







目录
Rosemblatt感知器

-
我们应该如何评估误差?
第一想到:通过差值来评价误差
但是事实上是不合理的,比如:

机智如你:会想到用绝对差来评定绝对值
但是实际上绝对值不好用代码来处理
平方误差:平方误差越小就说明偏离的事实就越小,小蓝的思考就越接近真相

将w和平方误差的关系画出来就是一个开口向上的一元二次方程
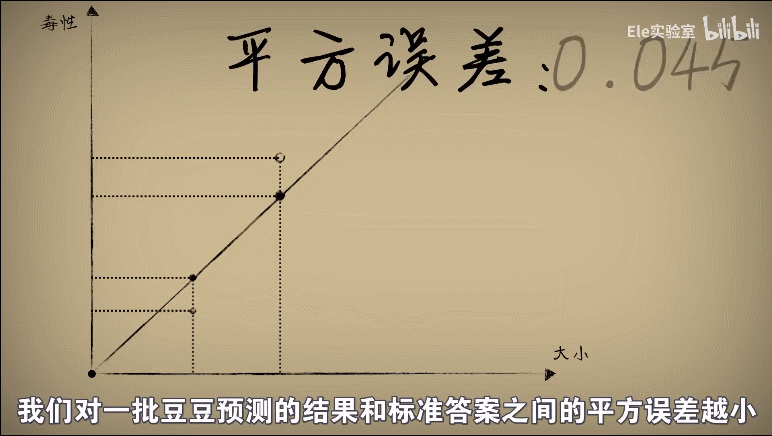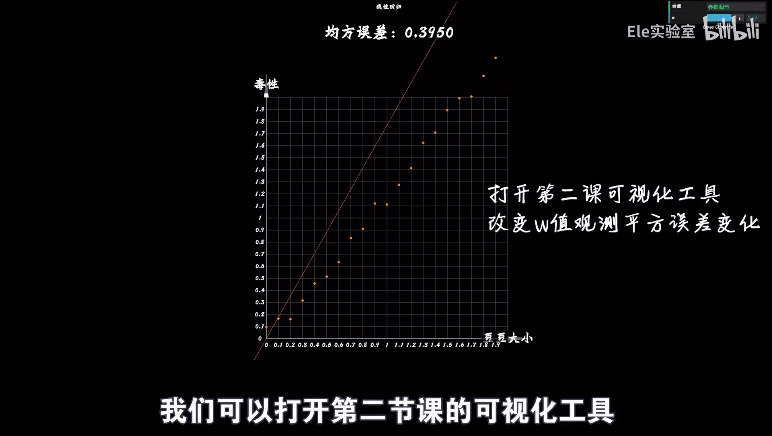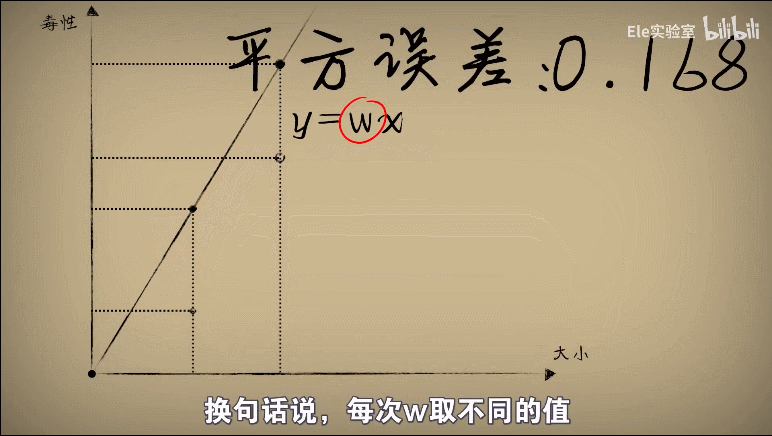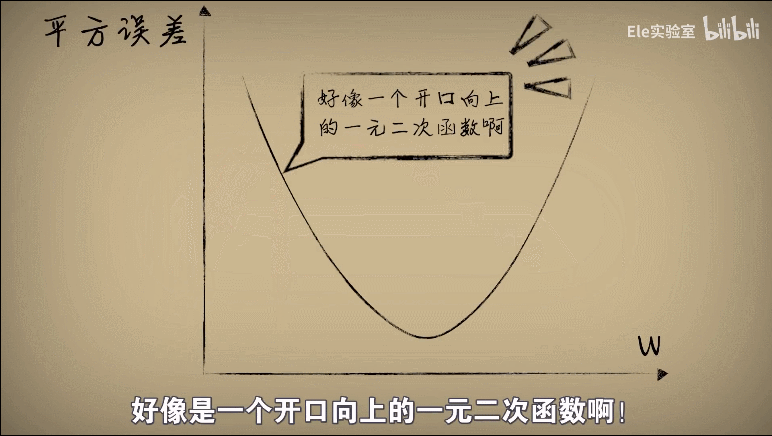
证明:

