







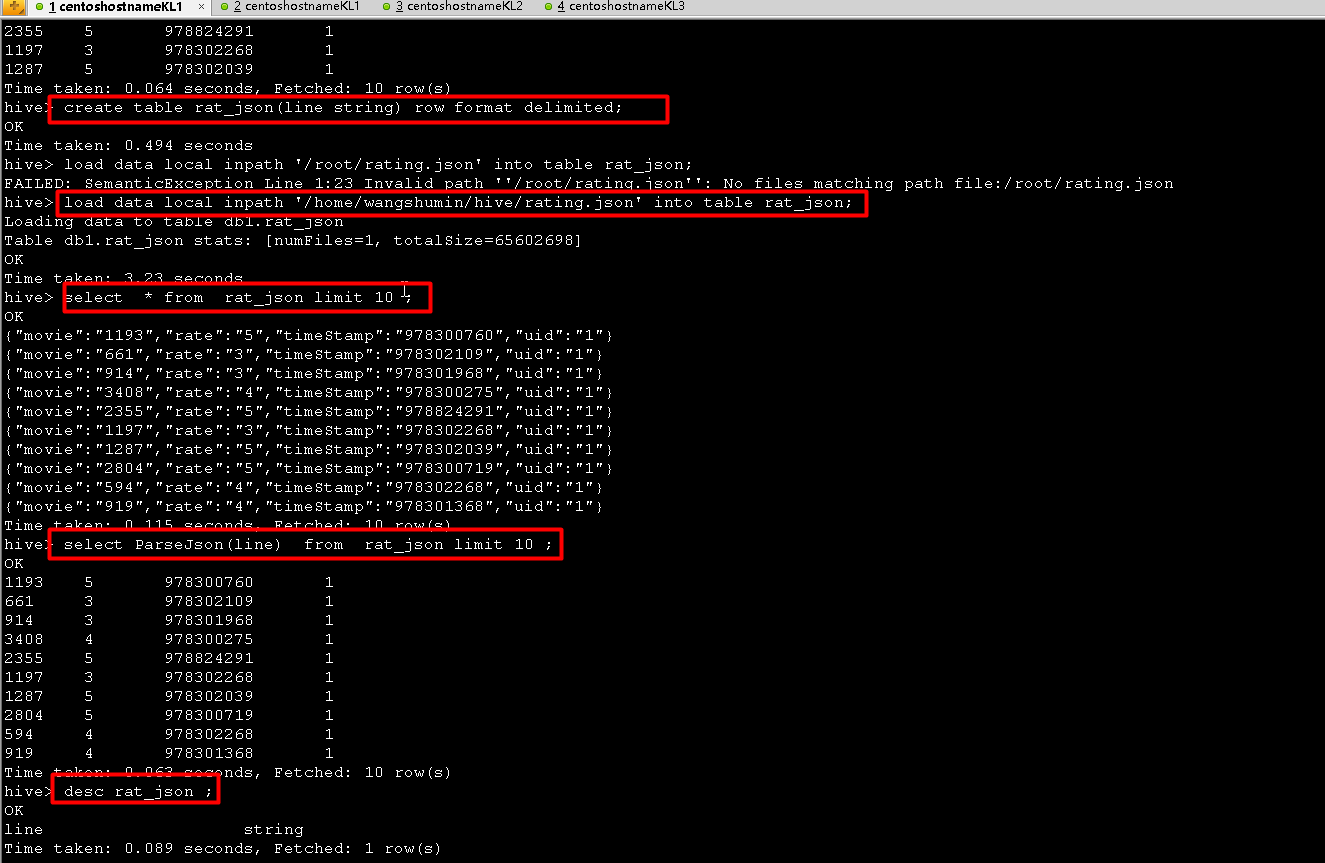
hive> create table rat_json(line string) row format delimited;
OKTime taken: 0.494 seconds
hive> load data local inpath '/root/rating.json' into table rat_json;
FAILED: SemanticException Line 1:23 Invalid path ''/root/rating.json'': No files matching path file:/root/rating.json
hive> load data local inpath '/home/wangshumin/hive/rating.json' into table rat_json;
Loading data to table db1.rat_json
Table db1.rat_json stats: [numFiles=1, totalSize=65602698]
OK
Time taken: 3.23 seconds
hive> select * from rat_json limit 10 ;
OK
{"movie":"1193","rate":"5","timeStamp":"978300760","uid":"1"}
{"movie":"661","rate":"3","timeStamp":"978302109","uid":"1"}
{"movie":"914","rate":"3","timeStamp":"978301968","uid":"1"}
{"movie":"3408","rate":"4","timeStamp":"978300275","uid":"1"}
{"movie":"2355","rate":"5","timeStamp":"978824291","uid":"1"}
{"movie":"1197","rate":"3","timeStamp":"978302268","uid":"1"}
{"movie":"1287","rate":"5","timeStamp":"978302039","uid":"1"}
{"movie":"2804","rate":"5","timeStamp":"978300719","uid":"1"}
{"movie":"594","rate":"4","timeStamp":"978302268","uid":"1"}
{"movie":"919","rate":"4","timeStamp":"978301368","uid":"1"}
Time taken: 0.115 seconds, Fetched: 10 row(s)
hive> select ParseJson(line) from rat_json limit 10 ;
OK
1193 5 978300760 1
661 3 978302109 1
