







首先,回归问题就是需要求解的结果是一个数值,目标值是一系列的数值。回归问题例子如下图所示。
在这里我们以预测宝可梦的CP值作为问题背景。
为了求解回归问题,给回归问题确定一个合适的函数,我们通常需要三步。第一步,Model;第二步,Goodness of function;第三步,Best Function.


第一步 Model
针对问题,我们首先需要确定模型,该模型中可能有很多function用来求解宝可梦的CP值,如下图。

第二步 Goodness of function
接下来,我们使用训练集训练模型,评估每个函数的得分。当我们使用训练集训练了模型之后,使用该模型预测测试集宝可梦的CP值,计算测试集预测结果和真实结果的差异,该差异来评估每个函数的得分。为了表现测试集预测结果和真实结果的差异,我们定义一个损失函数,对于回归问题,我们损失函数的定义如下。
其中10表示测试集的样本数为10,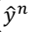
下图表示训练模型,以及根据损失函数评判每个函数的得分。
使用梯度下降训练模型,在测试集上得到每个函数的得分。


第三步 Best Function
根据下图确定最优的函数。
在根据梯度下降更新权重时,一般很难达到全局最优点,通常都会进入局部最优点,进入局部最优点也是可以拿到较好的效果。如果进入鞍点(鞍点指的是不是极值点,但是其梯度为0)或者高原区(即损失函数基本平滑,不对对权重有太大的更新),此时的结果不会太好。
在这三步结束,就可以解决宝可梦CP值预测的回归问题。
接下来尝试增加特征来提高效果,发现增加特征之后模型在训练集和测试集上的效果都越来越好,但是当增加过多的特征时会导致训练集上的效果更好,但是测试集的效果下降,此时模型为过拟合。如下面两幅图所示。
所以考虑增加训练集,但是当增加了训练集之后发现训练集的分布完全不同(主要是因为之前的训练集太小,没有将宝可梦的普遍分布表示出来),导致我们之前的模型完全不能用。所以我们又回到了确定模型,计算函数的得分,确定最优函数这三步。这次新的模型仍然存在过拟合现象。
为了一定程度上解决过拟合问题,我们加入正则化
如上图所示,加入正则化是为了平滑损失函数曲线,使得当输入数据发生一些变化时,对loss函数不会产生太大的影响,这样测试集就能够产生和训练集类似的结果,所以使得测试集上有较好的效果。在这里可以看到是对权重进行正则化,没有对偏置进行正则化,主要原因是因为偏置只是管理曲线的上下平移,对于曲线的平滑没有用,所以没必要对偏置做正则化




















 3303
3303











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