研究一组豆豆太复杂,先研究一个豆豆的误差:

前面研究了一个豆豆的误差和w之间的关系确实是一元二次函数,那么如果是一组豆豆的误差会是怎样的呢?
整体豆豆的误差就是将单个豆豆的误差加起来然后求平均值
整理公式发现误差e和w之间的关系仍然是一个标准开口向上的一元二次函数(a,b,c都是固定的值)
注意:
下面公式就是均方误差:将所有误差值累加起来,然后求平均值,这就是预测函数在整体样本上的误差
之前说的单个豆豆其实是它的一个特例(样本只有一个,m=1的情况)
实际上样本不论等于几,这个均分误差e和w的关系都会形成一个开口向上的抛物线



概率和统计
如何得知一枚灌有水银的硬币正面朝上和反面朝上的概率:
事物出现的频率收敛于它的概率

回归分析
回归分析:
同样的道理我们设计小蓝大脑的时候实际上也是做抛掷一枚不确定硬币的事情
一开始我们猜想一个w,然后统计出大量的数据(大小和毒性), 去评估我们的w合不合适
这实际上就是数理统计里面的一个重要的分支-回归分析
最小二乘法
最小二乘法:
而我们评估的标准是"均方误差",并试图让他最小,也就是回归分析的最小二乘法
代价函数
代价函数:
此时此刻,如果我们把函数看作处理问题的机器
