









背景:以前每次配置hadoop和spark都要各种输入配置,太烦了。这次花了点时间,自己做了个shell来辅助自己的spark部署方式。cdh的hadoop没有部署,以后再部署,hadoop和spark准备分开来搞。
shell半自动化部署standalone的spark集群
一搞定3个虚拟机
我是使用的vm来做的三个虚拟机,系统为centos6.5,现在各种系统都支持吧,详细的可以看官网支持哪些系统。
虚拟机自己搞,我这里贴出机器名和host
vim /etc/sysconfig/network
hostname=master
vim /etc/sysconfig/network
hostname=slave1
vim /etc/sysconfig/network
hostname=slave2
vim /etc/hosts
192.168.247.132 master
192.168.247.133 slave1
192.168.247.134 slave2就是下面三台

二 安装免密码
1配置免密码服务(自动化)
首先各个机器需要产生公钥ssh-keygen -t rsa(必须做的),且每个机器的节点的密码最好一样,因为运行shell的时候需要手动输入密码,这里输入spark用户的密码
我是使用新建的用户spark安装的
然后在master节点运行自己写的shell,半自动化运行免密码
1是slave节点ip
2是slave节点同步过来的公钥(临时目录)
3是运行shell
shell保存的路径为/tmp/authorize
ps:使用spark用户的话,公钥生成在/home/spark/.ssh目录哈
三 安装jdk,scala,spark
这里主要是使用自己 写的shell把jdk,scala,spark解压,改名,配置/etc/profile
三台节点都要把/home目录的权限改了,因为我要装在/home/目录(个人习惯),我目录写死了的,可以把shell修改一下
chmod 777 /home
运行这个/tmp/config_shell/run_config.sh就可以了,不过中间会让你输入密码哈,因为需要修改/etc/profile的内容
下面是目录的一下描述,要使用的话,把shell的里面的目录修改就好了
安装shell的保存路劲:/tmp/config_shell
/etc/profile文件的配置:/tmp/config_shell/config_etc_profile.sh
jdk的解压与改名:/tmp/config_shell/config_jdk.sh
scala的解压与改名:/tmp/config_shell/config_scala.sh
spark的解压与改名:/tmp/config_shell/config_spark.sh
总的运行shell:/tmp/config_shell/run_config.sh
配置spark的配置文件(spark-env.sh,slaves):/tmp/config_shell/config_spark_evn.sh
把主节点的所有安装配置发送到从节点:/tmp/config_shell/distribute_slaves.sh
软件保存路劲:/home/dowload/
/home/dowload/jdk-7u79-linux-x64.tar.gz
/home/dowload/scala-2.11.8.tgz
/home/dowload/spark-2.0.0-bin-hadoop2.6.tgz

软件安装路劲:/home/
/home/jdk1.7
/home/scala2.11
/home/spark2.0
四:配置spark的配置文件
通过shell修改spark的一些配置文件:
#主要修改的:
1spark-env.sh
2slaves
#修改spark的配置文件
/tmp/config_shell/config_spark_evn.sh
#把jdk,scala,spark,/etc/profile,传输到各个节点中
/tmp/config_shell/distribute_slaves.sh
每个文件使用scp时的用户,会提升输入密码,这里输入root密码
jdk:spark用户
scala:spark用户
spark:spark用户
/etc/profile:root用户
五验证
对了,必要要在每个机器上使用source /etc/profile 或者重启每台机器。因为在shell中,使用source /etc/profile没有效果。
1启动集群
在master机器上运行
$SPARK_HOME/sbin/start-all.sh

