









主要介绍了一下几点:
1矩阵分解的几种算法
2spark使用矩阵分解的几种方式,1ml 包中使用,2mllib包中的使用,其实有不调用包自己写的案列(可以去看看哈,就在example目录)
3使用ALS做推荐的一个比较详细的流程:1自迭代确定比较优的参数是,2使用参数训练模型,3使用模型推荐topn的物品给用户
4讲了怎么自迭代ALS算法参数,感觉这个还重要点
5提交spark的报了一个错误,已经错误解决方式
6好多细节都没写,感觉要写的有好多,也不是很完善,时间不够,只是提供了核心代码和思路
一:Spark2.0新概率解释(仅限本文使用)
1 SparkSession
SparkSession是spark2.0的全新切入点,以前都是sparkcontext创建RDD的,StreamingContext,sqlContext,HiveContext。
DataDrame提供的API慢慢的成为新的标准API,我们需要1个新的切入点来构建他,这个就是SparkSession哈,以前我也没见过.官网API介绍

官网上说,这是用来构建Dataset和DataFrame的API的切入点。在环境中,SparkSession已经预先创建了,我们需要使用bulder方法得到已经存在在SparkSession。使用方法如下:
SparkSession.builder().getOrCreate()
SparkSession.builder()
.master("local")
.appName("Word Count")
.config(key, value").
.getOrCreate()二:ALS算法
1含义
在现实中用户-物品-评分矩阵是及其大的,用户消费有限,对单个用户来说,消费的物品的非常有限的,产生的评分也是比较少的,这样就造成了用户-物品矩阵有大量的空值。
假定用户的兴趣只受少数因素的影响,所以用户-物品矩阵可以分解为用户的特征向量矩阵和物品的特征向量矩阵(降维了)。用户的特征向量距离表示用户的兴趣(U),物品的特征向量矩阵代表用户的特点(V),合起来(内积)表示用户对物品的特点的兴趣,也就是喜好程度。
M=U*V
2协同过滤矩阵分解算法
2.1奇异值分解(SVD)
矩阵的奇异值分解是最简单的一种矩阵分解算法,主要是在U*V中间加了个一个奇异值矩阵,公式如下:
M=U*(奇异值矩阵)*(V的共轭)
奇异值矩阵是对角矩阵,奇异值分解的缺点(没试过不知道,书上说的),1不允许分解矩阵有null值,需要进行填分,2如果填分,又有两个问题:1增加数据量,增加算法复杂度,2简单粗暴的填分方式会导致数据失真,如果将null值设置为0,那么会导致过度学习问题。
奇异值分解方式,感觉用的不多,我自己接触的话。
2.2正则化矩阵分解
加入正则化是为了解决稀疏矩阵可能过学习问题,评价矩阵分解是RMSE,通过最小化RMSE来学习用户特征矩阵U和物品特征矩阵V,在RMSE函数中加入了正则化项减少过拟合,公式如下,公式都是书上写的哈,这里截图:
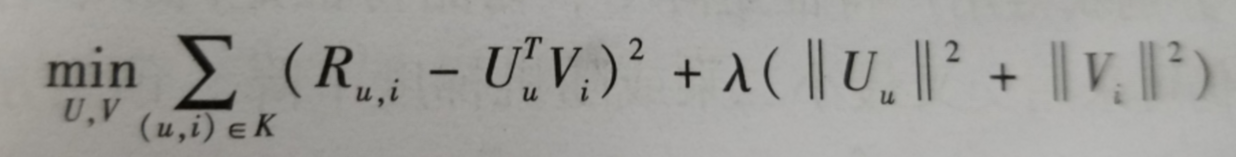
K表示评分记录(u用户对I物品的评分),Ru,i表示用户u对物品i的真实评分,诶梦达表示正则化系数,诶梦达后面的表示防止过拟合的正则化项。
加入正则化的含义可以理解为,修改rmse,不要其太大或者太小。
假设用户特征矩阵为Umt,物品评分矩阵为Vtn,其中t特征<
2.3带偏置的矩阵分解(说的很有道理,但是比较难评估)
理论就不说了,举个例子,u1对v1的评分为4表示u1对v1这个物品非常喜欢,u2对v1的评分为4表示u1对v1一般喜欢,对用用户来说,即使他们对同一物品的评分相同,但是表示他们的喜好程度并不是一样的。同理对于物品来说也是一样。把这种独立于用户和独立于物品的影响因素成为偏置,偏置一共有3个部分组成。
1训练集中所有评分记录的全局平均,表示训练集中总体评分情况,一般是一个常数。
2用户偏置bu,独立于物品特征因素,表示用户特定的打分习惯。
3物品偏置bi,表示独立于用户特征因素,举个列子,好片子一般总体评分偏高,烂片一般评分偏低,偏置就是表示这种特征。
以上的所有偏置对用户对物品喜好无关,得到的预测评分公式如下:
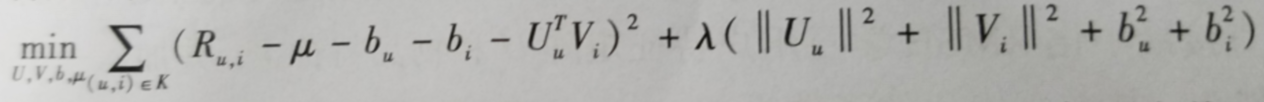
按照这种思路,其实还要很多其他优化,比如加入时间因素,社会流行因素等。
Spark使用的是带正则化矩阵分解,优化函数的方式选用的是交叉最小二乘法ALS
三Spark代码
spark代码一半是官方列子修改过来的哈
1调用ml包
使用org.apache.spark.ml.recommendation.ALS来计算,并且使用了spark2.0的新特性SparkSession来实现推荐,具体代码与注释如下:
package org.wq.scala.ml