914 3 978301968 1
3408 4 978300275 1
2355 5 978824291 1
1197 3 978302268 1
1287 5 978302039 1
2804 5 978300719 1
594 4 978302268 1
919 4 978301368 1
Time taken: 0.063 seconds, Fetched: 10 row(s)
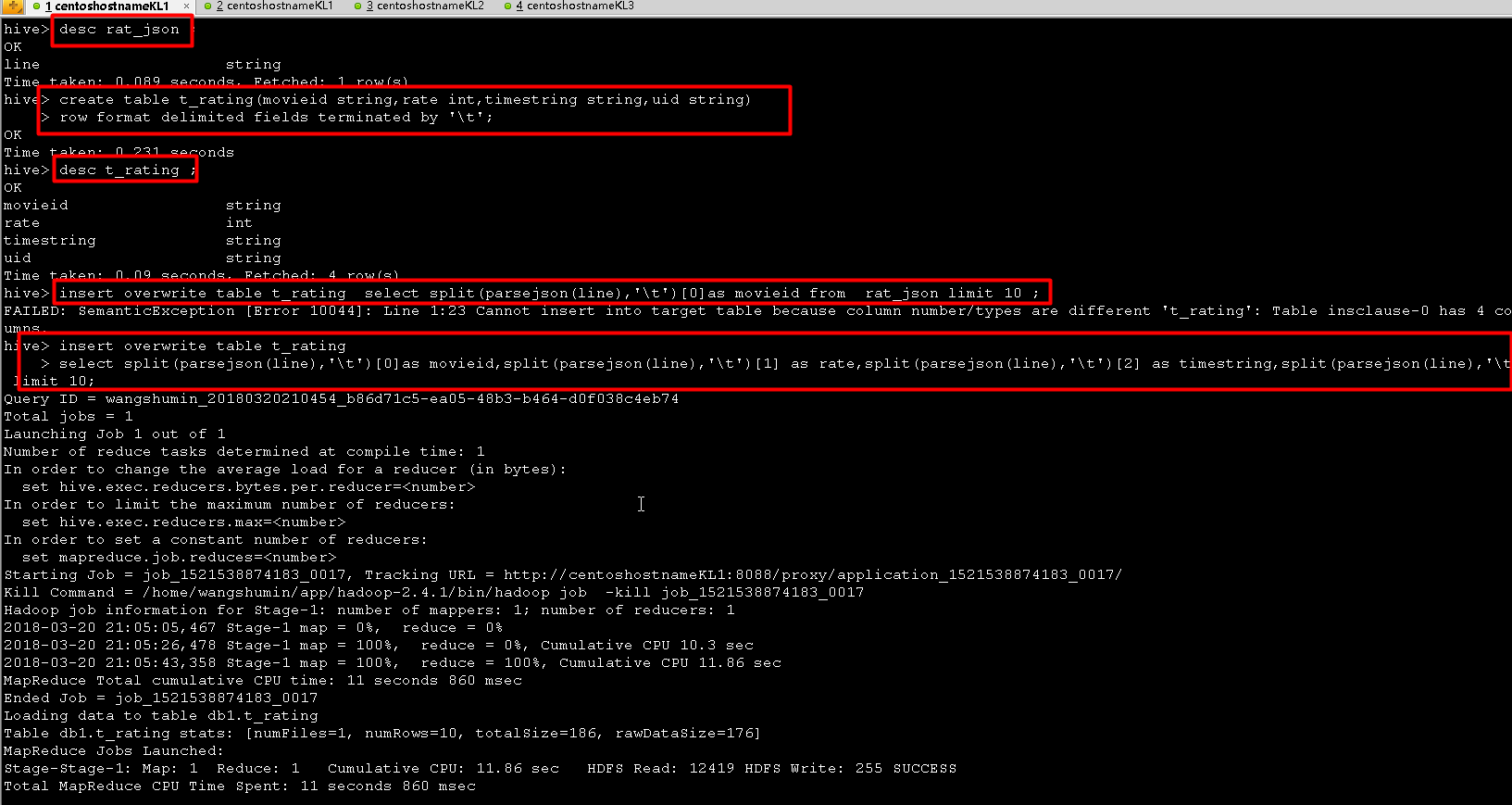
hive> desc rat_json ;
OK
line string
Time taken: 0.089 seconds, Fetched: 1 row(s)
hive> create table t_rating(movieid string,rate int,timestring string,uid string)
> row format delimited fields terminated by '\t';
OK
Time taken: 0.231 seconds
hive> desc t_rating ;
OK
movieid string
rate int
timestring string
uid string
Time taken: 0.09 seconds, Fetched: 4 row(s)
hive> insert overwrite table t_rating select split(parsejson(line),'\t')[0]as movieid from rat_json limit 10 ;
FAILED: SemanticException [Error 10044]: Line 1:23 Cannot insert into target table because column number/types are different 't_rating': Table insclause-0 has 4 columns, but query has 1 columns.
hive> insert overwrite table t_rating
> select split(parsejson(line),'\t')[0]as movieid,split(parsejson(line),'\t')[1] as rate,split(parsejson(line),'\t')[2] as timestring,split(parsejson(line),'\t')[3] as uid from rat_json limit 10;
Query ID = wangshumin_20180320210454_b86d71c5-ea05-48b3-b464-d0f038c4eb74
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks determined at compile time: 1
