







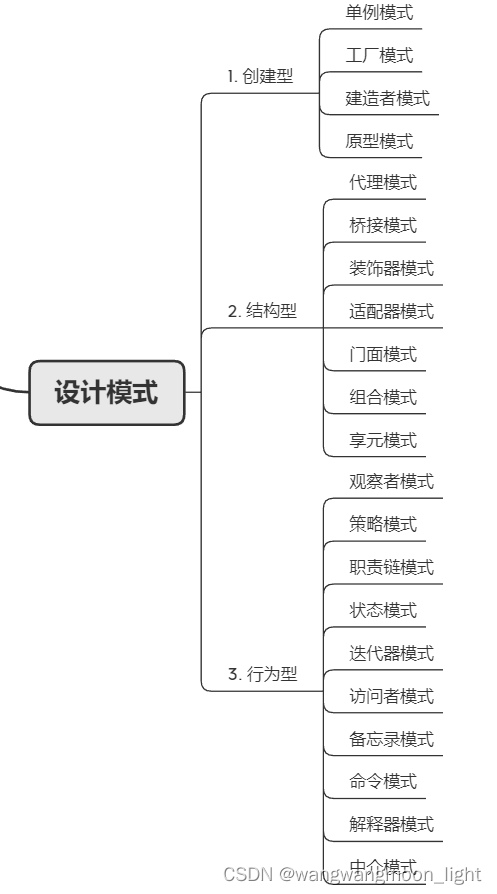
我们知道,创建型设计模式主要解决“对象的创建”问题,结构型设计模式主要解决“类或对象的组合或组装”问题,那行为型设计模式主要解决的就是“类或对象之间的交互”问题。
观察者模式
观察者模式(Observer Design Pattern)也被称为发布订阅模式(Publish-Subscribe Design Pattern)。在 GoF 的《设计模式》一书中,它的定义是这样的:Define a one-to-many dependency between objects so that when one object changes state, all its dependents are notified and updated automatically.翻译成中文就是:在对象之间定义一个一对多的依赖,当一个对象状态改变的时候,所有依赖的对象都会自动收到通知。
一般情况下,被依赖的对象叫作被观察者(Observable),依赖的对象叫作观察者(Observer)。不过,在实际的项目开发中,这两种对象的称呼是比较灵活的,有各种不同的叫法,比如:Subject-Observer、Publisher-Subscriber、Producer-Consumer、EventEmitter-EventListener、Dispatcher-Listener。不管怎么称呼,只要应用场景符合刚刚给出的定义,都可以看作观察者模式
设计模式要干的事情就是解耦,创建型模式是将创建和使用代码解耦,结构型模式是将不同功能代码解耦,行为型模式是将不同的行为代码解耦,具体到观察者模式,它将观察者和被观察者代码解耦。借助设计模式,我们利用更好的代码结构,将一大坨代码拆分成职责更单一的小类,让其满足开闭原则、高内聚低耦合等特性,以此来控制和应对代码的复杂性,提高代码的可扩展性。
观察者模式的应用场景非常广泛,小到代码层面的解耦,大到架构层面的系统解耦,再或者一些产品的设计思路,都有这种模式的影子,比如,邮件订阅、RSS Feeds,本质上都是观察者模式。不同的应用场景和需求下,这个模式也有截然不同的实现方式,有同步阻塞的实现方式,也有异步非阻塞的实现方式;有进程内的实现方式,也有跨进程的实现方式。
策略模式
策略模式。在实际的项目开发中,这个模式也比较常用。最常见的应用场景是,利用它来避免冗长的 if-else 或 switch 分支判断。不过,它的作用还不止如此。它也可以像模板模式那样,提供框架的扩展点等等。
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以,客户端代码基于接口而非实现编程,可以灵活地替换不同的策略。
我们先通过一个例子来看下,if-else 或 switch-case 分支判断逻辑是如何产生的。具体的代码如下所示。在这个例子中,我们没有使用策略模式,而是将策略的定义、创建、使用直接耦合在一起。
定义一系列算法,把它们一个个封装起来,可以相互替换
public class OrderService {
public double discount(Order order) {
double discount = 0.0;
OrderType type = order.getType();
if (type.equals(OrderType.NORMAL)) { // 普通订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.GROUPON)) { // 团购订单
//...省略折扣计算算法代码
} else if (type.equals(OrderType.PROMOTION)) { // 促销订单
//...省略折扣计算算法代码
}
return discount;
}
}
如何来移除掉分支判断逻辑呢?那策略模式就派上用场了。我们使用策略模式对上面的代码重构,将不同类型订单的打折策略设计成策略类,并由工厂类来负责创建策略对象。具体的代码如下所示:
// 策略的定义
public interface DiscountStrategy {
double calDiscount(Order order);
}
// 省略NormalDiscountStrategy、GrouponDiscountStrategy、PromotionDiscountStrategy类代码...
