







Windows内存管理机制,底层最核心的东西是分页机制。分页机制使每个进程有自己的4G虚拟空间,使我们可以用虚拟线性地址来跑程序。每个进程有自己的工作集,工作集中的数据可以指明虚拟线性地址对应到怎样的物理地址。进程切换的过程也就是工作集切换的过程,如Matt Pietrek所说如果只给出虚拟地址而不给出工作集,那这个地址是无意义的。(见图一)
在分页机制所形成的线性地址空间里,我们对内存进行进一步划分涉及的概念有堆、栈、自由存储等。对堆进行操作的API有HeapCreate、HeapAlloc等。操纵自由存储的API有VirtualAlloc等。此外内存映射文件使用的也应该算是自由存储的空间。栈则用来存放函数参数和局部变量,随着stack frame的建立和销毁其自动进行增长和缩减。
说到这里,也许有人会提出疑问:对x86 CPU分段机制是必须的,分页机制是可选的。为什么这里只提到了分页机制。那么我告诉你分段机制仍然存在,一是为了兼容以前的16位程序,二是Windows毕竟要区分ring 0和ring 3两个特权级。用SoftIce看一下GDT(全局描述表)你基本上会看到如下内容:
GDTbase=80036000 Limit=03FF
0008Code32 Base=00000000 Lim=FFFFFFFF DPL=0 P RE
//内核态driver代码段
0010Data32 Base=00000000 Lim=FFFFFFFF DPL=0 P RW
//内核态driver的数据段
001BCode32 Base=00000000 Lim=FFFFFFFF DPL=3 P RE
//应用程序的代码段
0023Data32 Base=00000000 Lim=FFFFFFFF DPL=3 P RW
//应用程序的数据段
这意味着什么呢?
我们再看一下线性地址的生成过程(见图一)。从中我们应该可以得出结论,如果segmeng base address为0的话,那么这个段可以看作不存在,因为偏移地址就是最终的线性地址。
此外还有两个段存在用于Kernel Processor Control Region和user thread environment block。所以如果你在反汇编时看到MOVECX,FS:[2C]就不必惊讶,怎么这里使用逻辑地址而不是线性地址。在以后涉及异常处理的地方会对此再做说明。