In order to change the average load for a reducer (in bytes):
set hive.exec.reducers.bytes.per.reducer=<number>
In order to limit the maximum number of reducers:
set hive.exec.reducers.max=<number>
In order to set a constant number of reducers:
set mapreduce.job.reduces=<number>
Starting Job = job_1521538874183_0017, Tracking URL = http://centoshostnameKL1:8088/proxy/application_1521538874183_0017/
Kill Command = /home/wangshumin/app/hadoop-2.4.1/bin/hadoop job -kill job_1521538874183_0017
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1
2018-03-20 21:05:05,467 Stage-1 map = 0%, reduce = 0%
2018-03-20 21:05:26,478 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 10.3 sec
2018-03-20 21:05:43,358 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 11.86 sec
MapReduce Total cumulative CPU time: 11 seconds 860 msec
Ended Job = job_1521538874183_0017
Loading data to table db1.t_rating
Table db1.t_rating stats: [numFiles=1, numRows=10, totalSize=186, rawDataSize=176]
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Reduce: 1 Cumulative CPU: 11.86 sec HDFS Read: 12419 HDFS Write: 255 SUCCESS
Total MapReduce CPU Time Spent: 11 seconds 860 msec
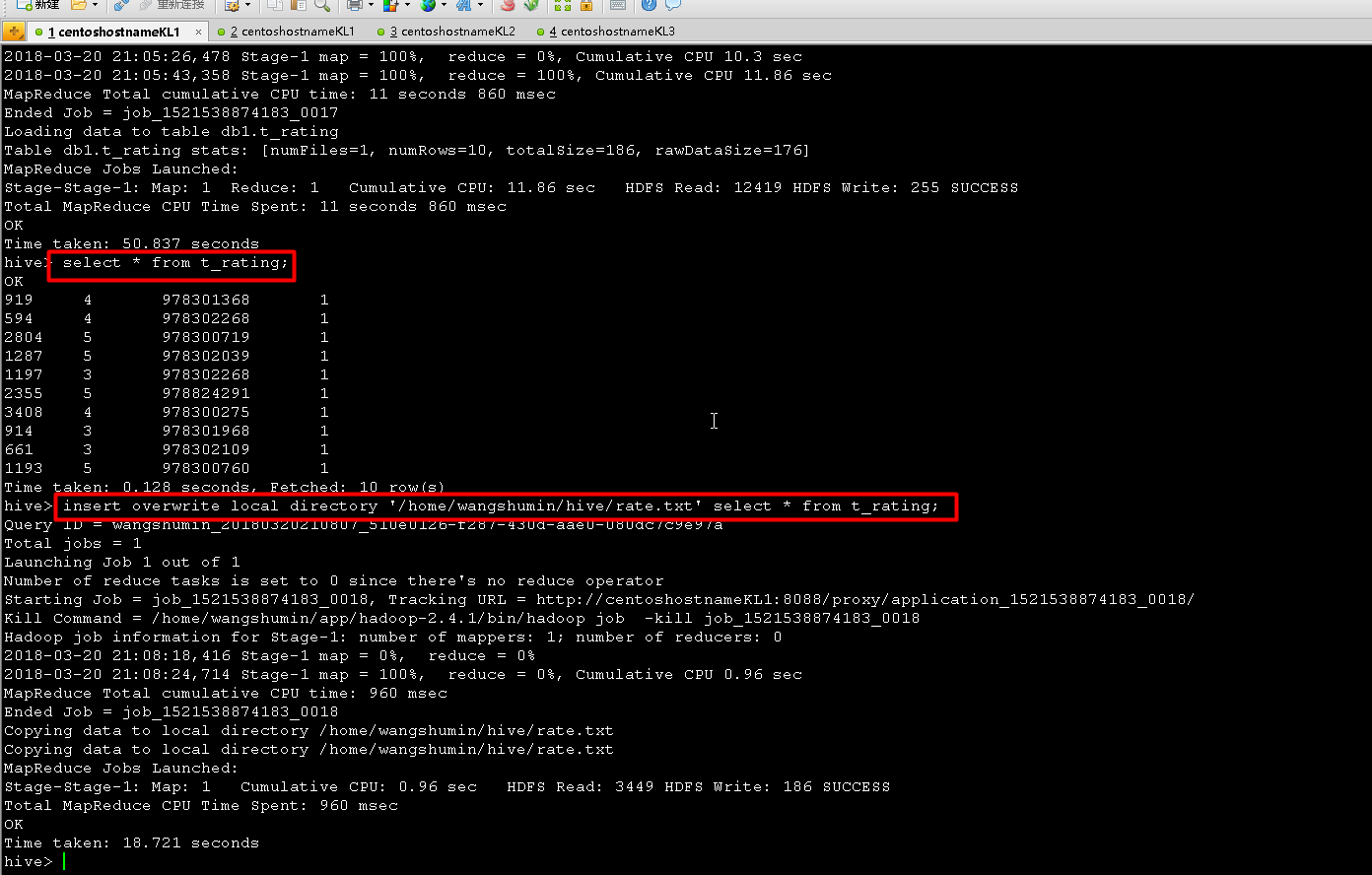
OK
Time taken: 50.837 seconds
hive> select * from t_rating;
OK
919 4 978301368 1
594 4 978302268 1
2804 5 978300719 1
1287 5 978302039 1
