







1.前言
1.1声明
文章中的文字可能存在语法错误以及标点错误,请谅解;
如果在文章中发现代码错误或其它问题请告知,感谢!
2.关于链表
2.1什么是链表
链表可以看成一种在物理存储单元上的非连续、非顺序存储的数据结构,该数据结构中的结点(数据元素)逻辑顺序通过链表中指针链接次序实现。结点可以在程序运行是动态生成。每一个结点包括两部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域。
链表可以分为 单向链表 双向链表 循环链表 等。
单链表指链表中的每个结点,有指向该链表中这个结点的下一个结点或者为空的指针,是一种线性链表。

单链表(不带头节点)

单链表(带头节点)
*关于头节点知识可以参看下面。
双链表和单链表的不同之处在于,每个链表结点中既有指向下一个结点的指针,又有指向前一个结点的指针,其中每个结点都有两种指针,即pPrev和pNEXT。pPrev指针指向左边结点,pNEXT指针指向右边结点。

双链表(不带头节点)

双链表(带头节点)
循环链表指的是在单向链表和双向链表的基础上,将两种链表的最后一个结点指向第一个结点从而实现循环。
2.2链表的意义
链表的出现是解决其他数据结构在应用中出现的局限性,例如数组,在数组中所有元素的的类型必须相同,在实际编程应用中,我们希望可以存储的不同类型数据;并且一般来说数组在定义的时候需要指出其大小(除了Linux内核中可以使用变长数组,C++中也支持变长数组);另外数组中某个元素的移动会造成其它元素的大面积移动,存在效率问题。
2.3链表的作用
解决其他数据结构在应用中出现的局限性,实现数据元素的存储按一定顺序储存,允许在任意位置插入和删除结点,提高效率。
2.4链表的优点和缺点
链表的优点:
1.采用动态内存分配,物理存储单元不用连续,能够有效的分配和利用内存资源;
2.节点插入和删除时不需要移动其他元素,不需要内存空间的重组。
链表的缺点:
1.不能进行索引访问,只能从头结点(或头指针)开始顺序查找;
2.数据结构较为复杂,需要大量的指针操作,容易出错。
3单链表的实现
3.1单链表的实现步骤
单链表从创建到使用的需要如下步骤:
1.定义节点类型;
2.定义一个头指针;
3.创建第一个结点 ,并将头指针指向第一个节点;
4.继续创建节点,将前一个节点的指针指向新创建节点的地址;
5.以此类推,需要多少长度链表按照上面步骤进行节点增加,最终形成一个完整链表。
3.2构建一个简单链表(从链表尾部插入节点)
按照3.1首先定义节点类型,要注意每个结点包括有效数据以及指针两个部分,构建结点的方法是构建一个结构体,为了简明起见,定义一个数据为int型,指针为struct node*类型的节点:
struct node
{
int data;
struct node *pNext;
}需要强调的是,该结构体只是给结点的定义一个类型,并不占用内存,只有使用该类型创建结点的时候,创建出来的节点才会占用一定的内存空间。
然后,定义一个头指针(不是头节点,注意头指针和头节点的区别),头指针的类型就是节点类型,不过头指针中的数据区不存储数据,头指针的指针部分指向第一个节点:
struct node *pHeader = NULL;接着,使用堆内存创建节点:
struct node * NodeCreate(int data)
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if(NULL == p)
{
printf("Failed to malloc\n");
return NULL;
}
memset(p, 0,sizeof(struct node));
p->data = data;
p->pNext = NULL;
return NULL;
}使用这个函数,创建第一个节点,并将头指针指向这个节点(简明起见,设定每个节点数据区存储节点在链表中的编号):
struct node* pHeader = NodeCreate(0);使用这个函数,继续创建节点NodeCreate(1),这样我们有了一个只有一个节点的链表以及一个新节点new,下面就要把这个新节点插入这个链表中,也就是将前一个节点的指针指向新创建节点的地址:pHeader->pNext = new,实现这个指向,可以分为两步骤:
1.找到链表最后一个节点;
2.将新的节点和链表最后一个节点连接起来。
将两个节点连接函数:
void TailInsert(struct node* pH,struct node* new)
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
p->pNext = new;
}以上,链表所需的函数已经完成,现在利用上述函数构建一个从尾部插入节点的三链表函数:
#include < stdio.h >
#include < string.h >
#include < stdio.h >
struct node
{
int data;
struct node *pNext;
}
struct node* NodeCreate(int data);
void TailInsert(struct node* pH,struct node* new);
int main(void)
{
struct node* pHeader = NodeCreate(0);
TailInsert(pHeader, NodeCreate(1);
TailInsert(pHeader, NodeCreate(2);
printf("node data1 is %d\n",pHeader->pNext);
printf("node data2 is %d\n",pHeader->pNext->data);
printf("node data3 is %d\n",pHeader->pNext->pNext->data);
return 0;
}
void TailInsert(struct node* pH,struct node* new)
{
struct node *p = pH;