// 策略的创建
public class DiscountStrategyFactory {
private static final Map<OrderType, DiscountStrategy> strategies = new HashMap<>();
static {
strategies.put(OrderType.NORMAL, new NormalDiscountStrategy());
strategies.put(OrderType.GROUPON, new GrouponDiscountStrategy());
strategies.put(OrderType.PROMOTION, new PromotionDiscountStrategy());
}
public static DiscountStrategy getDiscountStrategy(OrderType type) {
return strategies.get(type);
}
}
// 策略的使用
public class OrderService {
public double discount(Order order) {
OrderType type = order.getType();
DiscountStrategy discountStrategy = DiscountStrategyFactory.getDiscountStrategy(type);
return discountStrategy.calDiscount(order);
}
}
重构之后的代码就没有了 if-else 分支判断语句了。实际上,这得益于策略工厂类。在工厂类中,我们用 Map 来缓存策略,根据 type 直接从 Map 中获取对应的策略,从而避免 if-else 分支判断逻辑。等后面讲到使用状态模式来避免分支判断逻辑的时候,你会发现,它们使用的是同样的套路。本质上都是借助“查表法”,根据 type 查表(代码中的 strategies 就是表)替代根据 type 分支判断。
职责链模式
职责链模式的英文翻译是 Chain Of Responsibility Design Pattern。在 GoF 的《设计模式》中,它是这么定义的:Avoid coupling the sender of a request to its receiver by giving more than one object a chance to handle the request. Chain the receiving objects and pass the request along the chain until an object handles it.翻译成中文就是:将请求的发送和接收解耦,让多个接收对象都有机会处理这个请求。将这些接收对象串成一条链,并沿着这条链传递这个请求,直到链上的某个接收对象能够处理它为止。
在职责链模式中,多个处理器(也就是刚刚定义中说的“接收对象”)依次处理同一个请求。一个请求先经过 A 处理器处理,然后再把请求传递给 B 处理器,B 处理器处理完后再传递给 C 处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。关于职责链模式,我们先来看看它的代码实现。结合代码实现,你会更容易理解它的定义。职责链模式有多种实现方式,我们这里介绍两种比较常用的。
职责链模式的应用场景举例
职责链模式的原理和实现讲完了,我们再通过一个实际的例子,来学习一下职责链模式的应用场景。对于支持 UGC(User Generated Content,用户生成内容)的应用(比如论坛)来说,用户生成的内容(比如,在论坛中发表的帖子)可能会包含一些敏感词(比如涉黄、广告、反动等词汇)。针对这个应用场景,我们就可以利用职责链模式来过滤这些敏感词。对于包含敏感词的内容,我们有两种处理方式,一种是直接禁止发布,另一种是给敏感词打马赛克(比如,用 *** 替换敏感词)之后再发布。第一种处理方式符合 GoF 给出的职责链模式的定义,第二种处理方式是职责链模式的变体。我们这里只给出第一种实现方式的代码示例,如下所示,并且,我们只给出了代码实现的骨架,具体的敏感词过滤算法并没有给出,你可以参看我的另一个专栏《数据结构与算法之美》中多模式字符串匹配的相关章节自行实现。
我们一块儿总结回顾一下,你需要重点掌握的内容。在职责链模式中,多个处理器依次处理同一个请求。一个请求先经过 A 处理器处理,然后再把请求传递给 B 处理器,B 处理器处理完后再传递给 C 处理器,以此类推,形成一个链条。链条上的每个处理器各自承担各自的处理职责,所以叫作职责链模式。
在 GoF 的定义中,一旦某个处理器能处理这个请求,就不会继续将请求传递给后续的处理器了。当然,在实际的开发中,也存在对这个模式的变体,那就是请求不会中途终止传递,而是会被所有的处理器都处理一遍。职责链模式有两种常用的实现。一种是使用链表来存储处理器,另一种是使用数组来存储处理器,后面一种实现方式更加简单。
状态模式
状态模式一般用来实现状态机,而状态机常用在游戏、工作流引擎等系统开发中。不过,状态机的实现方式有多种,除了状态模式,比较常用的还有分支逻辑法和查表法。今天,我们就详细讲讲这几种实现方式,并且对比一下它们的优劣和应用场景。
什么是有限状态机?