二、从Stack说开去
从我个人的经验看,谈到内存时说堆的文章最多,说stack的最少。我这里反其道而行的原因是stack其实要比堆更重要,可以有不使用堆的程序,但你不可能不使用stack,虽然由于对stack的管理是由编译器确定了的,进而他较少出错。
通过链接开关/STACK:reserve[,commit]可以指定进程主线程的stack大小,当你建立其他线程时如果不指定dwStackSize参数,则也将使用/STACK所指定的值。微软说,如果指定较大的commit值将有利于提升程序的速度,我没验证过,但理应如此。通常并不需要对STACK进行什么设定,缺省的情况下将保留1M空间,并提交两个页(8K for x86)。而1M空间对于大多数程序而言是足够的,但为防止stack overflow有三点需要指出一是当需要非常大的空间时最好用全局数组或用VirtualAlloc进行分配,二是引用传递或用指针传递尺寸较大的函数参数(这点恐怕地球人都知道),三是进行深度递归时一定要考虑会不会产生stack溢出,如果有可能,可以采用我在《递归与goto》一文中提到的办法来仿真递归,这时候可以使用堆或自由存储来代替stack。同时结构化异常被用来控制是否为stack提交新的页面。(这部分写的比较简略因为很多人都写过,推荐阅读Jeffery Ritcher《Windows核心编程》第16章)
下面我们来看一下stack的使用。
假设我们有这样一个简单之极的函数:
int __stdcall add_s(int x,inty)
{
int sum;
sum=x+y;
return sum;
}
这样在调用函数前,通常我们会看到这样的指令。
mov eax,dword ptr [ebp-8]
push eax
mov ecx,dword ptr [ebp-4]
push ecx
此时把函数参数压入堆栈,而stack指针ESP递减,stack空间减小。
在进入函数后,你将会看到如下指令:
push ebp
mov ebp,esp
sub esp,44h
这三句建立stack框架,并减小esp为局部变量预留空间。建立stack框架后,[ebp+*]指向函数参数,[ebp-*]指向局部变量。
另外在很多情况下你会看到如下三条指令
push ebx
push esi
push edi
这三句把三个通用寄存器压入堆栈,这样这三个寄存器就可以用来存放一些变量,进而提升运行速度。
很奇怪,我这个函数根本用不到这三个寄存器,可编译器也生成了上述三条指令。
对stack中内容的读取,是靠基址指针ebp进行的。所以对应于sum=x+y;一句你会看到
mov eax,dword ptr [ebp+8]
add eax,dword ptr [ebp+0Ch]
mov dword ptr [ebp-4],eax
其中[ebp+8]是x,[ebp+0Ch]是y,记住压栈方向为从右向左,所以y要在x上边。
我们再看一下函数退出时的情况:
pop edi
pop esi
pop ebx
mov esp,ebp
pop ebp
ret 8