while(NULL != p->pNext)
{
p = p->pNext;
}
p->pNext = new;
}
struct node * NodeCreate(int data)
{
struct node* p = (struct node*)malloc(sizeof(struct node));
if(NULL == p)
{
printf("Failed to malloc\n");
return NULL;
}
memset(p, 0,sizeof(struct node));
p->data = data;
p->pNext = NULL;
return NULL;
}有时候,根据业务要求或者方便链表查找,会将头指针指向的第一个节点作为头节点使用。头节点有如下特点:紧跟头指针后面,不一定和链表中数据节点的类型一样(头节点的数据部分可以为空或者业务要求为节点总数或者其它需要存储的数据),例如下面就是某个链表的头节点和数据节点:
头节点
typedef struct stMessageListHeadNode
{
int iListCurrentNodeNum; //当前队列中节点的数量
int iListMax; //队列支持的最大节点数
MESSAGE_NODE *pFirst; //指向队列的第一个结点
MESSAGE_NODE *pLast; //指向队列的最后一个结点
}MESSAGE_LIST_HEAD_NODE;数据节点
typedef struct stMessageNode
{
long locomotive_num;
int len;
void *pData; //节点携带信息的内存地址
MESSAGE_NODE *pNext; //指向next节点
}MESSAGE_NODE;仍然为了简明起见,下面使用同一类型定义头节点和数据节点,即struct node。
除了从链表尾节点插入节点,也有从链表尾部插入节点的方法,步骤如下:
1.新节点的pNext指向原来的第一个节点首地址,即新节点和原来的第一个节点相连;
2.头节点的pNext指向新节点的首地址,即头节点和新节点相连。
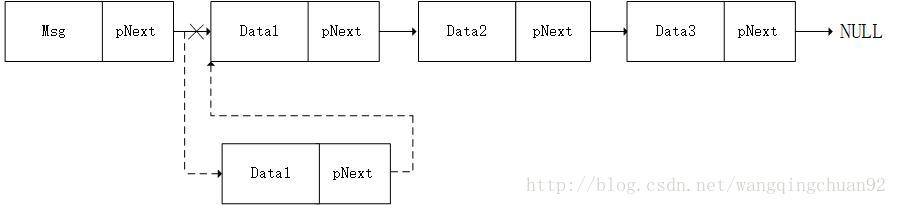
从链表尾部插入节点函数:
void TailInsert(struct node* pH,struct node* new)
{
new->pNext = pH->pNext;//新节点的pNext指向原来的第一个节点
pH->pNext = new;//头节点pNext指向新节点
}3.3单链表遍历
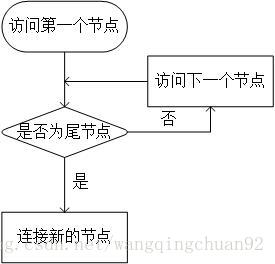
链表是用来存储数据的,那么要使用链表里的数据就必须要取出来,这只用到遍历,即将链表中每一个节点中的数据取出来。
链表遍历步骤:
1.指针p方位第一个有效节点并判断是否为尾节点并取出该节点数据,若不是尾节点,将指针移至下一个节点;
2.重复步骤1,若判断是尾节点,取出数据,停止遍历。
单链表带头节点时遍历函数:
//pH为指向单链表的头指针
void SearchList(struct node* pH)
{
struct node* p = pH->pNext;
while(NULL != p->pNext)
{
p->pNext;
printf("node data: %d\n",p->data);
}
}单链表不带头节点时遍历函数:
//pH为指向单链表的头指针
void SearchList(struct node* pH)
{
struct node* p = pH;
while(NULL != p->pNext)
{
printf("node data: %d\n",p->data);
p->pNext;
}
printf("node data: %d\n",p->data);
} 3.4单链表删除节点
通过上述,我们知道链表是用来存储数据的,既然有存储数据,就有删除数据,当有的时候链表中某个节点的数据 我们不想要了,就需要删除该节点。
对于删除链表节点,有两种情况:删除的节点为尾节点,删除的节点为普通节点。
删除普通节点
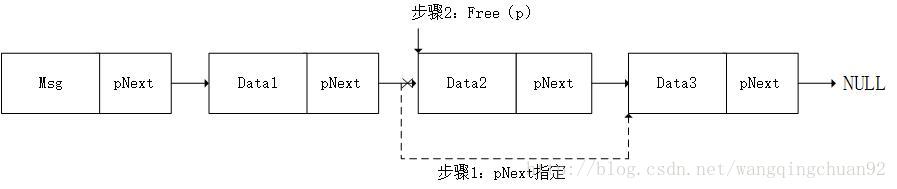
删除尾节点

删除节点函数
int DeleteNode(struct node* pH,int data)
{
struct node* p = pH;
struct node* pPrev = NULL;
while(NULL != p->pNext)
{
pPrev = p;
p = p->pNext;
if(p->data == data)
{
if(NULL == p->pNext);
{
pPrev->pNext = NULL;
free(p);
}
else
{
pPrev->pNext = p->pNext;
free(p);
}
return 0;
}
}
printf("No delete node!\n");
return -1;
}
以上就是链表的基本操纵,需要注意的是,在实际项目工程中,一般会在将头指针和互斥锁封装在一个结构体中,这样在别的线程在对该链表进行增减操作时,首先将互斥锁上锁,加上了一个保护,达到保证链表增减的正常。
以上。
参考文档:
http://blog.csdn.net/wislosophia/article/details/71856514
http://blog.csdn.net/lovter_/article/details/52769793
https://www.cnblogs.com/thunder-wu/p/6623872.html
https://baike.baidu.com/item/%E9%93%BE%E8%A1%A8/9794473?fr=aladdin
http://blog.csdn.net/chenyufeng1991/article/details/50730071















 5051
5051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