import org.apache.spark.ml.evaluation.RegressionEvaluator
import org.apache.spark.ml.recommendation.ALS
import org.apache.spark.sql.SparkSession
/**
* Created by Administrator on 2016/10/24.
*/
//这是spark新的Als算法的列子
object ALSRecommendNewTest {
//定义个类,来保存一次评分哈
case class Rating(userId: Int, movieId: Int, rating: Float, timestamp: Long)
//把一行转换成一个评分类
def parseRating(str: String): Rating = {
val fields = str.split("::")
assert(fields.size == 4)
Rating(fields(0).toInt, fields(1).toInt, fields(2).toFloat, fields(3).toLong)
}
def main(args:Array[String])={
//SparkSession是spark2.0的全新切入点,以前都是sparkcontext创建RDD的,StreamingContext,sqlContext,HiveContext。
//DataDrame提供的API慢慢的成为新的标准API,我们需要1个新的切入点来构建他,这个就是SparkSession哈
//以前我也没见过
val spark = SparkSession.builder().config("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse").master("local").appName("ALSExample").getOrCreate()
import spark.implicits._
//read方法返回的是一个DataFrameReader类,可以转换为DataFrame
//DataFrameReader类的textFile方法:加载文本数据,返回为Dataset
//使用一个函数parseRating处理一行数据
val ratings = spark.read.textFile("data/mllib/sample_movielens_ratings.txt").map(parseRating).toDF()
val Array(training,test)=ratings.randomSplit(Array(0.8, 0.2))
// Build the recommendation model using ALS on the training data
//使用训练数据训练模型
//这里的ALS是import org.apache.spark.ml.recommendation.ALS,不是mllib中的哈
//setMaxiter设置最大迭代次数
//setRegParam设置正则化参数,日lambda这个不是更明显么
//setUserCol设置用户id列名
//setItemCol设置物品列名
//setRatingCol设置打分列名
val als = new ALS()
als.setRank(10)
.setMaxIter(5)
.setRegParam(0.01)
.setUserCol("userId")
.setItemCol("movieId")
.setRatingCol("rating")
//fit给输出的数据,训练模型,fit返回的是ALSModel类
val model = als.fit(training)
//使用测试数据计算模型的误差平方和
//transform方法把数据dataset换成dataframe类型,预测数据
val predictions = model.transform(test)
//RegressionEvaluator这个类是用户评估预测效果的,预测值与原始值
//这个setLabelCol要和als设置的setRatingCol一致,不然会报错哈
//RegressionEvaluator的setPredictionCol必须是prediction因为,ALSModel的默认predictionCol也是prediction
//如果要修改的话必须把ALSModel和RegressionEvaluator一起修改
//model.setPredictionCol("prediction")和evaluator.setPredictionCol("prediction")
//setMetricName这个方法,评估方法的名字,一共有哪些呢?