2查看启动日志并jps查看
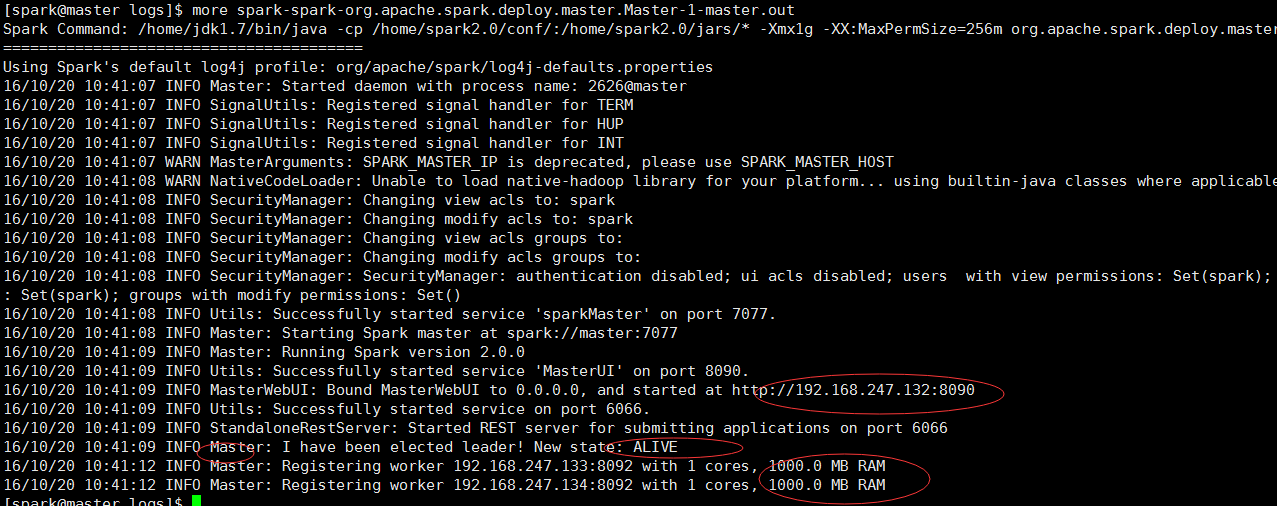
more /home/spark2.0/logs/spark-spark-org.apache.spark.deploy.master.Master-1-master.out
下图表示启动成功,当然也要在每台机器上jps,看看master和work进程是否运行
3web查看
http://192.168.247.132:8090/
默认是8080接口哈,但是我修改为8090接口
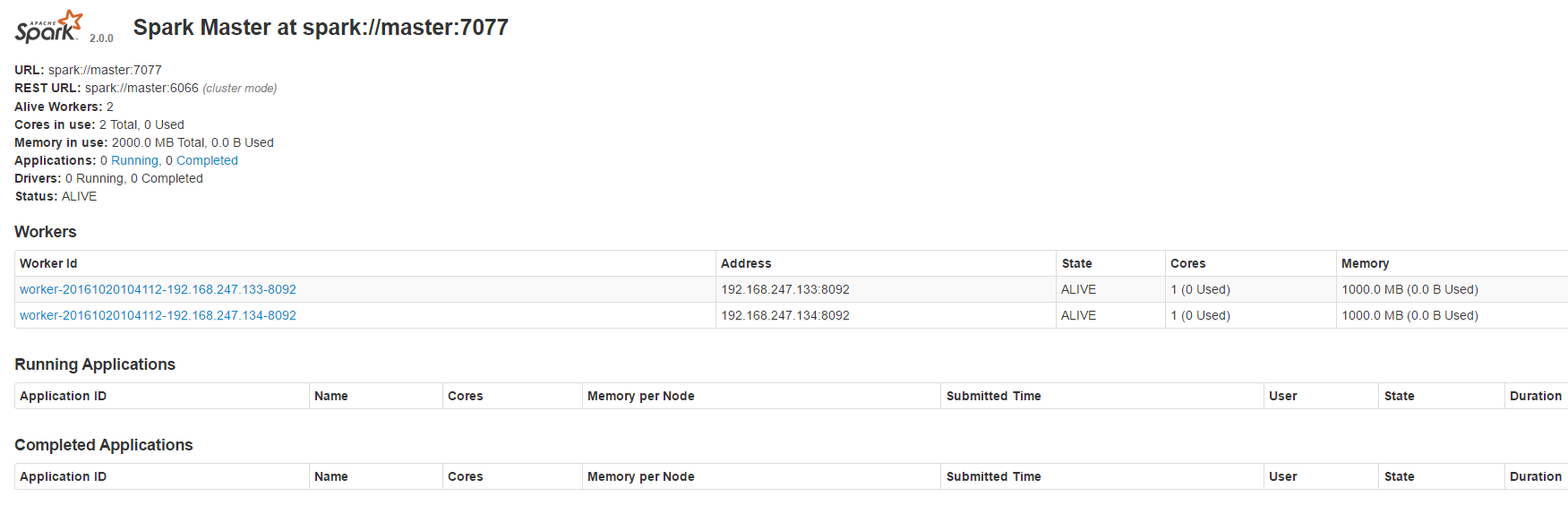
从上面可以看出,有两台slave节点哈,到这里基于standalone的spark分布式集群安装成功。
想把shell传上来的,但是没找到连接,csdn是不是不能传,能的话,留言教我下哈。
对shell有兴趣的可以联系我邮箱444687196@qq.com,或者留下邮箱,我发给大家。















 1398
1398











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