有限状态机,英文翻译是 Finite State Machine,缩写为 FSM,简称为状态机。状态机有 3 个组成部分:状态(State)、事件(Event)、动作(Action)。其中,事件也称为转移条件(Transition Condition)。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。
“超级马里奥”游戏不知道你玩过没有?在游戏中,马里奥可以变身为多种形态,比如小马里奥(Small Mario)、超级马里奥(Super Mario)、火焰马里奥(Fire Mario)、斗篷马里奥(Cape Mario)等等。在不同的游戏情节下,各个形态会互相转化,并相应的增减积分。比如,初始形态是小马里奥,吃了蘑菇之后就会变成超级马里奥,并且增加 100 积分。实际上,马里奥形态的转变就是一个状态机。其中,马里奥的不同形态就是状态机中的“状态”,游戏情节(比如吃了蘑菇)就是状态机中的“事件”,加减积分就是状态机中的“动作”。比如,吃蘑菇这个事件,会触发状态的转移:从小马里奥转移到超级马里奥,以及触发动作的执行(增加 100 积分)。
今天我们讲解了状态模式。虽然网上有各种状态模式的定义,但是你只要记住状态模式是状态机的一种实现方式即可。状态机又叫有限状态机,它有 3 个部分组成:状态、事件、动作。其中,事件也称为转移条件。事件触发状态的转移及动作的执行。不过,动作不是必须的,也可能只转移状态,不执行任何动作。针对状态机,今天我们总结了三种实现方式。第一种实现方式叫分支逻辑法。利用 if-else 或者 switch-case 分支逻辑,参照状态转移图,将每一个状态转移原模原样地直译成代码。对于简单的状态机来说,这种实现方式最简单、最直接,是首选。第二种实现方式叫查表法。对于状态很多、状态转移比较复杂的状态机来说,查表法比较合适。通过二维数组来表示状态转移图,能极大地提高代码的可读性和可维护性。第三种实现方式叫状态模式。对于状态并不多、状态转移也比较简单,但事件触发执行的动作包含的业务逻辑可能比较复杂的状态机来说,我们首选这种实现方式。
迭代器模式
迭代器模式(Iterator Design Pattern),也叫作游标模式(Cursor Design Pattern)。在开篇中我们讲到,它用来遍历集合对象。这里说的“集合对象”也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如数组、链表、树、图、跳表。迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一。迭代器是用来遍历容器的,所以,一个完整的迭代器模式一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。对于迭代器模式,我画了一张简单的类图,你可以看一看,先有个大致的印象。
迭代器模式,也叫游标模式。它用来遍历集合对象。这里说的“集合对象”,我们也可以叫“容器”“聚合对象”,实际上就是包含一组对象的对象,比如,数组、链表、树、图、跳表。一个完整的迭代器模式,一般会涉及容器和容器迭代器两部分内容。为了达到基于接口而非实现编程的目的,容器又包含容器接口、容器实现类,迭代器又包含迭代器接口、迭代器实现类。容器中需要定义 iterator() 方法,用来创建迭代器。迭代器接口中需要定义 hasNext()、currentItem()、next() 三个最基本的方法。容器对象通过依赖注入传递到迭代器类中。
遍历集合一般有三种方式:for 循环、foreach 循环、迭代器遍历。后两种本质上属于一种,都可以看作迭代器遍历。相对于 for 循环遍历,利用迭代器来遍历有下面三个优势:
- 迭代器模式封装集合内部的复杂数据结构,开发者不需要了解如何遍历,直接使用容器提供的迭代器即可;
- 迭代器模式将集合对象的遍历操作从集合类中拆分出来,放到迭代器类中,让两者的职责更加单一;
- 迭代器模式让添加新的遍历算法更加容易,更符合开闭原则。
除此之外,因为迭代器都实现自相同的接口,在开发中,基于接口而非实现编程,替换迭代器也变得更加容易
访问者模式
带你“发明”访问者模式假设我们从网站上爬取了很多资源文件,它们的格式有三种:PDF、PPT、Word。我们现在要开发一个工具来处理这批资源文件。这个工具的其中一个功能是,把这些资源文件中的文本内容抽取出来放到 txt 文件中。如果让你来实现,你会怎么来做呢?实现这个功能并不难,不同的人有不同的写法,我将其中一种代码实现方式贴在这里。
