






问题背景:
greenplum集群不增加segment节点,只在每个节点上增加segment实例个数。
记录:
现在虚拟机有三台,一台master节点(hadoop106),两个segment机器(hadoop107 hadnoop108),每个segment上有3个primary节点和对应的mirror节点。现在计划在现有集群上进行segment instance扩容,下边的例子是每台机器上只增加一个节点。即集群由之前的6个segment instance 变为8个segment instance。
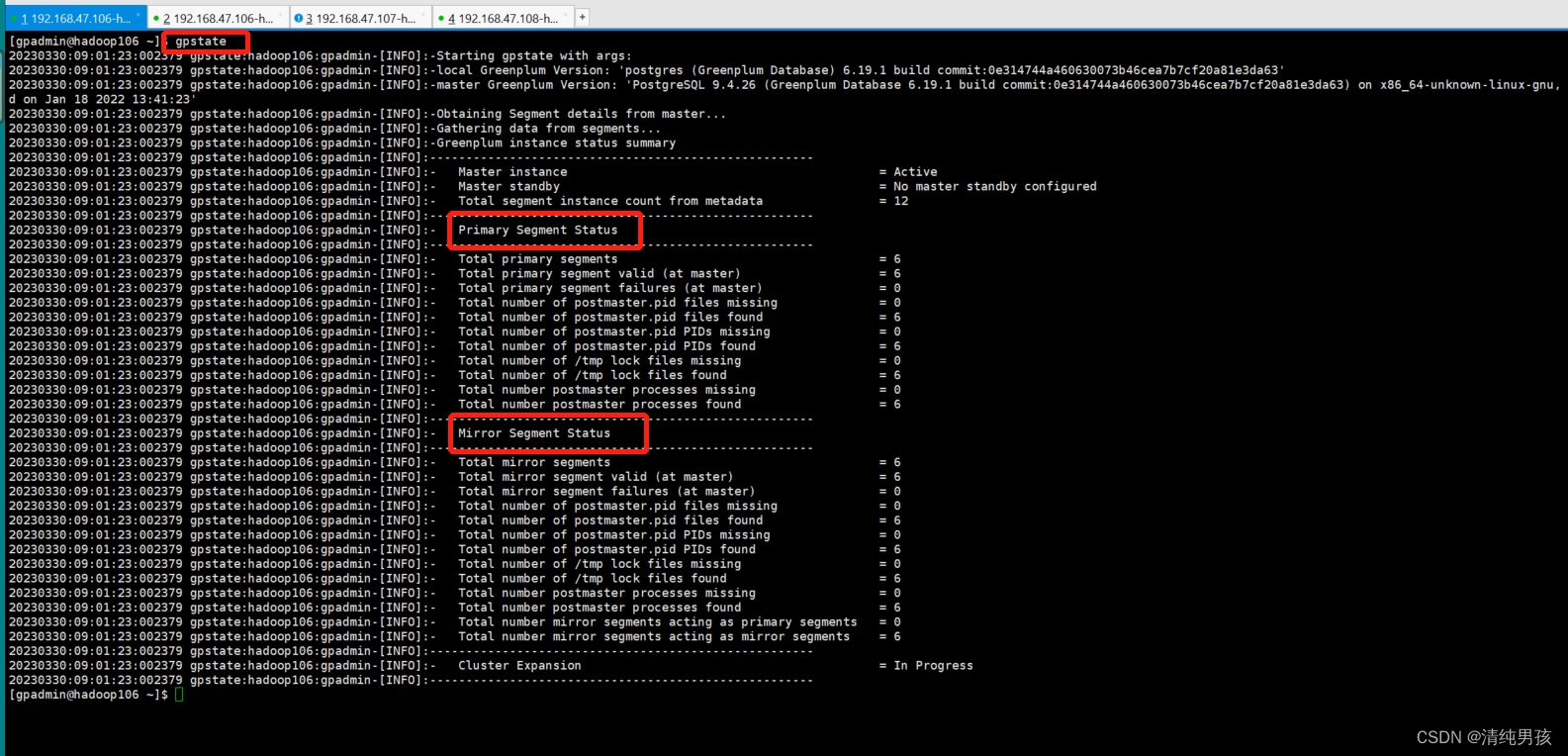
查看集群状态
[gpadmin@hadoop106 ~]$ gpstart
截图如下
查看当前数据存储目录:(每个人的不一样,注意路径)
上面的目录的所属组和用户均为gpadmin:gpamdin
创建新的segment instance数据存储目录,这里使用 mkdir data3作为新目录
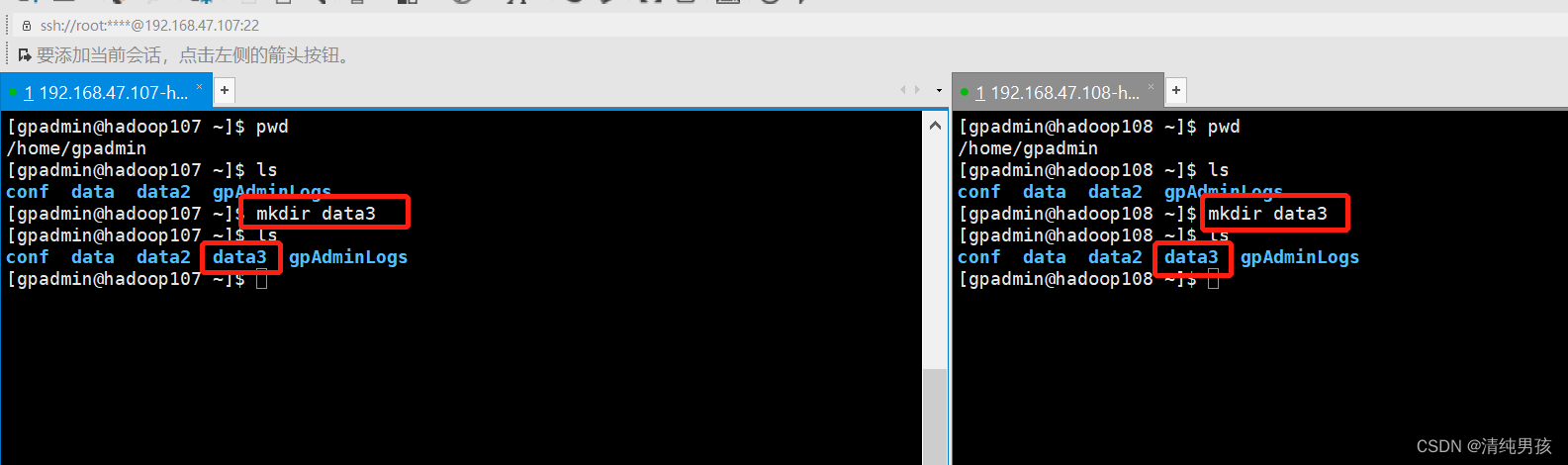
在/data3下创建对应的 primary及mirror目录
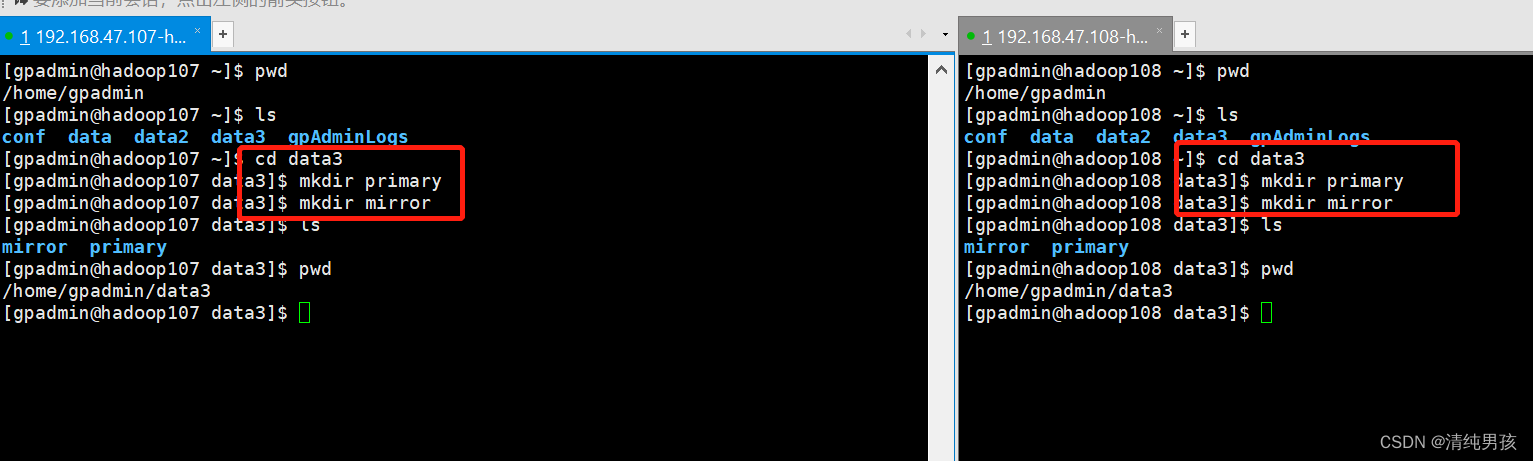
