








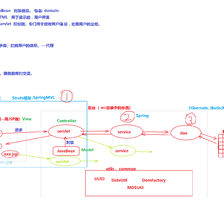
一、hibernate入门
1.hibernate简介:
- Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。 Hibernate可以应用在任何使用JDBC的场合,既可以在Java的客户端程序使用,也可以在Servlet/JSP的Web应用中使用,最具革命意义的是,Hibernate可以在应用EJB的J2EE架构中取代CMP,完成数据持久化的重任。
-
Hibernate是一个开放源码的、非常优秀、成熟的O/R Mapping框架。它提供了强大、高性能的Java对象和关系数据的持久化和查询功能。
-
Hibernate 只是一个将持久化类与数据库表相映射的工具,每个持久化类实例均对应于数据库表中的一条数据行。可以使用面向对象的方法操作此持久化类实例,完成对数据库表的插入、删除、修改等操作。
-
利用Hibernate操作数据库,我们通过应用程序经过Hibernate持久层来访问数据库,其实Hibernate完成了以前JDBC的功能,不过Hibernate使用面向对象的方法操作数据库。
2.包的作用
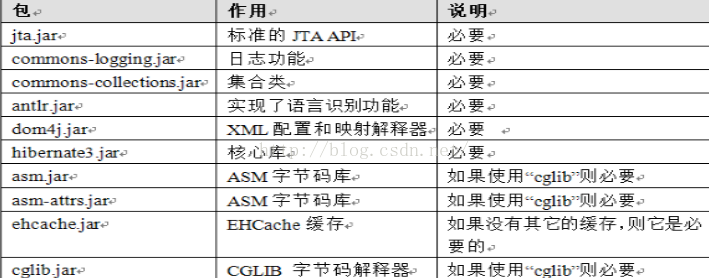
常用的包介绍:
(1)hibernate3.jar: hibernate的核心库,没有什么可说的,必须使用的jar包
(2)cglib-asm.jar: CGLIB库,Hibernate用它来实现PO字节码的动态生成,非常核心的库,必须使用的jar包
(3)dom4j.jar: dom4j是一个Java的XML API,类似于jdom,用来读写XML文件的。dom4j是一个非常非常优秀的Java XML API,具有性能优异、功能强大和极端易用使用的特点,同时它也是一个开放源代码的软件,可以在SourceForge上找到它。在IBM developerWorks上面可以找到一篇文章,对主流的Java XML API进行的性能、功能和易用性的评测,dom4j无论在那个方面都是非常出色的。我早在将近两年之前就开始使用dom4j,直到现在。如今你可以看到越 来越多的Java软件都在使用dom4j来读写XML,特别值得一提的是连Sun的JAXM也在用dom4j。这是必须使用的jar 包,Hibernate用它来读写配置文件。
(4)odmg.jar: ODMG是一个ORM的规范,Hibernate实现了ODMG规范,这是一个核心的库,必须使用的jar包。
(5)commons-collections.jar: Apache Commons包中的一个,包含了一些Apache开发的集合类,功能比java.util.*强大。必须使用的jar包。
(6)commons-beanutils.jar: Apache Commons包中的一个,包含了一些Bean工具类类。必须使用的jar包。
(7)commons-lang.jar: Apache Commons包中的一个,包含了一些数据类型工具类,是java.lang.*的扩展。必须使用的jar包。
(8)commons-logging.jar: Apache Commons包中的一个,包含了日志功能,必须使用的jar包
3.核心接口和类
(1) Configuration接口
Configuration接口负责管理Hibernate的配置信息。为了能够连上数据库必须配置一些属性,这些属性包括:
数据库URL
数据库用户
数据库用户密码
数据库JDBC驱动类
数据库dialect,用于对特定数据库提供支持,其中包含了针对特定数据库特性的实现。
(2) SessionFactory接口
应用程序从SessionFactory(会话工厂)里获得Session(会话)实例。这里用到了一个设计模式即工厂模式,用户程序从工厂类SessionFactory中取得Session的实例。SessionFactory不是轻量级的。它占的资源比较多,所以它应该能在整个应用中共享。一个项目通常只需要一个SessionFactory就够了,但是当项目要操作多个数据库时,必须为每个数据库指定一个SessionFactory。
会话工厂缓存了生成的SQL语句和Hibernate在运行时使用的映射元数据。它也保存了在一个工作单元中读入的数据并且可能在以后的工作单元中被重用(只有类和集合映射指定了使用这种二级缓存时才会如此)Session类。
(3) Session接口——实质上是connaction的子类
该接口是Hibernate使用最多的接口。Session不是线程安全的,它代表与数据库之间的一次操作。Session是持久层操作的基础,相当于JDBC中的Connection。然而在Hibernate中,实例化的Session是一个轻量级的类,创建和销毁它都不会占用很多资源。Session通过SessionFactory打开,在所有的工作完成后,需要关闭。但如果在程序中,不断地创建以及销毁Session对象,则会给系统带来不良影响。所以有时需要考虑session的管理合理的创建合理的销毁。
(4) Query类
Query类可以很方便地对数据库及持久对象进行查询,它可以有两种表达方式:查询语句使用HQL(HQL是Hibernate Query Lanaguage简称是Hibernate配备了一种非常强大的查询语言,类似于SQL)或者本地数据库的SQL语句编写。
(5) Transaction接口