//rmse-平均误差平方和开根号
//mse-平均误差平方和
//mae-平均距离(绝对)
//r2-没用过不知道
//这里建议就是用rmse就好了,其他的基本都没用,当然还是要看应用场景,这里是预测分值就是用rmse。如果是预测距离什么的mae就不从,看场景哈
val evaluator = new RegressionEvaluator()
.setMetricName("rmse")
.setLabelCol("rating")
.setPredictionCol("prediction")
val rmse = evaluator.evaluate(predictions)
println("Root-mean-square error = "+rmse)
//stop是停止底层的SparkContext
spark.stop()
}
}2调用mllib,实现
使用mllib中的ALS算法如下,如果是生产,建议使用mllib中的
package org.wq.scala.ml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.examples.mllib.AbstractParams
import scala.collection.mutable
//处理输入参数的库
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
import scopt.OptionParser
/**
* Created by Administrator on 2016/10/24.
*/
object ALSRecommendMllibTest {
//参数含义
//input表示数据路径
//kryo表示是否使用kryo序列化
//numIterations迭代次数
//lambda正则化参数
//numUserBlocks用户的分块数
//numProductBlocks物品的分块数
//implicitPrefs这个参数没用过,但是通过后面的可以推断出来了,是否开启隐藏的分值参数阈值,预测在那个级别才建议推荐,这里是5分制度的,详细看后面代码
case class Params(
input: String = null,
output:String=null,
kryo: Boolean = false,
numIterations: Int = 20,
lambda: Double = 1.0,
rank: Int = 10,
numUserBlocks: Int = -1,
numProductBlocks: Int = -1,
implicitPrefs: Boolean = false) extends AbstractParams[Params]
def main(args: Array[String]) {
val defaultParams = Params()
//规定参数的输入方式 --rank 10 这种
//我个人习惯为直接用空格分割(如果参数不对,给予提示),当然下面这种更规范化和人性化,还有默认参数的
//以后再研究OptionParser用法,不过他这种参数用法挺好用的哈
val parser = new OptionParser[Params]("Mllib 的ALS") {
head("MovieLensALS: an example app for ALS on MovieLens data.")
opt[Int]("rank")
.text(s"rank, default: ${defaultParams.rank}")
.action((x, c) => c.copy(rank = x))
opt[Int]("numIterations")
.text(s"number of iterations, default: ${defaultParams.numIterations}")
.action((x, c) => c.copy(numIterations = x))
opt[Double]("lambda")
.text(s"lambda (smoothing constant), default: ${defaultParams.lambda}")
.action((x, c) => c.copy(lambda = x))
opt[Unit]("kryo")
.text("use Kryo serialization")
.action((_, c) => c.copy(kryo = true))
opt[Int]("numUserBlocks")
.text(s"number of user blocks, default: ${defaultParams.numUserBlocks} (auto)")
.action((x, c) => c.copy(numUserBlocks = x))
opt[Int]("numProductBlocks")
.text(s"number of product blocks, default: ${defaultParams.numProductBlocks} (auto)")
.action((x, c) => c.copy(numProductBlocks = x))
opt[Unit]("implicitPrefs")
.text("use implicit preference")
.action((_, c) => c.copy(implicitPrefs = true))
arg[String]("<input>")
.required()
.text("input paths to a MovieLens dataset of ratings")
.action((x, c) => c.copy(input = x))
arg[String]("<output>")
.required()
.text("output Model Path")
.action((x, c) => c.copy(output = x))
note(
"""
|For example, the following command runs this app on a synthetic dataset:
|
| bin/spark-submit --class org.apache.spark.examples.mllib.MovieLensALS \
| examples/target/scala-*/spark-examples-*.jar \