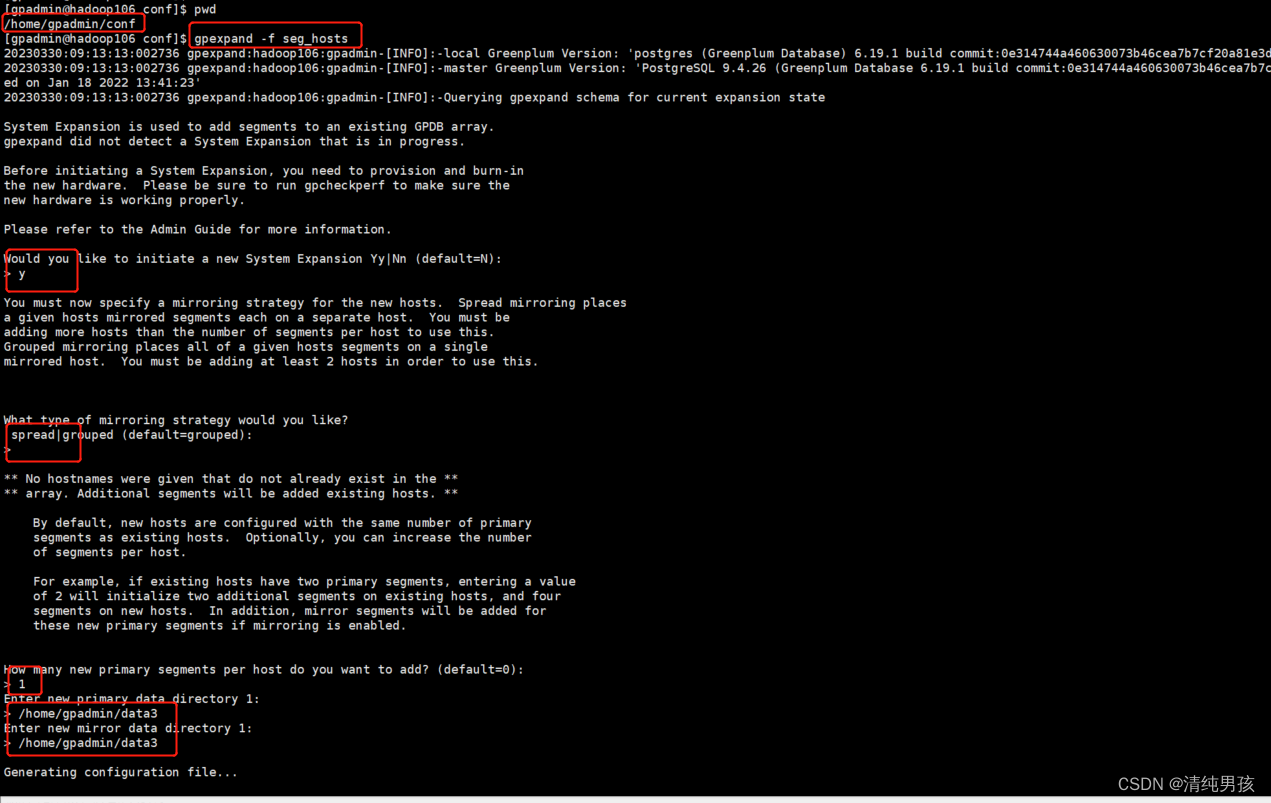
在master主节点进入目录 /home/gpadmin/conf,本案例为hadoop106服务器上执行
[gpadmin@hadoop106 conf]$ cd /home/gpadmin/conf
[gpadmin@hadoop106 ~]$ gpexpand -f seg_hosts
中途需要输入以下操作:第一个是y第二个直接回车选择默认模式就行,第三个第四个是选择新增segment instance的路径,即我们刚刚创建的目录