其中,ResourceFile 是一个抽象类,包含一个抽象函数 extract2txt()。PdfFile、PPTFile、WordFile 都继承 ResourceFile 类,并且重写了 extract2txt() 函数。在 ToolApplication 中,我们可以利用多态特性,根据对象的实际类型,来决定执行哪个方法。
刚刚我带你一步一步还原了访问者模式诞生的思维过程,现在,我们回过头来总结一下,这个模式的原理和代码实现。访问者者模式的英文翻译是 Visitor Design Pattern。
在 GoF 的《设计模式》一书中,它是这么定义的:Allows for one or more operation to be applied to a set of objects at runtime, decoupling the operations from the object structure.翻译成中文就是:允许一个或者多个操作应用到一组对象上,解耦操作和对象本身。
定义比较简单,结合前面的例子不难理解,我就不过多解释了。对于访问者模式的代码实现,实际上,在上面例子中,经过层层重构之后的最终代码,就是标准的访问者模式的实现代码。这里,我又总结了一张类图,贴在了下面,你可以对照着前面的例子代码一块儿来看一下。
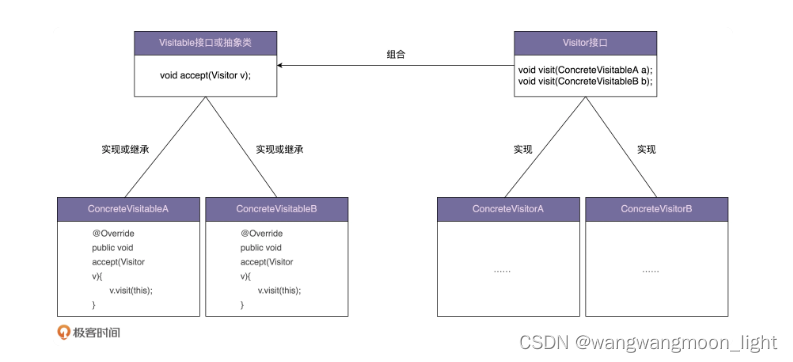
一般来说,访问者模式针对的是一组类型不同的对象(PdfFile、PPTFile、WordFile)。不过,尽管这组对象的类型是不同的,但是,它们继承相同的父类(ResourceFile)或者实现相同的接口。在不同的应用场景下,我们需要对这组对象进行一系列不相关的业务操作(抽取文本、压缩等),但为了避免不断添加功能导致类(PdfFile、PPTFile、WordFile)不断膨胀,职责越来越不单一,以及避免频繁地添加功能导致的频繁代码修改,我们使用访问者模式,将对象与操作解耦,将这些业务操作抽离出来,定义在独立细分的访问者类(Extractor、Compressor)中。
访问者模式允许一个或者多个操作应用到一组对象上,设计意图是解耦操作和对象本身,保持类职责单一、满足开闭原则以及应对代码的复杂性。
对于访问者模式,学习的主要难点在代码实现。而代码实现比较复杂的主要原因是,函数重载在大部分面向对象编程语言中是静态绑定的。也就是说,调用类的哪个重载函数,是在编译期间,由参数的声明类型决定的,而非运行时,根据参数的实际类型决定的。正是因为代码实现难理解,所以,在项目中应用这种模式,会导致代码的可读性比较差。如果你的同事不了解这种设计模式,可能就会读不懂、维护不了你写的代码。所以,除非不得已,不要使用这种模式。课堂讨论
备忘录模式
备忘录模式,也叫快照(Snapshot)模式,英文翻译是 Memento Design Pattern。在 GoF 的《设计模式》一书中,备忘录模式是这么定义的:Captures and externalizes an object’s internal state so that it can be restored later, all without violating encapsulation.翻译成中文就是:在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。在我看来,这个模式的定义主要表达了两部分内容。一部分是,存储副本以便后期恢复。这一部分很好理解。另一部分是,要在不违背封装原则的前提下,进行对象的备份和恢复。这部分不太好理解。
备忘录模式也叫快照模式,具体来说,就是在不违背封装原则的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态,以便之后恢复对象为先前的状态。这个模式的定义表达了两部分内容:一部分是,存储副本以便后期恢复;另一部分是,要在不违背封装原则的前提下,进行对象的备份和恢复。
备忘录模式的应用场景也比较明确和有限,主要是用来防丢失、撤销、恢复等。它跟平时我们常说的“备份”很相似。两者的主要区别在于,备忘录模式更侧重于代码的设计和实现,备份更侧重架构设计或产品设计。对于大对象的备份来说,备份占用的存储空间会比较大,备份和恢复的耗时会比较长。
针对这个问题,不同的业务场景有不同的处理方式。比如,只备份必要的恢复信息,结合最新的数据来恢复;再比如,全量备份和增量备份相结合,低频全量备份,高频增量备份,两者结合来做恢复。
如何优化内存和时间消耗?