如果你向数据库中增加数据或修改数据时,需要使用事务处理,这时你需要Transaction接口。Transaction接口是对实际事务实现的一个抽象,该接口可以实现JDBC的事务、JTA中的UserTransaction、甚至可以是CORBA事务等跨容器的事务。之所以这样设计是能让开发者能够使用一个统一事务的操作界面,使得自己的项目可以在不同的环境和容器之间方便地移值
4.Hibernate主键ID生成方式
1、assigned:主键由外部程序负责生成,无需Hibernate参与。即当增加一个实体时,由程序设定它的ID值(手工分配值)
<classname="bean.Customer"table="customers" catalog="support">
<id name="customerId"type="java.lang.String">
<column name="customerID"length="8" />
<generatorclass="assigned"></generator>
</id>
.......
</class>
2、identity:在DB2、SQL Server、MySQL等数据库产品中表中主键列可以设定是自动增长列,则增加一条记录时主键的值可以不赋值。用数据库提供的主键生成机制。
(1)表结构:
create table test1 ( tidint not null primary keyauto_increment,
namechar(40));
(2)映射文件
<class name="bean.Test1"table="test1" catalog="support">
<id name="tid"type="java.lang.Integer">
<column name="tid"/>
<generator class="identity"></generator>
</id>
<property name="name"type="java.lang.String">
<column name="name"length="40" />
</property>
</class>
3、increment:主键按数值顺序递增。此方式的实现机制为在当前应用实例中维持一个变量,以保存着当前的最大值,之后每次需要生成主键的时候将此值加1作为主键。这种方式可能产生的问题是:如果当前有多个实例访问同一个数据库,那么由于各个实例各自维护主键状态,不同实例可能生成同样的主键,从而造成主键重复异常。因此,如果同一数据库有多个实例访问,此方式必须避免使用。
<classname="bean.Test2" table="test2"catalog="support">
<id name="tid"type="java.lang.Integer">
<column name="tid"/>
<generator class="increment"></generator>
</id>
<property name="name"type="java.lang.String">
<column name="name"length="40" />
</property>
</class>
4、sequence:采用数据库提供的sequence机制生成主键。
如Oralce中的Sequence,在Oracle中创建序列:
create sequencehibernate_sequence;
当需要保存实例时,Hibernate自动查询Oracle中序列"hibernate_sequence"的下一个值;该值作为主键值。可以改变默认的序列名称。
<id name="sid"type="java.lang.Integer">
<column name="sid"/>
<generator class="sequence"></generator>
</id>
5、native:由Hibernate根据底层数据库自行判断采用identity、hilo、sequence其中一种作为主键生成方式。
6、uuid.hex:由Hibernate为ID列赋值,依据当前客户端机器的IP、JVM启动时间、当前时间、一个计数器生成串,以该串为ID值。
<class name="bean.Test3"table="test3" catalog="support">
<id name="tid"type="java.lang.String">
<column name="tid"length="50" />
<generator class="uuid.hex"></generator>
</id>
<property name="name"type="java.lang.String">
<column name="name"length="40" />
</property>
</class>
5.Hibernate多表操作
关系型数据库具有三种常用关系:一对一关系、一对多关系和多对多关系。
建立了一对多关系的表之间,一方中的表叫“主表”,多方中的表叫“子表”;两表中相关联的字段,在主表中叫“主键”,在子表中称“外键”。
-
一对多关系操作
我们以院系表与学生表为例。在Hibernate映射中,在院系表中添加一个集合属性,集合属性存放该院系下的学生。学生表中将院系编号字段映射成一个院系类对象。这样通过院系类对象的属性集合找到该院系下的所有学生。通过学生对象的院系属性也很快定位到院系的其它信息不仅仅是院系编号。
Student.hbm.xml
