







前言
随着自动化、智能化技术在各行各业获得了广泛应用,化学实验室领域也不可避免的迎来了变革。视觉检测是自动化和智能化的基础,本文将介绍化学实验室常见物体的COCO格式的实例分割数据集的制作方法,后续将使用本文制作好的数据集,进行Mask-RCNN模型的训练和预测,用于检测我们自己的物体。
1. 本文使用的开发环境
Win10,64位+RTX3090
Visual Studio 2017
Python 3.6.13
CUDA 11.3.0+cuDNN 8.2.1
pytorch 1.10.0, torchvision 0.11.1
labelme 5.0.1, fiftyone 0.15.1
mmdetection 2.25.0
2. COCO格式的化学实验室常见物体数据集制作
Labelme数据集标注和COCO类型数据集转换可参考:
通过labelme制作coco格式数据集,并使用mask r-cnn训练_rick_M34的博客-CSDN博客_labelme2coco.py
labelme标注实例实例分割数据并转为COCO格式/VOC格式_ayiya_Oese的博客-CSDN博客_实例分割标注
我们需要自行收集化学实验室里需要被检测的物体的照片,比如烧瓶、烧杯、96孔板等等器材,然后再按下述步骤进行数据集制作:
step1,在项目COCO_style_dataset_IC(你可以改为自己的项目名称)的目录中建立如下的文件夹列表:

将自己的所有需要标注的图像文件放入images/total2019文件夹,注意图像文件名中最好不要有中文字符存在,避免后续程序运行出现异常。
step2,用Labelme对上述文件夹内的图像进行标注,我的图像里有2类检测对象flask和96-well plate,后面打算训练maskRCNN做实例分割检测。用Labelme里的Create Polygons将目标的轮廓标注出来,添加相应的标签即可。

注意一张图片里的多个同类目标,仍然以相同的标签命名,如下所示:

每张图片的标注完成后,都会生成相应的json格式的文件,内部除了含有标注信息外,还保存有整张图像数据。如下图所示:
然后,将上述文件夹内的json文件剪切到label/total2019文件夹内,如下图所示:
step3,通过creat_txt.py生成val2019.txt,train2019.txt,test2019.txt, trainval2019.txt。
creat_txt.py
# !/usr/bin/python
# -*- coding: utf-8 -*-
import os
import random
trainval_percent = 0.8 # 验证集+训练集占总比例多少
train_percent = 0.7 # 训练数据集占验证集+训练集比例多少
jsonfilepath = 'labelme/total2019'
txtsavepath = './'
total_xml = os.listdir(jsonfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('./trainval2019.txt', 'w')
ftest = open('./test2019.txt', 'w')
ftrain = open('./train2019.txt', 'w')
fval = open('./val2019.txt', 'w')
for i in list:
name = total_xml[i][:-5] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
训练集+验证集占总比例,以及训练集数据占训练集+验证集比例,可通过trainval_percent和train_percent调整。
step4,通过classify.py程序将json文件与图片分类。
该步骤将按照step3生成的val2019.txt,train2019.txt,test2019.txt文件,将图像和json文件归到相应的文件夹内。运行完成后,以下文件夹内将存入相应的文件。

classify.py
import shutil
import cv2 as cv
sets=['train2019', 'val2019', 'test2019']
for image_set in sets:
image_ids = open('./%s.txt'%(image_set)).read().strip().split()
for image_id in image_ids:
img = cv.imread('images/total2019/%s.jpg' % (image_id))
json='labelme/total2019/%s.json'% (image_id)
cv.imwrite('images/%s/%s.jpg' % (image_set,image_id), img)
cv.imwrite('labelme/%s/%s.jpg' % (image_set,image_id), img)
shutil.copy(json,'labelme/%s/%s.json' % (image_set,image_id))
print("完成")
step5,通过labelme2coco_new.py生成train2019.json, test2019.json, val2019.json。
首先,在目录下建立labels.txt文件,内含目标类别信息(前两行__ignore__和_background_不要删掉)。以我的数据为例,含有2类物体,分别为flask和96-well plate:

然后修改labelme2coco_new.py文件内的input_dir, output_dir参数,使之在输出目录生成相应的JPEGImages文件夹、Visualization文件夹和annotations.json文件。

labelme2coco_new.py
#!/usr/bin/env python
import argparse
import collections
import datetime
import glob
import json
import os
import os.path as osp
import sys
import uuid
import imgviz
import numpy as np
import labelme
try:
import pycocotools.mask
except ImportError:
print("Please install pycocotools:\n\n pip install pycocotools\n")
sys.exit(1)
def main():
#parser = argparse.ArgumentParser(
# formatter_class=argparse.ArgumentDefaultsHelpFormatter
#)
#parser.add_argument("input_dir", help="input annotated directory")
#parser.add_argument("output_dir", help="output dataset directory")
#parser.add_argument("--labels", help="labels file", required=True)
#parser.add_argument(
# "--noviz", help="no visualization", action="store_true"
#)
#args = parser.parse_args()
input_dir = './labelme/train2019/'
output_dir = './annotations/train2019/'
labels = 'labels.txt'
noviz = False
if osp.exists(output_dir):
print("Output directory already exists:", output_dir)
sys.exit(1)
os.makedirs(output_dir)
os.makedirs(osp.join(output_dir, "JPEGImages"))
if not noviz:
os.makedirs(osp.join(output_dir, "Visualization"))
print("Creating dataset:", output_dir)
now = datetime.datetime.now()
data = dict(
info=dict(
description=None,
url=None,
version=None,
year=now.year,
contributor=None,
date_created=now.strftime("%Y-%m-%d %H:%M:%S.%f"),
),
licenses=[dict(url=None, id=0, name=None,)],
images=[
# license, url, file_name, height, width, date_captured, id
],
type="instances",
annotations=[
# segmentation, area, iscrowd, image_id, bbox, category_id, id
],
categories=[
# supercategory, id, name
],
)
class_name_to_id = {}
for i, line in enumerate(open(labels).readlines()):
class_id = i - 1 # starts with -1
class_name = line.strip()
if class_id == -1:
assert class_name == "__ignore__"
continue
class_name_to_id[class_name] = class_id
data["categories"].append(
dict(supercategory=None, id=class_id, name=class_name,)
)
out_ann_file = osp.join(output_dir, "annotations.json")
label_files = glob.glob(osp.join(input_dir, "*.json"))
for image_id, filename in enumerate(label_files):
print("Generating dataset from:", filename)
label_file = labelme.LabelFile(filename=filename)
base = osp.splitext(osp.basename(filename))[0]
out_img_file = osp.join(output_dir, "JPEGImages", base + ".jpg")
img = labelme.utils.img_data_to_arr(label_file.imageData)
imgviz.io.imsave(out_img_file, img)
data["images"].append(
dict(
license=0,
url=None,
#file_name=osp.relpath(out_img_file, osp.dirname(out_ann_file)),
file_name=base + ".jpg",
height=img.shape[0],
width=img.shape[1],
date_captured=None,
id=image_id,
)
)
masks = {} # for area
segmentations = collections.defaultdict(list) # for segmentation
for shape in label_file.shapes:
points = shape["points"]
label = shape["label"]
group_id = shape.get("group_id")
shape_type = shape.get("shape_type", "polygon")
mask = labelme.utils.shape_to_mask(
img.shape[:2], points, shape_type
)
if group_id is None:
group_id = uuid.uuid1()
instance = (label, group_id)
if instance in masks:
masks[instance] = masks[instance] | mask
else:
masks[instance] = mask
if shape_type == "rectangle":
(x1, y1), (x2, y2) = points
x1, x2 = sorted([x1, x2])
y1, y2 = sorted([y1, y2])
points = [x1, y1, x2, y1, x2, y2, x1, y2]
if shape_type == "circle":
(x1, y1), (x2, y2) = points
r = np.linalg.norm([x2 - x1, y2 - y1])
# r(1-cos(a/2))<x, a=2*pi/N => N>pi/arccos(1-x/r)
# x: tolerance of the gap between the arc and the line segment
n_points_circle = max(int(np.pi / np.arccos(1 - 1 / r)), 12)
i = np.arange(n_points_circle)
x = x1 + r * np.sin(2 * np.pi / n_points_circle * i)
y = y1 + r * np.cos(2 * np.pi / n_points_circle * i)
points = np.stack((x, y), axis=1).flatten().tolist()
else:
points = np.asarray(points).flatten().tolist()
segmentations[instance].append(points)
segmentations = dict(segmentations)
for instance, mask in masks.items():
cls_name, group_id = instance
if cls_name not in class_name_to_id:
continue
cls_id = class_name_to_id[cls_name]
mask = np.asfortranarray(mask.astype(np.uint8))
mask = pycocotools.mask.encode(mask)
area = float(pycocotools.mask.area(mask))
bbox = pycocotools.mask.toBbox(mask).flatten().tolist()
data["annotations"].append(
dict(
id=len(data["annotations"]),
image_id=image_id,
category_id=cls_id,
segmentation=segmentations[instance],
area=area,
bbox=bbox,
iscrowd=0,
)
)
if not noviz:
viz = img
if masks:
listdata_labels = []
listdata_captions = []
listdata_masks = []
for (cnm, gid), msk in masks.items():
if cnm in class_name_to_id:
listdata_labels.append(class_name_to_id[cnm])
listdata_captions.append(cnm)
listdata_masks.append(msk)
listdata = zip(listdata_labels, listdata_captions, listdata_masks)
labels, captions, masks = zip(*listdata)
#labels, captions, masks = zip(*[(listdata_labels, listdata_captions, listdata_masks)])
#print(len(masks))
#labels, captions, masks = zip(
# *[
# (class_name_to_id[cnm], cnm, msk)
# for (cnm, gid), msk in masks.items()
# if cnm in class_name_to_id
# ]
#)
viz = imgviz.instances2rgb(
image=img,
labels=labels,
masks=masks,
captions=captions,
font_size=15,
line_width=2,
)
out_viz_file = osp.join(
output_dir, "Visualization", base + ".jpg"
)
imgviz.io.imsave(out_viz_file, viz)
with open(out_ann_file, "w") as f:
json.dump(data, f)
if __name__ == "__main__":
main()
总共要修改参数和运行程序3次(train2019, val2019, test2019),最后得到如下图所示的文件。