| --rank 5 --numIterations 20 --lambda 1.0 --kryo \
| data/mllib/sample_movielens_data.txt
""".stripMargin)
}
//虽然是map但是只运行1次哈,主要看run方法做了什么
parser.parse(args, defaultParams).map { params =>
run(params)
} getOrElse {
System.exit(1)
}
}
def run(params: Params) {
val conf = new SparkConf().setAppName(s"MovieLensALS with $params").setMaster("local").set("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse")
//如果参数设置了kryo序列化没那么需要注册序列化的类和配置序列化的缓存,模板照着写就是了
//使用序列化是为传输的时候速度更快,我没有使用这个,因为反序列话也需要一定的时间,我是局域网搭建spark集群的(机子之间很快)。
// 如果是在云搭建集群可以考虑使用
if (params.kryo) {
conf.registerKryoClasses(Array(classOf[mutable.BitSet], classOf[Rating]))
.set("spark.kryoserializer.buffer", "8m")
}
val sc = new SparkContext(conf)
//设置log基本,生产也建议使用WARN
Logger.getRootLogger.setLevel(Level.WARN)
//得到因此的级别
val implicitPrefs = params.implicitPrefs
//读取数据,并通过是否设置了分值阈值来修正评分
//官方推荐是,只有哦大于3级别的时候才值得推荐
//且下面的代码,implicitPrefs,直接就是默认5 Must see,按道理会根据自己对分数阈值的预估,rating减去相应的值,比如fields(2).toDouble - 2.5
//5 -> 2.5, 4 -> 1.5, 3 -> 0.5, 2 -> -0.5, 1 -> -1.5
//现在是5分值的映射关系,如果是其他分值的映射关系有该怎么做?还不确定,个人建议别使用这个了。
//经过下面代码推断出,如果implicitPrefs=true或者flase,true的意思是,预测的分数要大于2.5(自己设置),才能推荐给用户,小了,没有意义
//它引入implicitPrefs的整体含义为,只有用户对物品的满意达到一定的值,才推荐,不然推荐不喜欢的没有意思,所以在构建样本的时候,会减去相应的值fields(2).toDouble - 2.5(自己设置)
//这种理论是可以的,但是还有一个理论,不给用户推荐比给用户推荐错了还要严重(有人提出过),不推荐产生的效果还要严重,还有反向推荐,
//我把implicitPrefs叫做分值阈值
val ratings = sc.textFile(params.input).map { line =>
val fields = line.split("::")
if (implicitPrefs) {
/*
* MovieLens ratings are on a scale of 1-5:
* 5: Must see
* 4: Will enjoy
* 3: It's okay
* 2: Fairly bad
* 1: Awful
* So we should not recommend a movie if the predicted rating is less than 3.
* To map ratings to confidence scores, we use
* 5 -> 2.5, 4 -> 1.5, 3 -> 0.5, 2 -> -0.5, 1 -> -1.5. This mappings means unobserved
* entries are generally between It's okay and Fairly bad.
* The semantics of 0 in this expanded world of non-positive weights
* are "the same as never having interacted at all".
*/
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble - 2.5)
} else {
Rating(fields(0).toInt, fields(1).toInt, fields(2).toDouble)
}
}.cache()
//计算一共有多少样本数
val numRatings = ratings.count()
//计算一共有多少用户
val numUsers = ratings.map(_.user).distinct().count()
//计算应该有多少物品
val numMovies = ratings.map(_.product).distinct().count()
println(s"Got $numRatings ratings from $numUsers users on $numMovies movies.")
//按80%训练,20%验证分割样本
val splits = ratings.randomSplit(Array(0.8, 0.2))
//把训练样本缓存起来,加快运算速度
val training = splits(0).cache()
//构建测试样,我先翻译下他说的英文哈。
//分值为0表示,我对物品的评分不知道,一个积极有意义的评分表示:有信心预测值为1
//一个消极的评分表示:有信心预测值为0
//在这个案列中,我们使用的加权的RMSE,这个权重为自信的绝对值(命中就为1,否则为0)
//关于误差,在预测和1,0之间是不一样的,取决于r 是正,还是负
//这里splits已经减了分值阈值了,所以>0 =1 else 0的含义是,1表示分值是大于分值阈值的,这里是大于2.5,0表示小于2.5
val test = if (params.implicitPrefs) {
/*
* 0 means "don't know" and positive values mean "confident that the prediction should be 1".