此时恢复stack框架,使esp与刚进入这个函数时相同,ret8使esp再加8,使esp与没调用这个函数的时候一致。如果使用__cdecl调用规则,则由调用方以类似add esp,8进行清场工作,使stack的大小与未进行函数调用时一致。Stack的使用就这样完全被编译器实现了,只要不溢出就和我们无关,也许也算一种内存的智能管理。最后要补充的两点是:首先stack不像heap会自动扩充,如果你用光了储备,他会准时溢出。其次是不要以为你使用了缺省参数进行链接,你就有1M的stack,看看启动代码你就知道在你拥有stack之前,C Run–Time Library以用去了一小部分stack的空间。
2. 保护模式寻址基础知识
接下来就以32位系统为例,介绍保护模式下,内存中一些地址转换相关的寄存机和数据结构。
2.1 内存地址概念
逻辑地址 :在进行C语言编程中,能读取变量地址值(&操作),实际上这个值就是逻辑地址,也可以是通过malloc或是new调用返回的地址。该地址是相对于当前进程数据段的地址,不和绝对物理地址相干。只有在Intel实模式下,逻辑地址才和物理地址相等(因为实模式没有分段或分页机制,CPU不进行自动地址转换)。应用程序员仅需和逻辑地址打交道,而分段和分页机制对一般程序员来说是完全透明的,仅由系统编程人员涉及。应用程序员虽然自己能直接操作内存,那也只能在操作系统给你分配的内存段操作。一个逻辑地址,是由一个段标识符加上一个指定段内相对地址的偏移量,表示为 [段标识符:段内偏移量]。
线性地址 :是逻辑地址到物理地址变换之间的中间层。程序代码会产生逻辑地址,或说是段中的偏移地址,加上相应段的基地址就生成了一个线性地址。如果启用了分页机制,那么线性地址能再经变换以产生一个物理地址。若没有启用分页机制,那么线性地址直接就是物理地址。Intel 80386的线性地址空间容量为4G(2的32次方即32根地址总线寻址)。
物理地址(Physical Address) 是指出目前CPU外部地址总线上的寻址物理内存的地址信号,是地址变换的最终结果地址。如果启用了分页机制,那么线性地址会使用页目录和页表中的项变换成物理地址。如果没有启用分页机制,那么线性地址就直接成为物理地址了,比如在实模式下。
2.2 虚拟地址,线性地址,物理地址关系
对于保护模式下地址之间的转换,对程序员来说是透明的。那么物理内存通过内存管理机制是如何将虚拟地址转换为物理地址的呢?当程序中的指令访问某一个逻辑地址时,CPU首先会根据段寄存器的内容将虚拟地址转化为线性地址。如果CPU发现包含该线性地址的内存页不在物理内存中就会产生缺页异常,该异常的处理程序通过是操作系统的内存管理器例程。内存管理器得到异常报告后会根据异常的状态信息。特别是CR2寄存器中包含的线性地址,将需要的内存页加载到物理内存中。然后异常处理程序返回使处理器重新执行导致页错误异常的指令,这时所需要的内存页已经在物理内存中,所以便不会再导致页错误异常。
2.3 段式机制及实例分析
前面说到在线性地址转换为物理地址之前,要先由逻辑地址转换为线性地址。系统采用段式管理机制来实现逻辑地址到线性地址的转换。保护模式下,通过”段选择符+段内偏移”寻址最终的线性地址。
CPU的段机制提供一种手段可以将系统的内存空间划分为一个个较小的受保护的区域,每个区域为一个段。相对32位系统,也就是把4G的逻辑地址空间换分成不同的段。每个段都有自己的起始地址(基地址),边界和访问权限等属性。实现段机制的一个重要数据结构就是段描述符。
下面是个程序实例中显示除了各个段的值:

图中给出了代码段CS,堆栈段SS,数据段DS等段寄存器的值;从得到的值可知,SS=DS=ES是相等的,至于为什么有些段的值相等,后面会说到。 以实例中给出的地址0x83e84110 为例,哪里是段描述符,哪里是段内偏移, 又是如何将该逻辑地址转换为线性地址的呢?相信很多人都迫不及待的想知道整个转换过程,接下来就要看看逻辑地址到线性地址详细转换过程。
上面说到段式管理模式下有段选择符+段内偏移寻址定位线性地址,其实际转换过程如下图所示

从图中可知,逻辑地址到线性地址的转换,先是通过段选择符从描述符表中找到段描述符,把段描述符和偏移地址相加得到线性地址。也就是说要想得到段描述符需要三个条件:
- 得到段选择符。
- 得到段描述符表
- 从段描述符表中找到段描述符的索引定位段描述符。
前面我们提到了段描述符 + 偏移地址,并没有提段选择符和段描述符表。所以我们要弄清楚这几个观念段选择符,段描述符表,段描述符,以及如何才能得到这几个描述符?
2.3.1 段描述符基础知识
从上图可知,通过段选择符要通过段描述符表找到段描述符,那么段描述符表是什么,又是怎么得到段描述符表呢?
在保护模式下,每个内存段就是一个段描述符。其结构如下图所示:

图中看出,一个段描述符是一个8字节长的数据结构,用来描述一个段的位置、大小、访问控制和状态等信息。段描述符最基本内容是段基址和边界。段基址以4字节表示(图中可看出3,4,5,8字节)。4字节刚好表示4G线性地址的任意地址(0x00000000-0xffffffff)。段边界20位表示(1,2字节及7字节的低四位)。
2.3.2 段描述符表实例解析
在现在多任务系统中,通常会同时存在多个任务,每个任务会有多个段,每个段需要一个段描述符,段描述符在上面一小节已经介绍,因此系统中会有很多段描述符。为了便于管理,需要将描述符保存于段描述符表中,也就是上图画出的段描述符表。IA-32处理器有3中描述符表:GDT,LDT和IDT。
GDT是全局描述符表。一个系统通常只有一个GDT表。GDT表也即是上图中的段描述符表,供系统中所以程序和任务使用。至于LDT和IDT今天不是重点。
那么如何找到GDT表的存放位置呢?系统中提供了GDTR寄存器用了表示GDT表的位置和边界,也就是系统是通过GDTR寄存器找到GDT表的;在32位模式下,其长度是48位,高32位是基地址,低16位是边界;在IA-32e模式下,长度是80位,高64位基地址,低16位边界。
位于GDT表中的第一个表项(0号)的描述符保留不用,成为空描述符。如何查看系统的GDT表位置呢?通过查看GDTR寄存器,如下图所示

