath('div[@class="author clearfix"]/a/h2/text()').extract()[0]
author_logo = mb.xpath('div[@class="author clearfix"]/a/img/@src').extract()[0]
content = mb.xpath('div[@class="content"]/text()').extract()[0]
# 纯文字的糗事,没有图片
thumb = ""
try:
thumb = mb.xpath('div[@class="thumb"]/a/img/@src').extract()[0]
except Exception, e:
pass
item['author'] = author.encode('utf-8') # 转码
item['author_logo'] = author_logo
item['content'] = content.encode('utf-8')
item['thumb'] = thumb
item['vote'] = vote
item['comments'] = comments.encode('utf-8')
yield item
这里需要在settings.py加上这个
`ITEM_PIPELINES = {
'qiubai.pipelines.QiubaiPipeline': 300,
}6、运行爬虫
scrapy crawl qiubai
发现报错了,好像不能直接范围怎么办呢?
你应该想到了,伪造头部,要他觉得我们是浏览器
7、最后代码
加上头部后就可以正常抓取,抓取的时候你可能发现有些会发生错误,那是因为糗事百科前端布局比较变态,比如是匿名发送时,div结果不一样,你需要单独解析。所以下边你会看到很多异常处理,大家可以自己试下。
我这边最后还增加了抓取每一页的一个循环调用,至于解析页码也请大家自己实现
import scrapy
from scrapy.http import Request
from qiubai.items import QiubaiItem
class QiubaiSpider(scrapy.Spider):
name = "qiubai"
start_urls = (
# 'http://www.qiushibaike.com/pic/',
'http://www.qiushibaike.com',
)
# 伪造的头部
headers = {
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8",
"Accept-Encoding": "gzip, deflate, sdch",
"Accept-Language": "zh-CN,zh;q=0.8",
"Cache-Control": "max-age=0",
"Cookie": "CAMPUS_CHECKED=0; JYERN=0.6521779221948236; CAMPUS_CHECKED=0; QS_ED=6; JYERN=0.26531747193075716; QS_GD=7; QS_TM=1; jyean=ZnkIgT1JW7dtwnfPBYUOaQMQ9EHw9Hrhs72JCf4tOTiBEDLIHPZF72BzqUmmVHNWAvt1xk4aizTajtIpfTvTrEE39lecGsS2bVqdUtacbOjnYA2_qVZSih0wl0Ao7Xe00; LF_Email=njxczx08@xyh.com; jy=34C4C600E19323AE7A3588D4651301956A3437AFB5608381E05974D4BC275FA19D4906C1AEFC7D6B868F1A2D306BA4CB38C39F61AB200E02C4A6E6C5F2E1F98D0DBDA7E364FF1E25FB83D488DADBAD62E34C4D6FCA3E4AC9D210FD33668A9E3668258E09AFEF7516B65E7FFEB527606F357ED5F7D5BA8F058BE2EAAE46A7E9403003873D2D71D7DFB3F3C856AD2FFF3AE152FC747C3A7365F0F303CA534515EC779046E472AC790853495CA08517EC6095A325835A7019E2906974067015501F864B8B9CBD1F6AF16CDC4B8BD248876DD343B4367C517BAB05B6701AD2E488A1C3E320B7AD676CFC15E219850E12EBAB82B63CC4ED9A740E8511C4EF3449BE09; jye_notice_show=1|2015/8/31 15:08:32|0|false; JYERN=0.39406700897961855; CAMPUS_CHECKED=0; jye_math_ques_s=0; jye_math_ques_d=0; jye_math_ques_t=1; jye_math_ques_0_q=070eac9c-ad95-44f1-909c-869dbb4c874a~803641a7-c36b-483b-9f8d-ac0a5522e3c3~; CNZZDATA2018550=cnzz_eid%3D484121901-1440586726-http%253A%252F%252Fwww.baidu.com%252F%26ntime%3D1441002725; _cnzz_CV2018550=%E7%94%A8%E6%88%B7%E4%BB%98%E8%B4%B9%7C%E9%9D%9EVIP%E7%94%A8%E6%88%B7%7C1441006330746%26%E7%94%A8%E6%88%B7%E8%A7%92%E8%89%B2%7C%E8%80%81%E5%B8%88%7C14",
"Host": "www.qiushibaike.com",
"Proxy-Connection": "keep-alive",
"Referer": "http://www.qiushibaike.com/",
"User-Agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Ubuntu Chromium/40.0.2214.111 Chrome/40.0.2214.111 Safari/537.36"
}
def start_requests(self):
for url in self.start_urls:
yield self.make_requests_from_url(url)
def make_requests_from_url(self, url):
return Request(url, headers=self.headers, dont_filter=True)
def parse(self, response):
item = QiubaiItem()
for mb in response.xpath('//div[@class="article block untagged mb15"]'):
try:
# 部分为匿名发布,所有以常规解析会出错
try:
# 正常发布
author = mb.xpath('div[@class="author clearfix"]/a/h2/text()').extract()[0]
except Exception, e:
# 匿名发布
author = mb.xpath('div[@class="author clearfix"]/span/h2/text()').extract()[0]
# 部分为匿名发布,所有以常规解析会出错
try:
# 正常发布
author_logo = mb.xpath('div[@class="author clearfix"]/a/img/@src').extract()[0]
except Exception, e:
author_logo = mb.xpath('div[@class="author clearfix"]/span/img/@src').extract()[0]
content = mb.xpath('div[@class="content"]/text()').extract()[0]
# 纯文字的糗事,没有图片
thumb = ""
try:
thumb = mb.xpath('div[@class="thumb"]/a/img/@src').extract()[0]
except Exception, e:
pass
vote = ""
try:
vote = mb.xpath('div[@class="stats"]/span[@class="stats-vote"]/i/text()').extract()[0]
except Exception, e:
# 赞为空
pass
comments = ""
try:
# 评论为空
comments = mb.xpath('div[@class="stats"]/span[@class="stats-comments"]/a/i/text()').extract()[0]
except Exception, e:
pass
item['author'] = author.encode('utf-8') # 转码
item['author_logo'] = author_logo
item['content'] = content.encode('utf-8')
item['thumb'] = thumb
item['vote'] = vote
item['comments'] = comments.encode('utf-8')
# print "===================================="*3
# print "author :", item['author']
# print "author_logo :", item['author_logo']
# print "content :", item['content']
# print "thumb :", item['thumb']
# print "vote :", item['vote']
# print "comment :", item['comments']
# print "\r\n"
yield item
except Exception, e:
print "get info error! continue get next info!"
continue
# 获取下一页的链接
pages = response.xpath('//ul[@class="pagination"]/li')
next_page = pages[-1].xpath('a/@href').extract()[0]
# 如果已经时最后一页了,在继续就到更多内容了,这里我们只抓取首页的内容
if next_page == '/hot':
print "====over===="
return
else:
next_page_url = self.start_urls[0] + next_page
yield Request(url=next_page_url, headers=self.headers, callback=self.parse)














 1037
1037

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