前面我们只是简单介绍了备忘录模式的原理和经典实现,现在我们再继续深挖一下。如果要备份的对象数据比较大,备份频率又比较高,那快照占用的内存会比较大,备份和恢复的耗时会比较长。
这个问题该如何解决呢?不同的应用场景下有不同的解决方法。比如,我们前面举的那个例子,应用场景是利用备忘录来实现撤销操作,而且仅仅支持顺序撤销,也就是说,每次操作只能撤销上一次的输入,不能跳过上次输入撤销之前的输入。在具有这样特点的应用场景下,为了节省内存,我们不需要在快照中存储完整的文本,只需要记录少许信息,比如在获取快照当下的文本长度,用这个值结合 InputText 类对象存储的文本来做撤销操作。
我们再举一个例子。假设每当有数据改动,我们都需要生成一个备份,以备之后恢复。如果需要备份的数据很大,这样高频率的备份,不管是对存储(内存或者硬盘)的消耗,还是对时间的消耗,都可能是无法接受的。想要解决这个问题,我们一般会采用“低频率全量备份”和“高频率增量备份”相结合的方法。
全量备份就不用讲了,它跟我们上面的例子类似,就是把所有的数据“拍个快照”保存下来。所谓“增量备份”,指的是记录每次操作或数据变动。当我们需要恢复到某一时间点的备份的时候,如果这一时间点有做全量备份,我们直接拿来恢复就可以了。如果这一时间点没有对应的全量备份,我们就先找到最近的一次全量备份,然后用它来恢复,之后执行此次全量备份跟这一时间点之间的所有增量备份,也就是对应的操作或者数据变动。这样就能减少全量备份的数量和频率,减少对时间、内存的消耗。
命令模式
命令模式的英文翻译是 Command Design Pattern。在 GoF 的《设计模式》一书中,它是这么定义的:The command pattern encapsulates a request as an object, thereby letting us parameterize other objects with different requests, queue or log requests, and support undoable operations.翻译成中文就是下面这样。为了帮助你理解,我对这个翻译稍微做了补充和解释,也一起放在了下面的括号中。命令模式将请求(命令)封装为一个对象,这样可以使用不同的请求参数化其他对象(将不同请求依赖注入到其他对象),并且能够支持请求(命令)的排队执行、记录日志、撤销等(附加控制)功能。
落实到编码实现,命令模式用到最核心的实现手段,就是将函数封装成对象。我们知道,在大部分编程语言中,函数是没法作为参数传递给其他函数的,也没法赋值给变量。借助命令模式,我们将函数封装成对象,这样就可以实现把函数像对象一样使用。命令模式的主要作用和应用场景,是用来控制命令的执行,比如,异步、延迟、排队执行命令、撤销重做命令、存储命令、给命令记录日志等等,这才是命令模式能发挥独一无二作用的地方。
解释器模式
解释器模式的英文翻译是 Interpreter Design Pattern。在 GoF 的《设计模式》一书中,它是这样定义的:Interpreter pattern is used to defines a grammatical representation for a language and provides an interpreter to deal with this grammar.翻译成中文就是:解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。