截图如下
执行成功后会产生下图所示内容
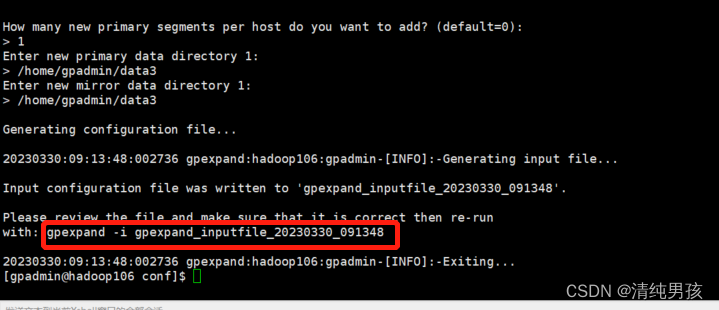
这一步代表初始化成功,查看上述初始化文件
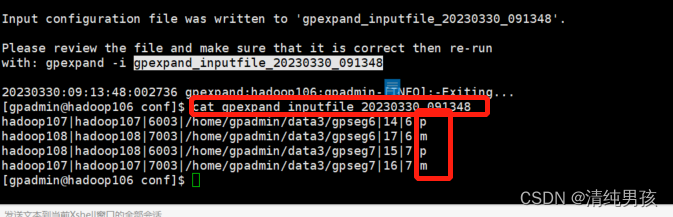
两个服务器hadoop107 hadoop108每个产生了一个primary 节点及对应的mirror节点
初始化Segment并且创建扩容schema
执行命令:gpexpand -i gpexpand_inputfile_20230330_091348