<hibernate-mapping> <class name="bean.Student" table="student" catalog="support"> <id name="sno" type="java.lang.String"> <column name="sno" length="4" /> <generator class="assigned"></generator> </id> <!--name设定待映射的持久化类的属性名--> <!--column设定和持久化类的属性对应的表的外键--> <!--class设定持久化类的属性的类型--> <many-to-one name="dept" class="bean.Dept" fetch="select"> <column name="deptid" length="4" /> </many-to-one> <property name="sname" type="java.lang.String"> <column name="sname" length="20" /> </property> </class> </hibernate-mapping>
Dept.hbm.xml
<strong> <hibernate-mapping> <class name="bean.Dept" table="dept" catalog="support"> <id name="deptid" type="java.lang.String"> <column name="deptid" length="4" /> <generator class="assigned"></generator> </id> <property name="deptname" type="java.lang.String"> <column name="deptname" length="30" /> </property> <!-- name设定待映射的持久化类的属性名--> <set name="students" inverse="true"> <!--所关联的持久类对应的表的外键--> <key> <column name="deptid" length="4" /> </key> <!--设定持久化所关联的类--> <one-to-many class="bean.Student" /> </set> </class> </hibernate-mapping> </strong>
-
多对多关系操作
以学生与教师为例,一个教师可以教对个学生,一个学生也可以接受多个老师的教育。所以他们之间是多对多的关系。我们一般建立3个表:学生表、教师表以及学生教师表。
学生类映射文件Student.hbm.xml
<strong> <class name="Student"> ...... <!-- name="teachers" 表示:Student类中有一个属性叫teachers (是Set集合)--> <!-- table="teacher_student" 表示:中间关联表。表名叫teacher_student --> <set name="teachers" table="teacher_student"> <!-- column="student_id" 表示:中间表teacher_student的字段--> <!-- Student类的id与中间表teacher_student的字段student_id对应--> <key column="student_id"/> <!-- column="teacher_id" 表示:中间表teacher_student的字段--> <!-- class="Teacher" 表示:中间表teacher_student的字段teacher_id与 Teacher类的id对应--> <many-to-many class="Teacher” column="teacher_id"/> </set> </class> </strong>教师类映射文件Teacher.hbm.xml
<strong><span style="color:#330033;"> <class name="Teacher"> ...... <set name="students" table="teacher_student"> <key column="teacher_id"/> <many-to-many class="Student" column="student_id"/> </set> </class> </span> </strong>
注意:把多对多关联分解为两个一对多关联,具有更好的可扩展性和操作性。
6.级联操作与延迟加载
(1)、cascade级联操作
所谓cascade,如果有两个表,在更新一方的时候,可以根据对象之间的关联关系,对被关联方进行相应的更新。比如说院系表和学生表之间是一对多关系,使用cascade,如删除院系表中的一条院系记录时,该院系下的所有学生记录也自动删除。这种现象称为级联删除。当创建一个新的院系实例,该院系实例集合属性中保存有学生。当该院系实例持久化时,自动将集合学生也自动添加到数据库的学生表中去。这称为级联增加。
all :所有情况下均进行关联操作。
none:所有情况下均不进行关联操作。这是默认值。
save-update:执行save/update/saveOrUpdate时进行关联操作
delete:在执行delete时进行关联操作。
2、inverse属性(相当于你谢了字表,自动调价主表没有的字段)
这个属性不好理解,打个比方来说这个属性。
一个学校有个校长,学校里有很多学生。学生表中假设有一个字段是校长编号(多方),如果我们增加一个学生,学生记录中校长编号字段如何填呢?显然学生自己填(即由学生方维护)要容易些,学生记住校长现实点。如果你要让校长填写学生的校长编号这个字段(即由校长方维护)则比较难,因为校长如何记住那么多学生呢?