* Negative values means "confident that the prediction should be 0".
* We have in this case used some kind of weighted RMSE. The weight is the absolute value of
* the confidence. The error is the difference between prediction and either 1 or 0,
* depending on whether r is positive or negative.
*/
splits(1).map(x => Rating(x.user, x.product, if (x.rating > 0) 1.0 else 0.0))
} else {
splits(1)
}.cache()
//训练样本量和测试样本量
val numTraining = training.count()
val numTest = test.count()
println(s"Training: $numTraining, test: $numTest.")
//这里应为不适用ratings了,释放掉它占的内存
ratings.unpersist(blocking = false)
//setRank设置随机因子,就是隐藏的属性
//setIterations设置最大迭代次数
//setLambda设置正则化参数
//setImplicitPrefs 是否开启分值阈值
//setUserBlocks设置用户的块数量,并行化计算,当特别大的时候需要设置
//setProductBlocks设置物品的块数量
val model = new ALS()
.setRank(params.rank)
.setIterations(params.numIterations)
.setLambda(params.lambda)
.setImplicitPrefs(params.implicitPrefs)
.setUserBlocks(params.numUserBlocks)
.setProductBlocks(params.numProductBlocks)
.run(training)
//训练的样本和测试的样本的分值全部是减了2.5分的
//测试样本的分值如果大于0为1,else 0,表示分值大于2.5才预测为Ok
//计算rmse
val rmse = computeRmse(model, test, params.implicitPrefs)
println(s"Test RMSE = $rmse.")
//保存模型,模型保存路劲为
model.save(sc,params.output)
println("模型保存成功,保存路劲为:"+params.output)
sc.stop()
}
/** Compute RMSE (Root Mean Squared Error). */
def computeRmse(model: MatrixFactorizationModel, data: RDD[Rating], implicitPrefs: Boolean)
: Double = {
//内部方法含义如下
// 如果已经开启了implicitPref那么,预测的分值大于0的为1,小于0的为0,没有开启的话,就是用原始分值
//min(r,1.0)求预测分值和1.0那个小,求小值,然后max(x,0.0)求大值, 意思就是把预测分值大于0的为1,小于0 的为0
//这样构建之后预测的预测值和测试样本的样本分值才一直,才能进行加权rmse计算
def mapPredictedRating(r: Double): Double = {
if (implicitPrefs) math.max(math.min(r, 1.0), 0.0) else r
}
//根据模型预测,用户对物品的分值,predict的参数为RDD[(Int, Int)]
val predictions: RDD[Rating] = model.predict(data.map(x => (x.user, x.product)))
//mapPredictedRating把预测的分值映射为1或者0
//join连接原始的分数,连接的key为x.user, x.product
//values方法表示只保留预测值,真实值
val predictionsAndRatings = predictions.map{ x =>
((x.user, x.product), mapPredictedRating(x.rating))
}.join(data.map(x => ((x.user, x.product), x.rating))).values
//最后计算预测与真实值的平均误差平方和
//这是先每个的平方求出来,然后再求平均值,最后开方
math.sqrt(predictionsAndRatings.map(x => (x._1 - x._2) * (x._1 - x._2)).mean())
}
}
3找到最优(可能最优哈)参数
package org.wq.scala.ml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.recommendation.{ALS, MatrixFactorizationModel, Rating}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/24.