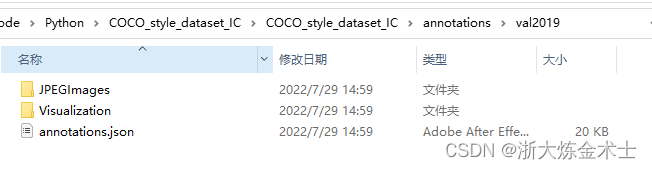

至此完成了COCO类型数据集的制作。
如果想要预览我们标注的数据集,可以查看Visulization文件夹内的图片。也可以使用fiftyone,具体代码见view_coco_style_data.py文件,只需要把文件里的data_path和labels_path设置为上图JPEGImages文件夹路径和annotations.json文件文件路径,然后运行程序即可。
view_coco_style_data.py
# pip install urllib3==1.25.11
# 降版本,否则报错
import fiftyone as fo
import fiftyone.zoo as foz
dataset = fo.Dataset.from_dir(
dataset_type=fo.types.COCODetectionDataset,
label_types = ["segmentations"],
data_path=r'E:\Code\Python\COCO_style_dataset_IC\COCO_style_dataset_IC\annotations\train2019\JPEGImages',
labels_path=r'E:\Code\Python\COCO_style_dataset_IC\COCO_style_dataset_IC\annotations\train2019\annotations.json',
)
session = fo.launch_app(dataset, port = 5151) # 没有指定port则默则5151
session.wait() # 官网给的示例没有这一句,记得加上,不然程序不会等待,在网页中看不到我们要的效果制作好的数据集预览效果如下图所示:

















 4931
4931











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









