










在推荐中,关联规则推荐使用的比较频繁,毕竟是通过概率来预测的,易于理解且准确度比较高,不过有一个缺点为,想要覆盖推荐物品的数量,就要降低支持度与置信度。过高的支持度与置信度会导致物品覆盖不过,这里需要其他的推荐方法合作,建议使用基于Spark的模型推荐算法(矩阵分解+ALS).
一FPGrowth算法描述:
FPGrowth算法
概念:支持度,置信度,提升度(Spark好像没有计算这个的函数,需要自己计算)
列子:假如10000个消费者购买了商品,尿布1000个,啤酒2000个,面包500个,同时购买了尿布和啤酒800个,同时购买了尿布和面包100个。
1)支持度:在所有项集中出现的可能性,项集同时含有,x与y的概率。是第一道门槛,衡量量是多少,可以理解为‘出镜率’,一般会支持初始值过滤掉低的规则。
尿布和啤酒的支持度为:800/10000=8%
2)置信度:在X发生的条件下,Y发生的概率。这是第二道门槛,衡量的是质量,设置最小的置信度筛选可靠的规则。
尿布-》啤酒的置信度为:800/1000=80%,啤酒-》尿布的置信度为:800/2000=40%
3)提升度:在含有x条件下同时含有Y的可能性(x->y的置信度)比没有x这个条件下含有Y的可能性之比:confidence(尿布=> 啤酒)/概率(啤酒)) = 80%/((2000+800)/10000) 。如果提升度=1,那就是没啥关系这两个。
通过支持度和置信度可以得出强关联关系,通过提升的,可判别有效的强关联关系。
2 FPGrowth特点
1)产生候选集,2)只需要两次遍历数据库,提高效率。
再举个我们这里的列子,列如时间的原因是,使用最近的行为训练规则,太久的行为没有意义
样本如下:
列子:用户,时间,消费的漫画
u1,20160925,成都1995,seven,神兽退散。
u2,20160925,成都1995,seven,six。
u1,20160922,成都1995,恶魔日记
比如产生了如下规则:
规则:成都1995,seven->神兽退散
这条规则:
成都1995,seven的支持度2/3
成都1995,seven-》神兽退散,的置信度1/2
这里打个广告哈,成都1995,seven,神兽退散(漫画)比较真的比较好看,成都1995也要拍网剧了哈!!
关联规则主要的难道在于频繁项集的筛选,apriori算法就是一个一个组合的,如果item数量很多,那么太慢了,FPGrowth算法速度比较快。
我本身对FPGowth的树形结构产生频繁项集不是特别了解,以后可以研究下哈,核心点就是通过头树和树减少遍历次数吧
3
算法
输入:参数,样本
输出:规则
FPGrowth参考资料
参考资料
http://www.cnblogs.com/zhangchaoyang/articles/2198946.html
二Spark代码实现(修改了一下Spark的列子)
//数据样本:
r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t ppackage org.wq.scala.ml
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/24.
*/
object FP_GrowthTest {
def main(args:Array[String]){
val conf = new SparkConf().setAppName("FPGrowthTest").setMaster("local").set("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse")
val sc = new SparkContext(conf)
//设置参数
//最小支持度
val minSupport=0.2
//最小置信度
val minConfidence=0.8
//数据分区
val numPartitions=2
//取出数据
val data = sc.textFile("data/mllib/sample_fpgrowth.txt")
//把数据通过空格分割
val transactions=data.map(x=>x.split(" "))
transactions.cache()
//创建一个FPGrowth的算法实列
val fpg = new FPGrowth()
//设置训练时候的最小支持度和数据分区
fpg.setMinSupport(minSupport)
fpg.setNumPartitions(numPartitions)
//把数据带入算法中
val model = fpg.run(transactions)
//查看所有的频繁项集,并且列出它出现的次数
model.freqItemsets.collect().foreach(itemset=>{
println( itemset.items.mkString("[", ",", "]")+","+itemset.freq)
})
//通过置信度筛选出推荐规则则
//antecedent表示前项
//consequent表示后项
//confidence表示规则的置信度
//这里可以把规则写入到Mysql数据库中,以后使用来做推荐
//如果规则过多就把规则写入redis,这里就可以直接从内存中读取了,我选择的方式是写入Mysql,然后再把推荐清单写入redis
model.generateAssociationRules(minConfidence).collect().foreach(rule=>{
println(rule.antecedent.mkString(",")+"-->"+
rule.consequent.mkString(",")+"-->"+ rule.confidence)
})
//查看规则生成的数量
println(model.generateAssociationRules(minConfidence).collect().length)
//并且所有的规则产生的推荐,后项只有1个,相同的前项产生不同的推荐结果是不同的行
//不同的规则可能会产生同一个推荐结果,所以样本数据过规则的时候需要去重
}
}
上面规则是本地运行的,部署的话需要改下哈,代码如下
package org.wq.scala.ml
import org.apache.spark.mllib.fpm.FPGrowth
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/24.
*/
object FP_Growth {
def main(args:Array[String]){
if(args.length!=4){
println("请输入4个参数 购物篮数据路径 最小支持度 最小置信度 数据分区")
System.exit(0)
}
val conf = new SparkConf().setAppName("FPGrowthTest")
val sc = new SparkContext(conf)
val data_path=args(0)
//设置参数
//最小支持度
val minSupport=args(1).toDouble
//最小置信度
val minConfidence=args(2).toDouble
//数据分区
val numPartitions=args(3).toInt
//取出数据
val data = sc.textFile(data_path)
//把数据通过空格分割
val transactions=data.map(x=>x.split(" "))
transactions.cache()
//创建一个FPGrowth的算法实列
val fpg = new FPGrowth()
//设置训练时候的最小支持度和数据分区
fpg.setMinSupport(minSupport)
fpg.setNumPartitions(numPartitions)
//把数据带入算法中
val model = fpg.run(transactions)
//查看所有的频繁项集,并且列出它出现的次数
model.freqItemsets.collect().foreach(itemset=>{
println( itemset.items.mkString("[", ",", "]")+","+itemset.freq)
})
//通过置信度筛选出推荐规则则
//antecedent表示前项
//consequent表示后项
//confidence表示规则的置信度
//这里可以把规则写入到Mysql数据库中,以后使用来做推荐
//如果规则过多就把规则写入redis,这里就可以直接从内存中读取了,我选择的方式是写入Mysql,然后再把推荐清单写入redis
model.generateAssociationRules(minConfidence).collect().foreach(rule=>{
println(rule.antecedent.mkString(",")+"-->"+
rule.consequent.mkString(",")+"-->"+ rule.confidence)
})
//查看规则生成的数量
println(model.generateAssociationRules(minConfidence).collect().length)
//并且所有的规则产生的推荐,后项只有1个,相同的前项产生不同的推荐结果是不同的行
//不同的规则可能会产生同一个推荐结果,所以样本数据过规则的时候需要去重
}
}
三提交部署
上传jar与数据到主节点