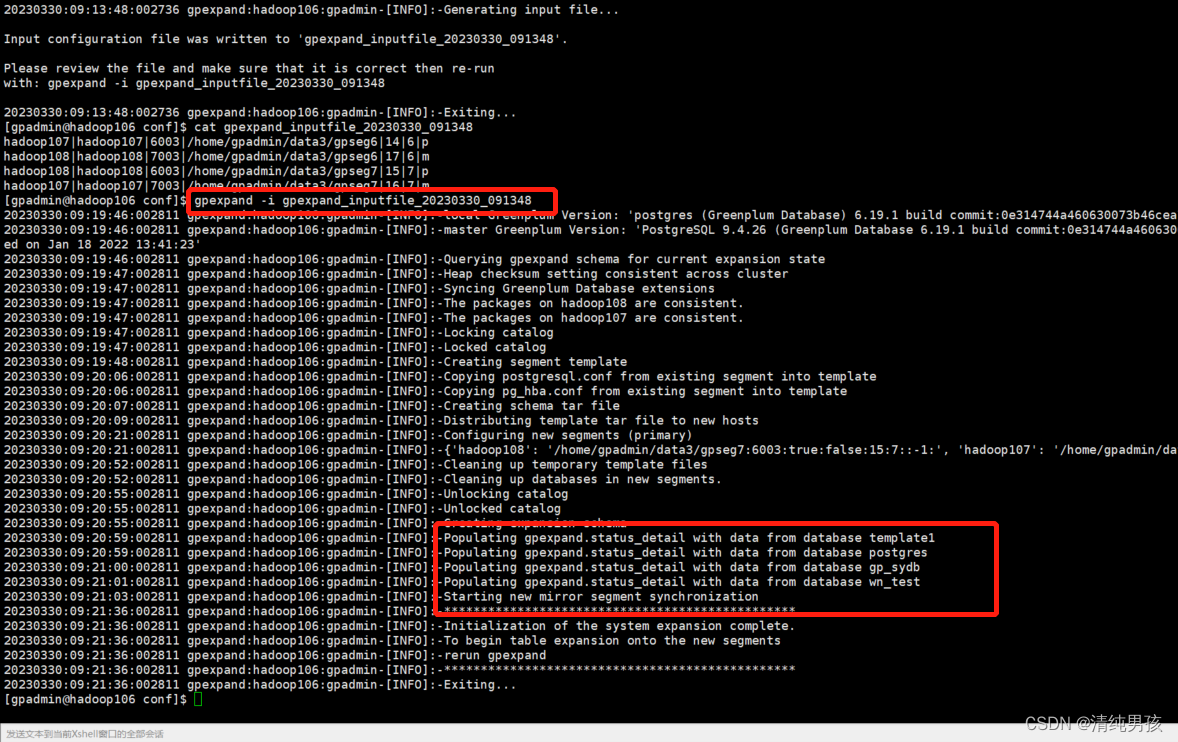
执行命令等待执行成功
使用gpstate验证下,查看segment instance 是否成功增加
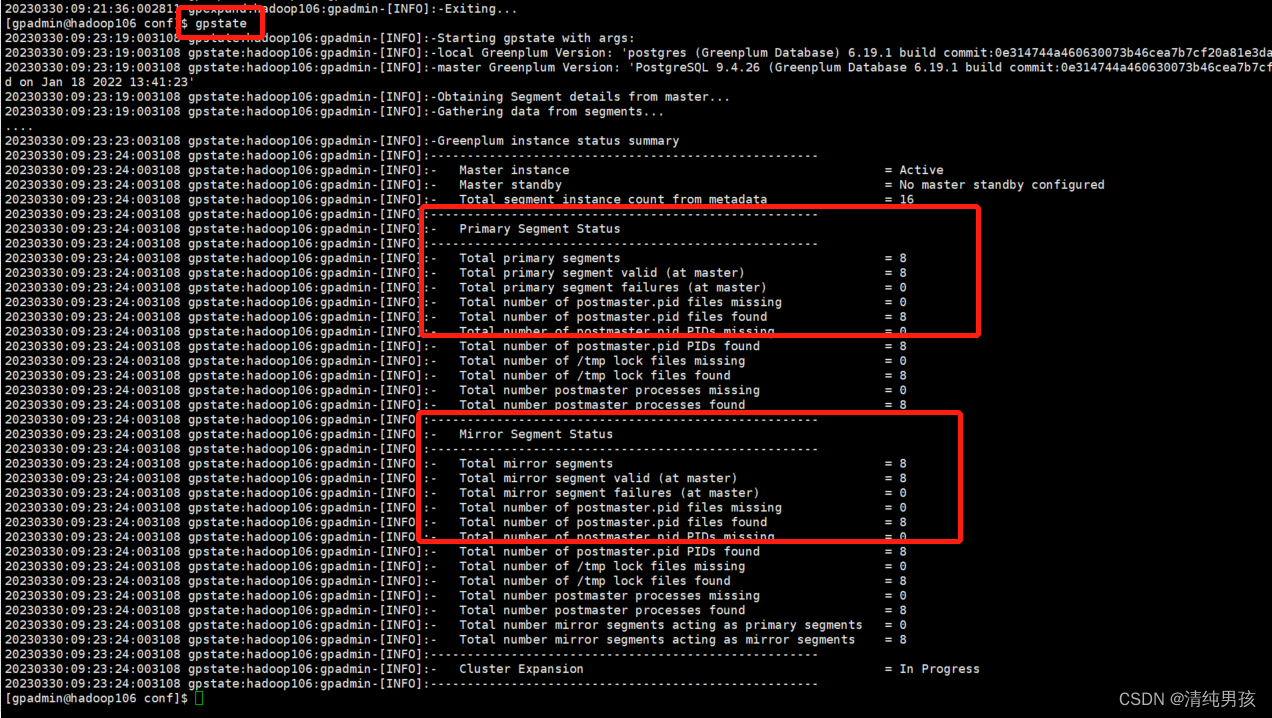
segment instance个数由之前的6个变为8个。实例增加成功,接下来进行数据重新分布。
由于之前有6个segment instance ,表数据分布在6个实例上,截图如下
(wn_test_stu为本人测试表)
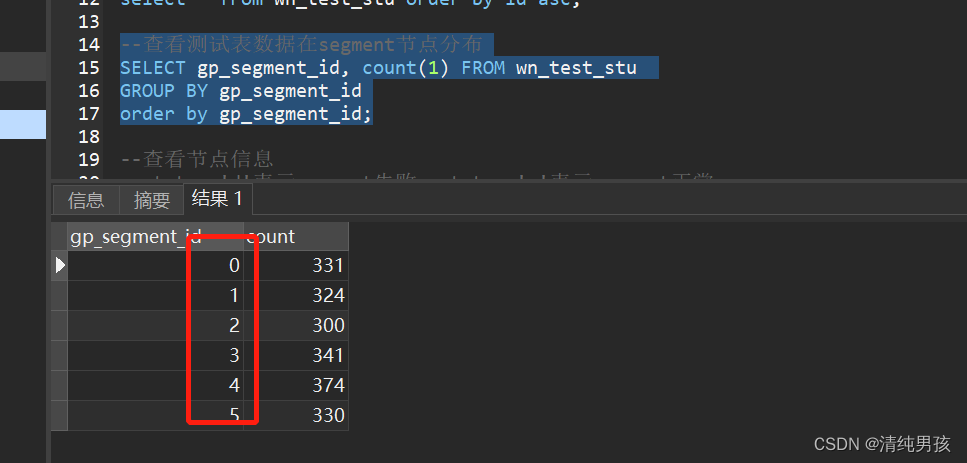
进行数据重新分布