*/
object ALSRecommendMllibBestParamTest {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("ALS_mllib_best_param").setMaster("local").set("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse")
val sc = new SparkContext(conf)
//设置log基本,生产也建议使用WARN
Logger.getRootLogger.setLevel(Level.WARN)
//第一步构建time,Rating
val movie = sc.textFile("data/mllib/sample_movielens_ratings.txt")
val ratings = movie.map(line=>{
val fields = line.split("::")
val rating = Rating(fields(0).toInt,fields(1).toInt,fields(2).toDouble)
val timestamp =fields(3).toLong%5
(timestamp,rating)
})
//输出数据的基本信息
val numRatings = ratings.count()
val numUser = ratings.map(_._2.user).distinct().count()
val numItems = ratings.map(_._2.product).distinct().count()
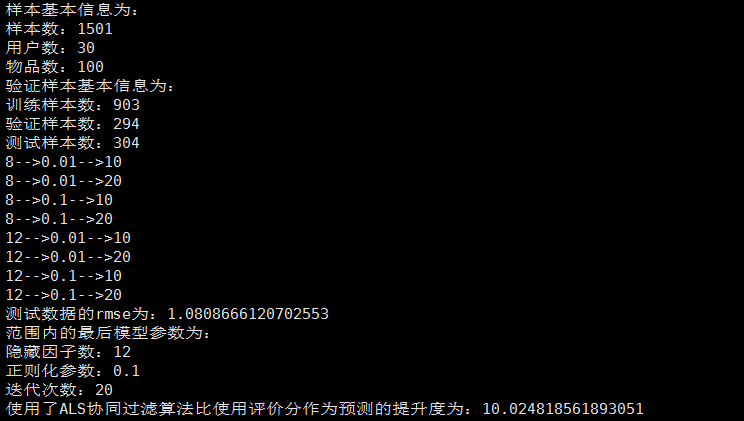
println("样本基本信息为:")
println("样本数:"+numRatings)
println("用户数:"+numUser)
println("物品数:"+numItems)
val sp = ratings.randomSplit(Array(0.6,0.2,0.2))
//第二步骤
//使用日期把数据分为训练集(timestamp<6),验证集(6<timestamp<8)和测试集(timestamp>8)
/* val training = ratings.filter(x=>x._1<6).values.repartition(2).cache()
val validation = ratings.filter(x=>x._1>6 && x._1<8).values.repartition(2).cache()
val test=ratings.filter(x=>x._1>=8).values.cache()*/
//样本时间参数都一样,测试就使用随机算了
val training=sp(0).map(x=>Rating(x._2.user,x._2.product,x._2.rating)).repartition(2).cache()
val validation=sp(1).map(x=>Rating(x._2.user,x._2.product,x._2.rating)).repartition(2).cache()
val test=sp(1).map(x=>Rating(x._2.user,x._2.product,x._2.rating))
val numTraining = training.count()
val numValidation=validation.count()
val numTest=test.count()
println("验证样本基本信息为:")
println("训练样本数:"+numTraining)
println("验证样本数:"+numValidation)
println("测试样本数:"+numTest)
//第三步
//定义RMSE方法
def computeRmse(model:MatrixFactorizationModel,data:RDD[Rating]):Double={
val predictions:RDD[Rating]=model.predict(data.map(x=>(x.user,x.product)))
val predictionAndRatings = predictions.map(x=>{((x.user,x.product),x.rating)}).join(data.map(x=>((x.user,x.product),x.rating))).values
math.sqrt(predictionAndRatings.map(x=>(x._1-x._2)*(x._1-x._2)).mean())
}
//第四步骤,使用不同的参数训练模型,并且选择RMSE最小的模型,规定参数的范围
//隐藏因子数:8或者12
//正则化系数,0.01或者0.1选择,迭代次数为10或者20,训练8个模型
val ranks = List(8,12)
val lambdas = List(0.01,0.1)
val numiters = List(10,20)
var bestModel:Option[MatrixFactorizationModel]=None
var bestValidationRmse=Double.MaxValue
var bestRank=0
var bestLamdba = -1.0
var bestNumIter=1
for(rank<-ranks;lambda<-lambdas;numiter<-numiters){
println(rank+"-->"+lambda+"-->"+numiter)
val model = ALS.train(training,rank,numiter,lambda)
val valadationRmse=computeRmse(model,validation)
if(valadationRmse<bestValidationRmse){
bestModel=Some(model)
bestValidationRmse=valadationRmse
bestRank=rank
bestLamdba=lambda
bestNumIter=numiter
}
}
val testRmse = computeRmse(bestModel.get,test)
println("测试数据的rmse为:"+testRmse)
println("范围内的最后模型参数为:")
println("隐藏因子数:"+bestRank)
println("正则化参数:"+bestLamdba)
println("迭代次数:"+bestNumIter)
//步骤5可以对比使用协同过滤和不适用协同过滤(使用平均分来做预测结果)能提升多大的预测效果。
//计算训练样本和验证样本的平均分数
val meanR = training.union(validation).map(x=>x.rating).mean()
//这就是使用平均分做预测,test样本的rmse
val baseRmse=math.sqrt(test.map(x=>(meanR-x.rating)*(meanR-x.rating)).mean())
val improvement =(baseRmse-testRmse)/baseRmse*100
println("使用了ALS协同过滤算法比使用评价分作为预测的提升度为:"+improvement)
}
}
4使用ALS模型进行预测
package org.wq.scala.ml
import org.apache.log4j.{Level, Logger}
import org.apache.spark.mllib.recommendation.{MatrixFactorizationModel, Rating}
import org.apache.spark.{SparkConf, SparkContext}
/**
* Created by Administrator on 2016/10/25.