从上图看出GDT表位置地址是0x8095000,gdtl值看出GDT边界1023,总长度1024字节。前面知道每一项段描述符占8字节。所以总共128个表项。图中第一表项是空描述符。
2.3.3 段选择符结构
前面我们介绍了段描述符表和段描述符的格式结构。那么如何通过段选择符找到段描述符呢,段选择符又是什么呢?
段选择符又叫段选择子,是用来在段描述符表中定位需要的段描述符。段选择子格式如下:

段选择子占有16位两个字节,其中高13位是段描述在段描述表中的索引。低3位是一些其他的属性,这里不多介绍。使用13位地址,意味着最多可以索引8k=8192个描述符。但是我们知道了上节GDT最多128个表项。
在保护模式下所有的段寄存器(CS,DS,ES,FS,GS)中存放的都是段选择子。
2.3.4 逻辑地址到线性地址转换实例解析
已经了解了逻辑地址到虚拟地址到线性地址的转换流程,那就看看在前面图中逻辑地址0x83e84110对应的线性地址是多少?
首先,地址0x83e84110对应的是代码段的一个逻辑地址,地址偏移已经知道,也就是段内偏移知道,通过寄存器EIP得到是0x83e34110。段选择符是CS寄存器CS=0008,其高13位对应的GDT表的索引是1,也就是第二项段描述符(第一项是空描述符)。GDT表的第二项为标红的8个字节

通过段描述的3,4,5,8个字节得到段基址。

如上图所示第二项段描述符的3,4,5,8字节对应的值为0x00000000。由此我们得到了段机制和段内偏移。最后的线性地址为段基址+段内偏移=0x0+0x83e34110=0x83e34110。
由此我们知道在32系统中逻辑地址就是线性地址。
其实通过观察其他的段选择子会发现,所有段选择子对应的基地址都是0x0,这是因为在32系统保护模式下,使用了平坦内存模型,所用的基地址和边界值都一样。既然基地址都是0,那么也就是线性地址就等于段内偏移=逻辑地址。
总之:
- 段描述符8字节
- GDTR是48位
- 段选择子2个字节。
2.4 页式机制及实例分析
前面介绍了由逻辑地址到线性地址的转换过程,那么接下来就要说说地址是如何将线性地址转为物理地址。需要先了解一些相关的数据结构。
前面说到如果CPU发现包含该线性地址的内存页不在物理内存中就会产生缺页异常,该异常的处理程序通过是操作系统的内存管理器例程。内存管理器得到异常报告后会根据异常的状态信息。特别是CR2寄存器中包含的线性地址,将需要的内存页加载到物理内存中。然后异常处理处理返回使处理器重新执行导致页错误异常的指令,这时所需要的内存页已经在物理内存中,所以便不会再导致也错误异常。
32位系统中通过页式管理机制实现线性地址到物理地址的转换,如下图:

2.4.1 PDE结构及如何查找内存页目录
从上图中我们知道通过寄存器CR3可以找到页目录表。那么CR3又是什么呢?在32系统中CR3存放的页目录的起始地址。CR3寄存器又称为页目录基址寄存器。32位系统中不同应用程序中4G线性地址对物理地址的映射不同,每个应用程序中CR3寄存器也不同。也就是说每个应用程序中页目录基址也是不同的。
从上图知道页目录表用来存放页目录表项(PDE),页目录占一个4kb内存页,每个PDE长度为4字节,所以页目录最多包含1KB。没启用PAE时,有两种PDE,这里我们只讨论使用常见的指向4KB页表的PDE。

页目录表项的高20位表示该PDE所指向的起始物理地址的高20位,该起始地址的低12位为0,也就是通过PDE高20位找到页表。由于页表低12位0,所以页表一定是4KB边界对齐。 也就是通过页目录表中的页目录表项来定位使用哪个页表(每一个应用程序有很多页表)。
以启动的calc程序为例,CR3寄存器是DirBase中的值,如下图