执行命令:gpexpand -d 1:00:00
[gpadmin@hadoop106 conf]$ gpexpand -d 1:00:00

如果数据量很大,可以增加线程
再次查看表数据分布,发现已经重新分布成功
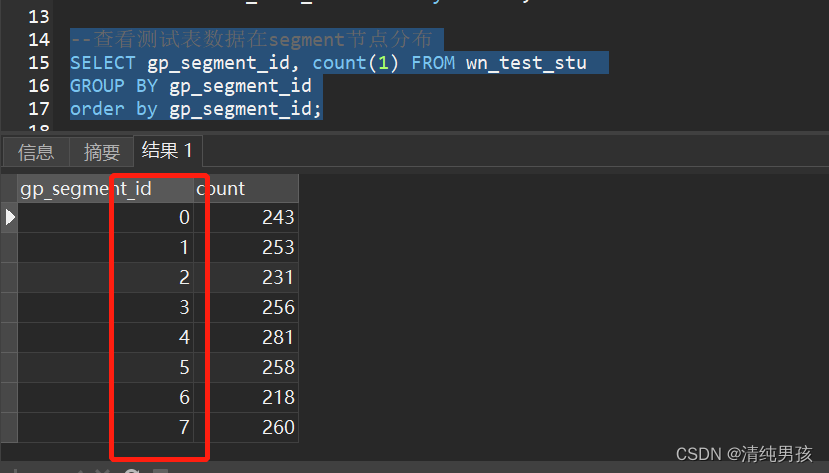
至此,segment instance增加成功。















 7389
7389











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