*/
object ALSModelTopn {
def main(args: Array[String]): Unit = {
//给用户推荐
val conf = new SparkConf().setAppName("ALS_mllib_best_param").setMaster("local").set("spark.sql.warehouse.dir","E:/ideaWorkspace/ScalaSparkMl/spark-warehouse")
val sc = new SparkContext(conf)
Logger.getRootLogger.setLevel(Level.WARN)
val movie = sc.textFile("data/mllib/sample_movielens_ratings.txt")
val ratings = movie.map(line=>{
val fields = line.split("::")
val rating = Rating(fields(0).toInt,fields(1).toInt,fields(2).toDouble)
val timestamp =fields(3).toLong%5
(rating)
})
val model= MatrixFactorizationModel.load(sc,"data/mllib/t")
//选择一个用户
val user=5
val myRating = ratings.filter(x=>x.user==5)
//该用户已经消费了的物品
val myRateItem = myRating.map(x=>x.product).collect().toSet
//给用户5推荐前评分前10的物品
val recommendations = model.recommendProducts(user,10)
recommendations.map(x=>{
println(x.user+"-->"+x.product+"-->"+x.rating)
})
}
}提交部署
1提交寻找最优参数的jar
提交部署求最优参数的那个jar,这就把最优参数简单的打印出来,如果要周期的自迭代更新参数的话,就写在数据库或者配置文件中,当训练的时候,就从数据库或者配置文件读。
首先需要把上面的第三个程序修改一下,修改如下,因为要提交给集群嘛,所以不能指定master为local了,参数从命令行传入。把jar上传到master节点的目录下,data需要上传到所有的slaves.
if(args.length!=1){
println(“请输入1个参数 购物篮数据路径”)
System.exit(0)
}
val conf = new SparkConf().setAppName(“ALS_mllib_best_param”)
以后所有的提交都需要修改conf的,以后就不说了
jar与数据目录如下:

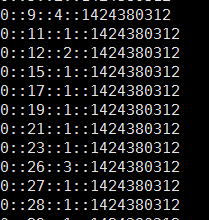
数据长下面这个样子,用户id,物品id,评分,时间戳,用户id和物品id必须是整型,如果你的不是,那么必须进行一次映射:
把数据传到slave节点
scp sample_movielens_ratings.txt spark@slave1:/home/jar/data/