Calc.exe程序对应的CR3寄存器值为0x2960a000,下面是对应PDT结构
2.4.2页表结构解析
页表是用来存放页表表项(PTE)。每一个页表占4KB的内存页,每个PTE占4个字节。所以每个页表最多1024个PTE。其中高20位代表要使用的最终页面的起始物理地址的高20位。所以4KB的内存页也都是4KB边界对齐。

三 进程地址空间
· 32|64位的系统|CPU
操作系统运行在硬件CPU上,32位操作系统运行于32位CPU上,64位操作系统运行于64位CPU上;目前没有真正的64位CPU。
32位CPU一次只能操作32位二进制数;位数多CPU设计越复杂,软件设计越简单。
软件的进程运行于32位系统上,其寻址位也是32位,能表示的空间是232=4G,范围从0x0000 0000~0xFFFF FFFF。
· NULL指针分区
范围:0x0000 0000~0x0000 FFFF
作用:保护内存非法访问
例子:分配内存时,如果由于某种原因分配不成功,则返回空指针0x0000 0000;当用户继续使用比如改写数据时,系统将因为发生访问违规而退出。
那么,为什么需要那么大的区域呢,一个地址值不就行了吗?我在想,是不是因为不让8或16位的程序运行于32位的系统上呢?!因为NULL分区刚好范围是16的进程空间。
· 独享用户分区
范围:0x0001 0000~0x7FFE FFFF
作用:进程只能读取或访问这个范围的虚拟地址;超越这个范围的行为都会产生违规退出。
例子:
程序的二进制代码中所用的地址大部分将在这个范围,所有exe和dll文件都加载到这个。每个进程将近2G的空间是独享的。
注意:如果在boot.ini上设置了/3G,这个区域的范围从2G扩大为3G:0x0001 0000~0xBFFE FFFF。
· 共享内核分区
范围:0x8000 0000~0xFFFF FFFF
作用:这个空间是供操作系统内核代码、设备驱动程序、设备I/O高速缓存、非页面内存池的分配、进程目表和页表等。
例子:
这段地址各进程是可以共享的。
注意:如果在boot.ini上设置了/3G,这个区域的范围从2G缩小为1G:0xC000 0000~0xFFFF FFFF。
通过以上分析,可以知道,如果系统有n个进程,它所需的虚拟空间是:2G*n+2G (内核只需2G的共享空间)。
地址映射
· 区域
区域指的是上述地址空间中的一片连续地址。区域的大小必须是粒度(64k) 的整数倍,不是的话系统自动处理成整数倍。不同CPU粒度大小是不一样的,大部分都是64K。
区域的状态有:空闲、私有、映射、映像。
在你的应用程序中,申请空间的过程称作保留(预订),可以用VirtualAlloc;删除空间的过程为释放,可以用VirtualFree。
在程序里预订了地址空间以后,你还不可以存取数据,因为你还没有付钱,没有真实的RAM和它关联。
这时候的区域状态是私有;
默认情况下,区域状态是空闲;
当exe或DLL文件被映射进了进程空间后,区域状态变成映像;
当一般数据文件被映射进了进程空间后,区域状态变成映射。
· 物理存储器
Windows各系列支持的内存上限是不一样的,从2G到64G不等。理论上32位CPU,硬件上只能支持4G内存的寻址;能支持超过4G的内存只能靠其他技术来弥补。顺便提一下,Windows个人版只能支持最大2G内存,Intel使用Address Windows Extension (AWE) 技术使得寻址范围为236=64G。当然,也得操作系统配合。
内存分配的最小单位是4K或8K,一般来说,根据CPU不同而不同,后面你可以看到可以通过系统函数得到区域粒度和页面粒度。
· 页文件
页文件是存在硬盘上的系统文件,它的大小可以在系统属性里面设置,它相当于物理内存,所以称为虚拟内存。事实上,它的大小是影响系统快慢的关键所在,如果物理内存不多的情况下。
每页的大小和上述所说内存分配的最小单位是一样的,通常是4K或8K。
· 访问属性
物理页面的访问属性指的是对页面进行的具体操作:可读、可写、可执行。CPU一般不支持可执行,它认为可读就是可执行。但是,操作系统提供这个可执行的权限。
PAGE_NOACCESS
PAGE_READONLY
PAGE_READWRITE
PAGE_EXECUTE
PAGE_EXECUTE_READ
PAGE_EXECUTE_READWRITE
这6个属性很好理解,第一个是拒绝所有操作,最后一个是接受收有操作;
PAGE_WRITECOPY
PAGE_EXECUTE_WRITECOPY
这两个属性在运行同一个程序的多个实例时非常有用;它使得程序可以共享代码段和数据段。一般情况下,多个进程只读或执行页面,如果要写的话,将会Copy页面到新的页面。通过映射exe文件时设置这两个属性可以达到这个目的。
PAGE_NOCACHE
PAGE_WRITECOMBINE
这两个是开发设备驱动的时候需要的。
PAGE_GUARD
当往页面写入一个字节时,应用程序会收到堆栈溢出通知,在线程堆栈时有用。
· 映射过程
进程地址空间的地址是虚拟地址,也就是说,当取到指令时,需要把虚拟地址转化为物理地址才能够存取数据。这个工作通过页目和页表进行。
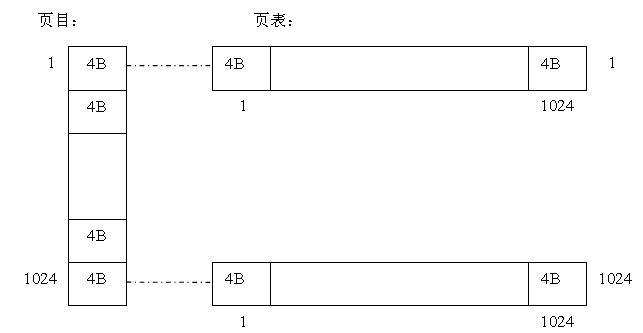
从图中可以看出,页目大小为4K,其中每一项(32位)保存一个页表的物理地址;每个页表大小为4K,其中每一项(32位)保存一个物理页的物理地址,一共有1024个页表。利用这4K+4K*1K=4.4M的空间可以表示进程的1024*1024* (一页4K) =4G的地址空间。
进程空间中的32位地址如下:

高10位用来找到1024个页目项中的一项,取出页表的物理地址后,利用中10位来得到页表项的值,根据这个值得到物理页的地址,由于一页有4K大小,利用低12位得到单元地址,这样就可以访问这个内存单元了。
每个进程都有自己的一个页目和页表,那么,刚开始进程是怎么找到页目所在的物理页呢?答案是CPU的CR3寄存器会保存当前进程的页目物理地址。
当进程被创建时,同时需要创建页目和页表,一共需要4.4M。在进程的空间中,0xC030 0000~0xC030 0FFF是用来保存页目的4k空间。0xC000 0000~0xC03F FFFF是用来保存页表的4M空间。也就是说程序里面访问这些地址你是可以读取页目和页表的具体值的(要工作在内核方式下)。有一点我不明白的是,页表的空间包含了页目的空间!
至于说,页目和页表是保存在物理内存还是页文件中,我觉得,页目比较常用,应该在物理内存的概率大点,页表需要时再从页文件导入物理内存中。
页目项和页表项是一个32位的值,当页目项第0位为1时,表明页表已经在物理内存中;当页表项第0位为1时,表明访问的数据已经在内存中。还有很多数据是否已经被改变,是否可读写等标志。另外,当页目项第7位为1时,表明这是一个4M的页面,这值已经是物理页地址,用虚拟地址的低22位作为偏移量。还有很多:数据是否已经被改变、是否可读写等标志。
四、浅谈一下Heap
(鉴于Matt Pietrek在它的《Windows 95系统程式设计大奥秘》对9x系统的heap做了非常详细的讲解,此处涉及的内容将仅限于Win2000)
Heap与Stack正好相反,你需要手动来管理每一块内存的申请和释放(在没有垃圾收集机制的情况下),而对于C/C++程序员来说,操作Heap的方式实在是太多了点。下面是几乎所有可以操作堆内存的方法的列表:
malloc/free
new/delete
GlobalAlloc/GlobalFree
LocalAlloc/LocalFree
HeapAlloc/HeapFree
其中malloc/free由运行时库提供,new/delete为C++内置的操作符。他们都使用运行时库的自己的堆。运行时库的在2000和win9x下都有自己独立的堆。这也就意味着只要你一启动进程,你将至少有两个堆,一个作为进程缺省,一个给C/C++运行时库。
GlobalAlloc/GlobalFree和LocalAlloc/LocalFree现在已失去原有的含义,统统从进程缺省堆中分配内存。
HeapAlloc/HeapFree则从指定的堆中分配内存。
单就分配内存而言(new/delete还要管构造和析构),所有这些方式最终要归结到一点2000和98下都是是HeapAlloc。所以微软才会强调GlobalAlloc/GlobalFree和LocalAlloc/LocalFree会比较慢,推荐使用HeapAlloc,但由于Global**和Local**具有较简单的使用界面,因此即使在微软所提供的源代码中他们仍被大量使用。必须指出的是HeapAlloc并不在kernel32.dll中拥有自己的实现,而是把所有调用转发到ntdll.RtlAllocateHeap。下面这张从msdn中截取的图(图2),应该有助于我们理解同堆相关的API。
堆内部的运作同SGI STL的分配器有些类似,大体上是这样,OS为每个堆维护几个链表,每个链表上存放指定大小范围的区块。当你分配内存时,操作系统根据你所提供的尺寸,先确定从那个链表中进行分配,接下来从那个链表中找到合适的块,并把其线性地址返还给你。如果你所要求的尺寸,在现存的区块中找不到,那么就新分配一块较大的内存(使用VirtualAlloc),再对他进行切割,而后向你返还某一区块的线性地址。这只是一个大致的情形,操作系统总在不停的更新自己的堆算法,以提高堆操作的速度。
堆本身的信息(包括标志位和链表头等)被存放在Heap Header中,而堆句柄正是指向Heap Header的指针,Heap Header的结构没有公开,稍后我们将试着做些分析。非常有趣的是微软一再强调只对toolhelp API有效的HeapID其实就是堆句柄。
原来是准备分析一下堆内部的一些结构的,可后来一想这么做实用价值并不是很大,所需力气却不小。因此也就没具体进行操作。但这里把实现监测堆中各种变化的小程序的实现思路公开一下,希望对大家有所帮助。这个小程序非常的简单,主要完成的任务就是枚举进程内所有的堆的变化情况。由于涉及到比较两个链表的不同,这里使用了STL的vector容器和某些算法来减少编码。同时为了使STL的内存使用不对我们要监测的对象产生干扰,我们需要建立自己的分配器,以使用我们单独创建的堆。此外还需要特别注意的一点是由于toolhelp APIHeap32Next在运行过程中不允许对任何堆进行扰动(否则他总返回TRUE),导致我们只能使用vector,并预先保留足够的空间。(访问堆内部某些信息的另一种方式是使用HeapWalkAPI,看个人喜好了)。
程序的运行过程是这样的,先对当前进程中存在的堆进行枚举,并把结果存入一个set类型的变量heapid1,接下来创建自己的堆给分配器使用,并对进程中存在的堆再次进行枚举并把结果存入另一个set类型的变量heapid2,这样就可以调用set_difference求出我们新建堆的ID,再以后列举队内部的信息时将排除这个ID所表示的堆。接下来就可以在两点之间分别把堆内部的信息存入相应的vector,比较这两个vector,就可以得到对应于分配内存操作,堆内部的变化情况了。


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