3、延迟加载
(1)属性的延迟加载
如Person表有一个人员图片字段(对应java.sql.Clob类型)属于大数据对象,当我们加载该对象时,我们不得不每一次都要加载这个字段,而不论我们是否真的需要它,而且这种大数据对象的读取本身会带来很大的性能开销。我们可以如下配置我们的实体类的映射文件:
<hibernate-mapping> <class name="bean.Person"table="person"> …… <property name="pimage"type="java.sql.Clob" column="pimage"lazy="true"/> </class> </hibernate-mapping>
7.Hibernate缓存技术
缓存是介于物理数据源与应用程序之间,缓存被广泛用于数据库应用领域。缓存的设计就是为了通过存储已经从数据库读取的数据来减少应用程序和数据库之间的数据流量,而数据库的访问只在检索的数据不在当前缓存的时候才需要。
1、Hibernate缓存范围以及分类 (缓存的范围分为三类)
(1) 事务范围:缓存只能被当前事务访问。缓存的生命周期依赖于事务的生命周期,当事务结束时,缓存也就结束生命周期。在此范围下,缓存的介质是内存。事务可以是数据库事务或者应用事务,每个事务都有独自的缓存。
(2) 应用范围:缓存被应用范围内的所有事务共享的。这些事务有可能是并发访问缓存,因此必须对缓存采取必要的事务隔离机制。缓存的生命周期依赖于应用的生命周期,应用结束时,缓存也就结束了生命周期,二级缓存存在于应用范围。
(3) 集群范围:在集群环境中,缓存被一个机器或者多个机器的进程共享。缓存中的数据被复制到集群环境中的每个进程节点,进程间通过远程通信来保证缓存中的数据的一致性,缓存中的数据通常采用对象的松散数据形式,二级缓存也存在与应用范围。
Hibernate中提供了两级Cache。
第1级别的缓存是Session级别的缓存,即上述事务范围以及应用范围的缓存。这一级别的缓存由Hibernate管理的,一般无需进行干预;缓存的物理介质为内存,由于内存容量有限,必须通过恰当的检索策略和检索方式来限制加载对象的数目。
第2级别的缓存是SessionFactory级别的缓存,属于进程范围或群集范围的缓存。这一级别的缓存可以进行配置和更改,并且可以动态加载和卸载。第2级缓存的物理介质可以是内存和硬盘,因此第2级缓存可以存放大量的数据,数据过期策略的maxElementsInMemory属性值可以控制内存中的对象数目。
Hibernate本身并不提供2级缓存的产品化实现,而是为众多支持Hibernate的第三方缓存组件提供整合接口。
8.hibernate使用步骤
第1步: 先建一个Java工程导入使用Hibernate最小必要包。(看要点2)
第2步:在src创建配置文件hibernate.cfg.xml,放置在src目录中。
hibernate.cfg.xml
<?xml version='1.0' encoding='UTF-8'?> <!DOCTYPE hibernate-configuration PUBLIC "-//Hibernate/Hibernate Configuration DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-configuration-3.0.dtd"> <hibernate-configuration> <session-factory> <property name="connection.driver_class"> com.mysql.jdbc.Driver </property> <property name="connection.url"> jdbc:mysql://127.0.0.1:3306/hib </property> <property name="connection.username">root</property> <property name="connection.password">1234</property> <property name="dialect"> org.hibernate.dialect.MySQLDialect </property> <mapping resource="cn/hncu/domain/Student.hbm.xml"/> </session-factory> </hibernate-configuration>
第3步:编写一个会话工厂类。通过会话工厂类产生一个会话Session对象。Session对象是Hibernate的核心。任何对数据库操作都在会话中进行的。
HibernateSessionFactory.java
package cn.hncu.hib; import org.hibernate.HibernateException; import org.hibernate.SessionFactory; import org.hibernate.cfg.Configuration; import org.hibernate.classic.Session; public class HibernateSessionFactory { private static String configFile = "/hibernate.cfg.xml"; private static Configuration config = new Configuration(); private static SessionFactory sessionFactory =null; private static final ThreadLocal<Session> t = new ThreadLocal<Session>(); static{ try { config.configure(configFile); sessionFactory = config.buildSessionFactory(); } catch (HibernateException e) { e.printStackTrace(); } } public static Session getSession() throws HibernateException{ Session session = t.get(); if(session == null || !session.isOpen()){ if(sessionFactory==null){ rebuildSessionFactory(); } session = (sessionFactory!=null) ? sessionFactory.openSession() : null; t.set(session); } return session; } private static void rebuildSessionFactory() { try { config.configure(configFile); sessionFactory = config.buildSessionFactory(); } catch (HibernateException e) { e.printStackTrace(); } } //关闭与数据库的会话 public static void closeSession() throws HibernateException{ Session session = t.get(); t.set(null); if(session!=null){ session.close(); } } }
第4步:编写POJO类以及映射文件。
POJO类Student.java
package cn.hncu.domain; public class Student { private String studId; private String studName; private Integer age; public String getStudId() { return studId; } public void setStudId(String studId) { this.studId = studId; } public String getStudName() { return studName; } public void setStudName(String studName) { this.studName = studName; } public Integer getAge() { return age; } public void setAge(Integer age) { this.age = age; } }
Student.hib.xml
<?xml version="1.0" encoding="utf-8"?> <!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD 3.0//EN" "http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd"> <hibernate-mapping package="cn.hncu.domain"> <class name="Student" table="students" catalog="hib2"> <id name="studId" type="java.lang.String"> <column name="id" length="8"></column> </id> <property name="studName" type="java.lang.String"> <column name="name" length="40" /> </property> <property name="age" type="java.lang.Integer"> <column name="age" /> </property> </class> </hibernate-mapping>
第5步:使用















 12万+
12万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









