









一.前言
你知道吗?能用stable diffusion画不能动的好看小姐姐已经out(落伍)了,现在大家画的小姐姐已经可以动起来了哦。
有人说,之前也可以啊。
是,之前的当然也可以,但是都需要有参考视频,某种意义上,只是把原有的视频换一种滤镜使之风格化,还不能称得上是无中生地创作视频。
而Runway之类的工具,的确是可以创作视频,但是并没有开源,无法本地化,还需要付钱才能使用。
而现在,利用animatediff,作者直接开源了代码并放在github上,我们也可以直接本地就可以从无到有生成一段视频(动图),而无需任何参考视频,只需要提示词就能完成。

Animatediff-github官方参考视频1

Animatediff-github官方参考视频2
现在也支持直接使用stable-diffusion-webui通过安装插件的方式即可生成属于你自己的会动的动图。
二.教程
下面我们来教大家,如何使用stable diffusion webui来创建会动的图片。(用comfyi的同学可以参考https://github.com/ArtVentureX/comfyui-animatediff的用法介绍)
1.更新sdwebui和controlnet
(1)把你的stable-diffusion-webui 升级到1.60或者以上。版本号在sdwebui网页底部即可看到。(如果版本号满足1.60或者以上则无需升级,如果不满足则可以用git pull之类的方式升级。

(2)把controlnet升级到1.1.410以上,这个直接在controlnet小窗的左上角就能看到,如果不满足的话,更新或者下载最新controlnet zip包解压覆盖原有controlnet extension文件夹即可。
2.安装了animatediff插件
可以直接下载https://github.com/continue-revolution/sd-webui-animatediff 的zip 代码包,再解压到stable-diffusion-webui/extension文件夹下面。
也可以用上述地址在“extensions拓展“-“install from url从网址安装“中输入地址安装。
也可以从拓展extensions-avaliable里面安装。
安装好后,别忘了启用插件。
现在,你就可以从文生图页面或者图生图页面下方找到并使用animatediff插件了。

3.下载Animatediff模型
在https://huggingface.co/guoyww/animatediff/tree/main下载mm_sd_v15_v2.ckpt模型。放到stable-diffusion-webui/extensions/sd-webui-animatediff/model文件夹下面。
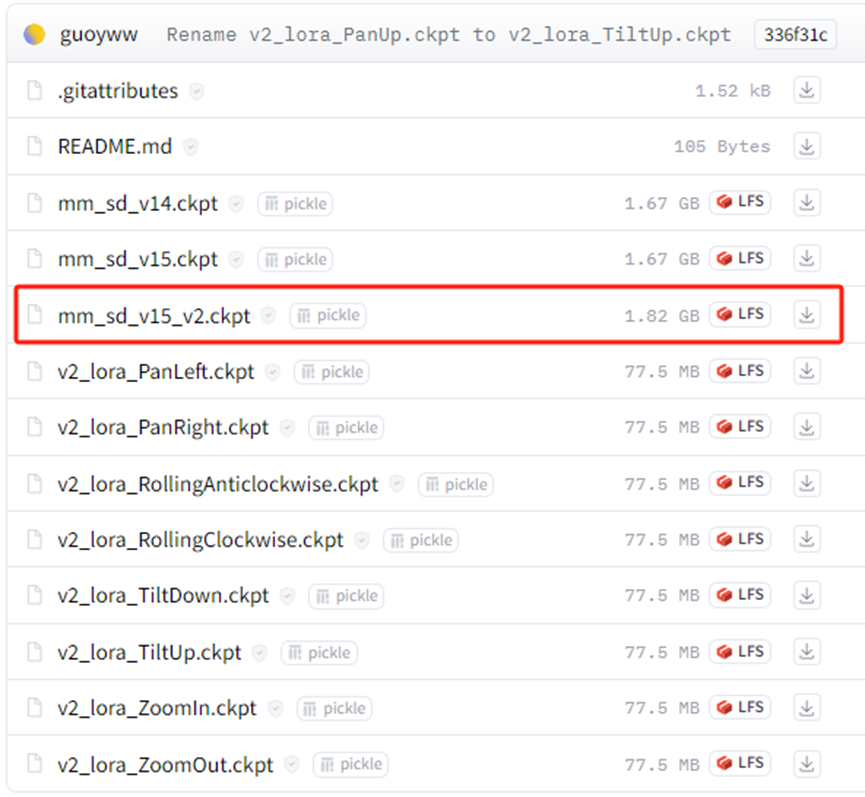
(Lora模型非必须下载,但下载之后,不同的lora可以控制不同的镜头,比如镜头往左,往下,放大,缩小之类。有需要的同学也可以尝试,像使用普通lora时在正向提示词区域引用即可。)
4.开始生成
基础模型用基于SD1.5的都行,SDXL貌似暂时还不支持。
正负提示词我们按照正常的习惯写就行。分辨率不要太大,第一次先用512x512生成。(后续生成没问题再慢慢放大尺寸)
Animatediff这里,记得选择刚刚下载的mmv15v2模型。其他的参数初次使用不建议动,用默认参数生成一次。
(其他参数说明请参考https://github.com/continue-revolution/sd-webui-animatediff#webui-parameters)

然后等待生成,大概一分多钟(注意:不同显卡速度可能不同),就能生成一个8帧/秒,总共16帧(2秒)的gif动图了。

图像生成后,会自动保存gif到stable-diffusion-webui\outputs\txt2img-images\AnimateDiff里面。
可以进入文件夹里用支持gif的图片查看器查看。
三.其他说明
1.多次生成短gif比单次生成长gif效果要好
目前也尝试过把总帧数设置较大,比如64帧(8秒)或者以上,但是太长的话就会失去连续性,一般2-4秒的动图连续性保持较好。因此可以用图生图模块控制人物主体或者关键帧去生成一段一段的短视频再拼接起来,其结果比单独生成一段长的视频效果要好。
2.雪花问题
有时候乱改参数有时候会生成很多雪花点无意义的动图,这时候改回默认参数没用,建议是重启sdwebui,即可解决问题。
3.展望
目前生成视频当然还很初级,至于说更长更精致的视频,甚至电影级的长视频距离还远着。
不过由于代码开源,目前已经有一些调教或者参考animatediff后封装的应用网站出现了,比如pika,genmo,moonvalley之类的很多工具做出来的效果已经渐渐越做越好了。

关于AI绘画技术储备
学好 AI绘画 不论是就业还是做副业赚钱都不错,但要学会 AI绘画 还是要有一个学习规划。最后大家分享一份全套的 AI绘画 学习资料,给那些想学习 AI绘画 的小伙伴们一点帮助!
对于0基础小白入门:
如果你是零基础小白,想快速入门AI绘画是可以考虑的。
一方面是学习时间相对较短,学习内容更全面更集中。
二方面是可以找到适合自己的学习方案
包括:stable diffusion安装包、stable diffusion0基础入门全套PDF,视频学习教程。带你从零基础系统性的学好AI绘画!
需要的可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包 (全套教程文末领取哈)
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.AIGC视频教程合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

这份完整版的学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