1197 3 978302268 1
2355 5 978824291 1
3408 4 978300275 1
914 3 978301968 1
661 3 978302109 1
1193 5 978300760 1
Time taken: 0.128 seconds, Fetched: 10 row(s)
hive> insert overwrite local directory '/home/wangshumin/hive/rate.txt' select * from t_rating;
Query ID = wangshumin_20180320210807_510e0126-f287-430d-aae0-080dc7c9e97a
Total jobs = 1
Launching Job 1 out of 1
Number of reduce tasks is set to 0 since there's no reduce operator
Starting Job = job_1521538874183_0018, Tracking URL = http://centoshostnameKL1:8088/proxy/application_1521538874183_0018/
Kill Command = /home/wangshumin/app/hadoop-2.4.1/bin/hadoop job -kill job_1521538874183_0018
Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 0
2018-03-20 21:08:18,416 Stage-1 map = 0%, reduce = 0%
2018-03-20 21:08:24,714 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 0.96 sec
MapReduce Total cumulative CPU time: 960 msec
Ended Job = job_1521538874183_0018
Copying data to local directory /home/wangshumin/hive/rate.txt
Copying data to local directory /home/wangshumin/hive/rate.txt
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 Cumulative CPU: 0.96 sec HDFS Read: 3449 HDFS Write: 186 SUCCESS
Total MapReduce CPU Time Spent: 960 msec
OK
Time taken: 18.721 seconds
hive>















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