#然后把数据文件scp到各个节点
cd /home/jar/data
scp sample_fpgrowth.txt spark@slave1:/home/jar/data/
scp sample_fpgrowth.txt spark@slave2:/home/jar/data/
然后提交给spark集群运行
数据目录:/home/jar/data
jar目录:/home/jar
模型目录:/home/jar/model
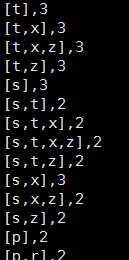
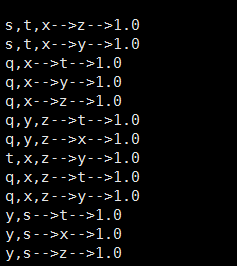
spark-submit --class org.wq.scala.ml.FP_Growth --master spark://master:7077 --executor-memory 700m --num-executors 1 /home/jar/FP_Growth.jar /home/jar/data/sample_fpgrowth.txt 0.2 0.8 2运行结果:
频繁项集:
规则:
集群跑job信息

四:注意事项
1我使用了20w多样本计算,近2000个物品,支持度5%,置信70%,训练出来的规则很多,最后匹配的规则比较慢,而且物品的覆盖比较少。所以把近2000的物品修改为主推的近500,这样规则就减少了很多,切覆盖的物品也比较多。具体参数自己试下哈,样本和样本的结构不一样。
2FpGrowth的训练其实比较快的,把样本量提升到了50w,训练的时间也是分钟级别的,10分钟左右吧,前提是支持度比高。在调整算法的时间,支持度很重要,关系到运行的时间,我把支持度调整的很低的时候,算法跑不出来,也会内存溢出(本身内存也不大哈)。不过时间多也无所谓,因为本身就是离线模型训练哈。
3参数调整方案,多试试,觉得准确性和物品覆盖比较满意的时候就行了额,至于参数的自动迭代,完全没什么思路,除了输入不同参数,求最好。
4训练的时候数据能cache就cache哈,会比叫快哈
5 这个训练中,6个样本,都产生了85个规则,可以想象,样本量大了之后,规则暴多,所以把规则写入mysql,group by,group_concat()(会mysql的应该明白我说啥)可以合并规则,把置信度高的放在前面,当然自己写代码可以哈。
s,t,x–>z–>1
s,t,x–>y–>1
合并为s,t,x–>z,y置信度高的在前面哈
















 673
673

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