那么事情从原先的机器输入数据,得到结果变成了用很多观察的数据去评估这个函数机器到底在不在行
原先的自变量x和因变量y变成了从环境中观测到的大量已知数,而我们把w是作为自变量,误差e作为因
变量,也就形成一个新的函数叫做代价函数。
这个所谓的"代价函数"展现出,当参数w取不同值的时候,对于环境中的问题数据预测时产生的不同误差。
而利用这个"代价函数"的最低点的w值,把它放回到预测函数,这时候预测函数也就很好完成了对数据的
拟合。
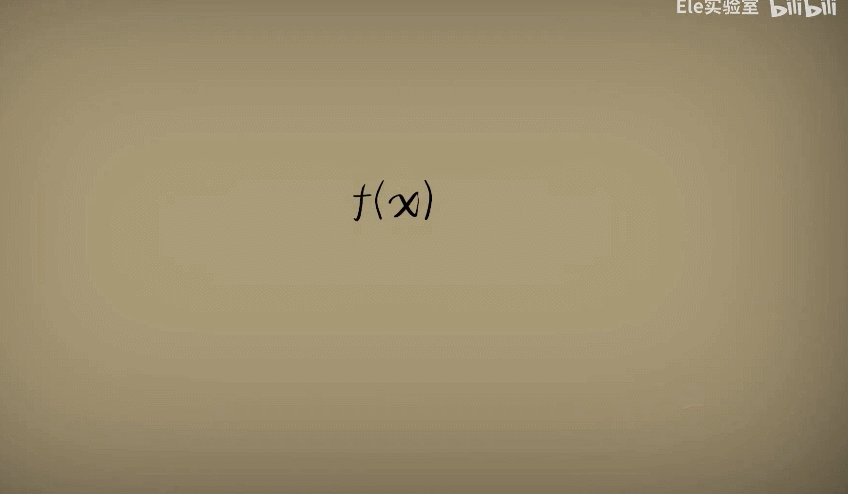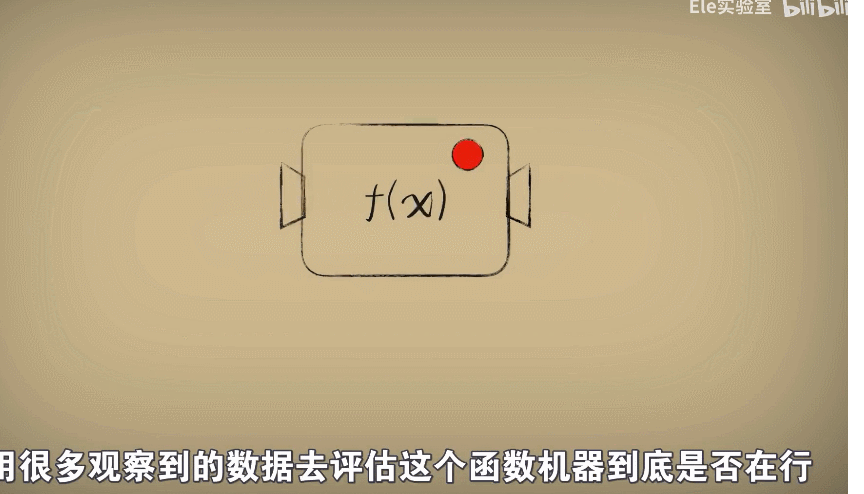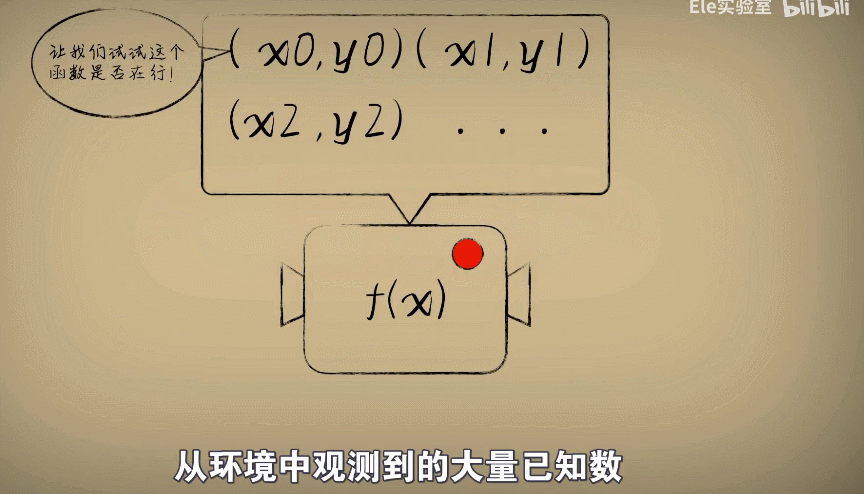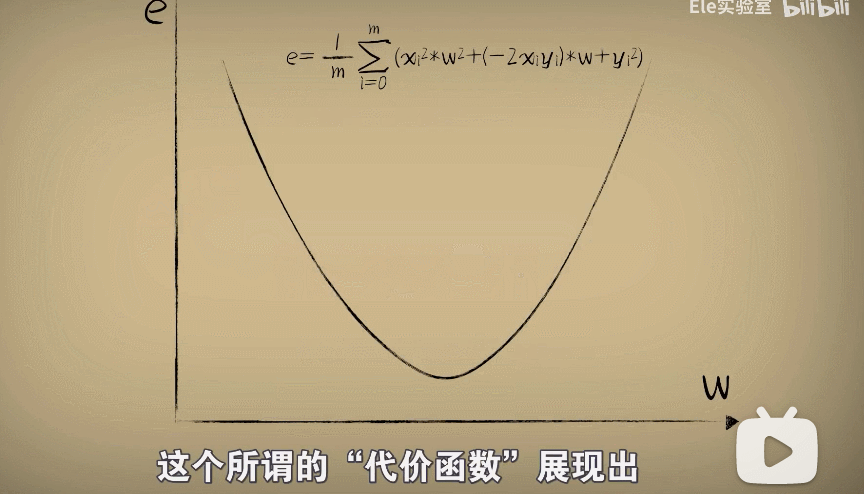
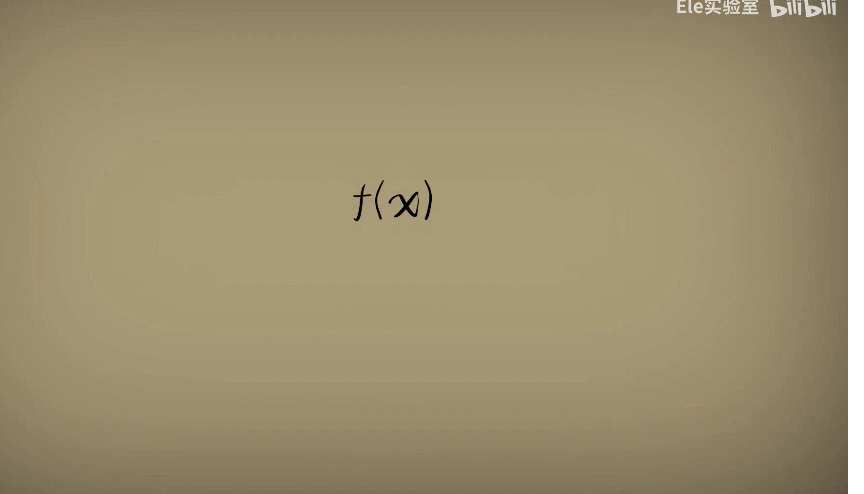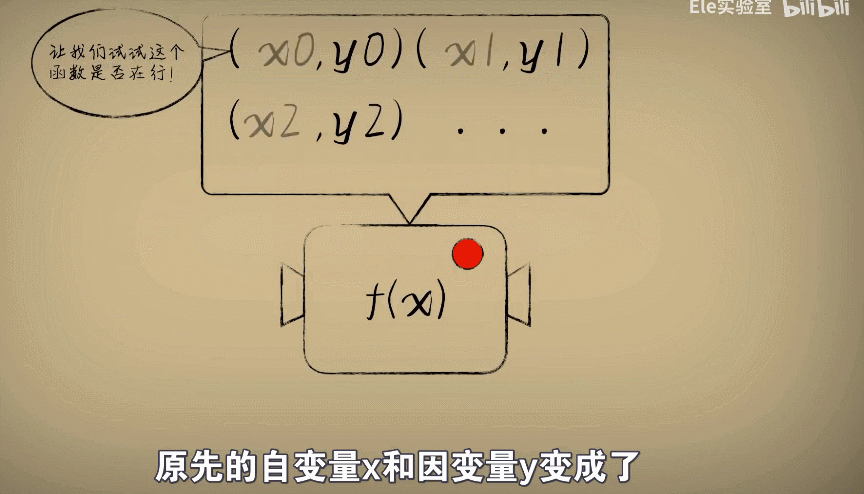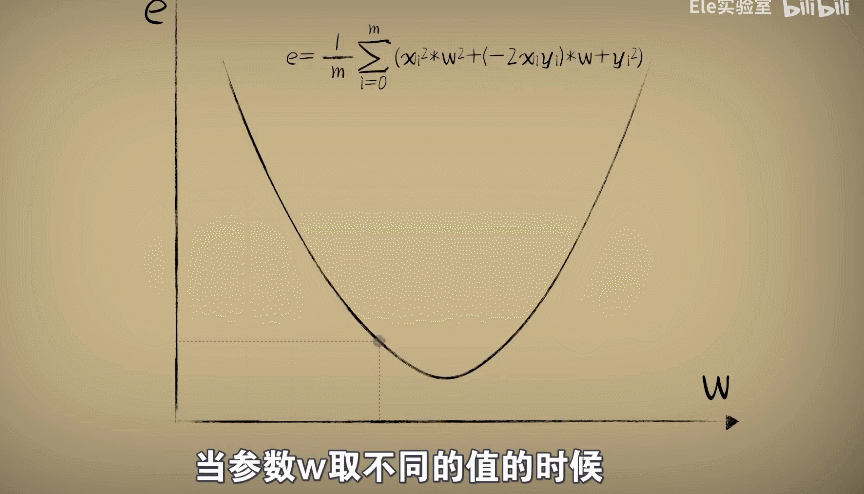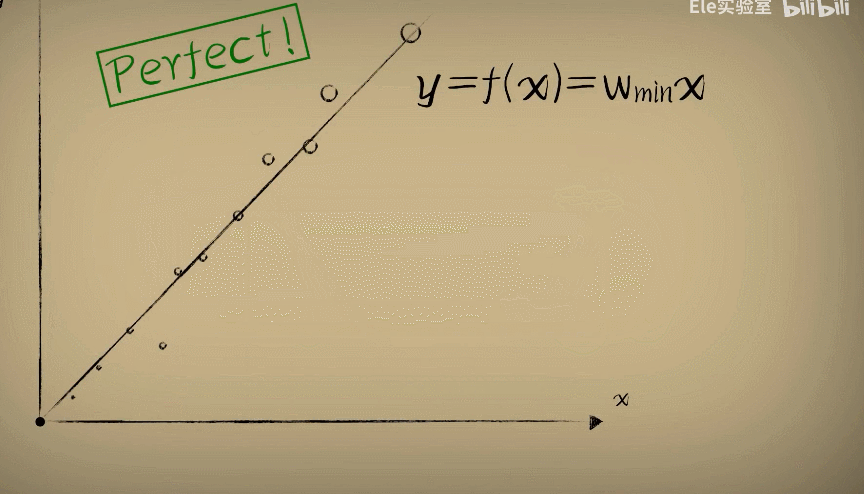
所以大家要千万时刻牢记:
在预测函数中w作为参数,x是作为自变量输入,y作为因变量输出
这是我们最终要得到预测函数问题的函数
而在研究函数的时候,x和y都是观测统计出来的已知数,成为了代价函数的已知参数部分
而w成为了自变量,误差代价e是因变量
这是我们用来分析并改进预测函数的辅助函数

如何挪动到最低点
一开始设置w是0.1,距离合适的最低点还有一段距离
究竟如何让机器把w向最低点挪动呢?


正规方程

但是这样合适吗?
如果数据量不大的话,这很合适。但是机器学习都是处理海量数据的,我们这里算一笔账:
如果样本是1百万条数据,每条数据用单精度的浮点型数表示,那这里的分母部分的x就需要做1百万次加
法和乘法的运算
实际应用中输入x往往不会是一个特征数值,更一般的情况是一个特征向量,比如1000个维度,那么
运算次数就是10亿次,而在现代神经网络中为了加快运算的速度一般都会采用并行计算的方式,也就是
一次性把它们都算出来,这更够劲。。。















 846
846











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