scp sample_movielens_ratings.txt spark@slave2:/home/jar/data/提交job
spark-submit –class org.wq.scala.ml.ALSRecommendMllibBestParam –master spark://master:7077 –executor-memory 700m –num-executors 1 /home/jar/ALSRecommendMllibBestParam.jar /home/jar/data/sample_movielens_ratings.txt
运行结果如下:
也给大家看下job运行的过程
http://192.168.247.132:4040/jobs/
2把求得的最好参数带入mllib写的算法中,训练形成模型
提交Job
spark-submit –class org.wq.scala.ml.ALSRecommendMllib –master spark://master:7077 –executor-memory 700m –num-executors 1 /home/jar/ALSRecommendMllib.jar –rank 8 –numIterations 10 –lambda 0.1 /home/jar/data/sample_movielens_ratings.txt /home/jar/model/AlsModel
悲剧的报错了
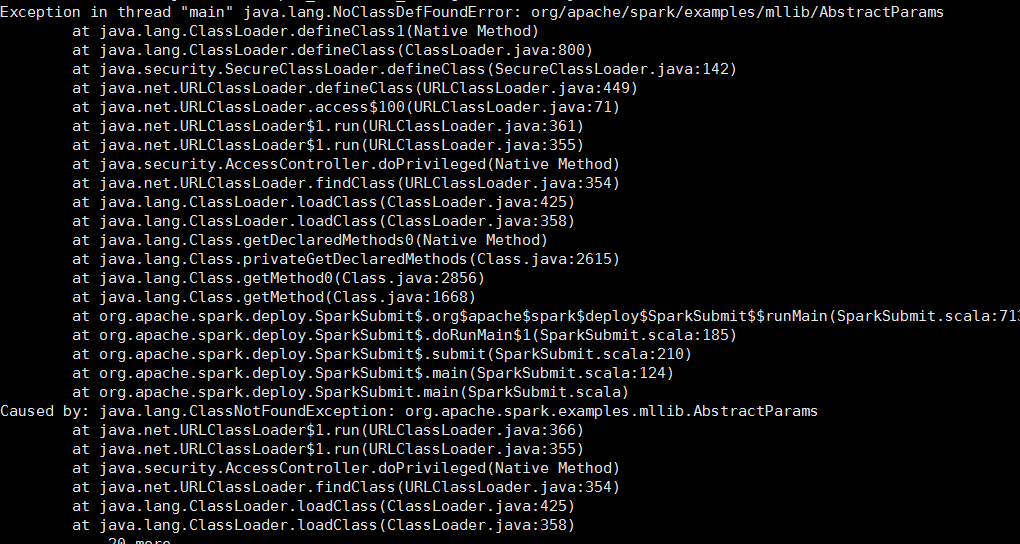
这个错误很明显是缺少包spark-examples_2.11-2.0.0.jar,这个包在example目录下的。
两个种解决方法:
1修改/etc/profile,把example/jars加入classpath.
2把jar复制到目录
sparkhome/jars目录下,因为
spark_home/jars这个目录在环境变量中,这里采用第二种.
修改之后的运行结果为:
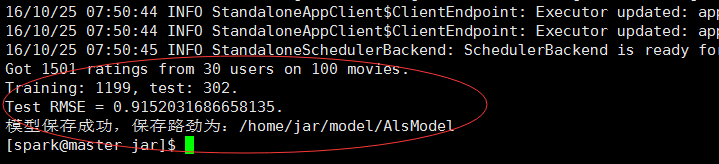
3调用模型,得出推荐
到这里模型就训练好了,这个模型可以定时训练,crontab就可以实现,训练好的模型,使用用户数据预测分数。
就不提交到集群运行了,因为这是demo而已,真实应该为提供接口,别人来调用
总结:
1矩阵分解的几种算法
2spark使用矩阵分解的几种方式,1ml 包中使用,2mllib包中的使用,其实有不调用包自己写的案列(可以去看看哈,就在example目录)
3使用ALS做推荐的一个比较详细的流程:1自迭代确定比较优的参数是,2使用参数训练模型,3使用模型推荐topn的物品给用户
4讲了怎么自迭代ALS算法参数,感觉这个还重要点
5提交spark的报了一个错误,已经错误解决方式
6好多细节都没写,感觉要写的有好多,也不是很完善,时间不够,只是提供了核心代码和思路
疑问:在做的过程中,我发现spark的job查看,只有在job运行的时候才可以查看,其他时候不行
http://192.168.247.132:4040/jobs/
这个应该是可以随时查看的,应该是spark的日志和查看jobs的服务要一直开启才行,希望对spark集群熟悉的人求解,跪谢
















 5520
5520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