接下来,我们再来看一个更加接近实战的例子,也就是咱们今天标题中的问题:如何实现一个自定义接口告警规则功能?在我们平时的项目开发中,监控系统非常重要,它可以时刻监控业务系统的运行情况,及时将异常报告给开发者。比如,如果每分钟接口出错数超过 100,监控系统就通过短信、微信、邮件等方式发送告警给开发者。一般来讲,监控系统支持开发者自定义告警规则,比如我们可以用下面这样一个表达式,来表示一个告警规则,它表达的意思是:每分钟 API 总出错数超过 100 或者每分钟 API 总调用数超过 10000 就触发告警。
api_error_per_minute > 100 || api_count_per_minute > 10000
解释器模式为某个语言定义它的语法(或者叫文法)表示,并定义一个解释器用来处理这个语法。实际上,这里的“语言”不仅仅指我们平时说的中、英、日、法等各种语言。
从广义上来讲,只要是能承载信息的载体,我们都可以称之为“语言”,比如,古代的结绳记事、盲文、哑语、摩斯密码等。要想了解“语言”要表达的信息,我们就必须定义相应的语法规则。
这样,书写者就可以根据语法规则来书写“句子”(专业点的叫法应该是“表达式”),阅读者根据语法规则来阅读“句子”,这样才能做到信息的正确传递。而我们要讲的解释器模式,其实就是用来实现根据语法规则解读“句子”的解释器。
解释器模式的代码实现比较灵活,没有固定的模板。我们前面说过,应用设计模式主要是应对代码的复杂性,解释器模式也不例外。它的代码实现的核心思想,就是将语法解析的工作拆分到各个小类中,以此来避免大而全的解析类。一般的做法是,将语法规则拆分一些小的独立的单元,然后对每个单元进行解析,最终合并为对整个语法规则的解析。
中介模式
中介模式的原理和实现中介模式的英文翻译是 Mediator Design Pattern。在 GoF 中的《设计模式》一书中,它是这样定义的:Mediator pattern defines a separate (mediator) object that encapsulates the interaction between a set of objects and the objects delegate their interaction to a mediator object instead of interacting with each other directly.翻译成中文就是:中介模式定义了一个单独的(中介)对象,来封装一组对象之间的交互。将这组对象之间的交互委派给与中介对象交互,来避免对象之间的直接交互。
这里我画了一张对象交互关系的对比图。其中,右边的交互图是利用中介模式对左边交互关系优化之后的结果,从图中我们可以很直观地看出,右边的交互关系更加清晰、简洁。
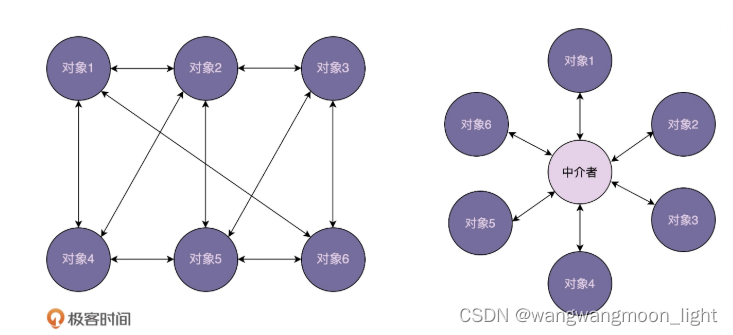
为了让飞机在飞行的时候互不干扰,每架飞机都需要知道其他飞机每时每刻的位置,这就需要时刻跟其他飞机通信。飞机通信形成的通信网络就会无比复杂。这个时候,我们通过引入“塔台”这样一个中介,让每架飞机只跟塔台来通信,发送自己的位置给塔台,由塔台来负责每架飞机的航线调度。这样就大大简化了通信网络。
中介模式 VS 观察者模式
前面讲观察者模式的时候,我们讲到,观察者模式有多种实现方式。虽然经典的实现方式没法彻底解耦观察者和被观察者,观察者需要注册到被观察者中,被观察者状态更新需要调用观察者的 update() 方法。但是,在跨进程的实现方式中,我们可以利用消息队列实现彻底解耦,观察者和被观察者都只需要跟消息队列交互,观察者完全不知道被观察者的存在,被观察者也完全不知道观察者的存在。我们前面提到,中介模式也是为了解耦对象之间的交互,所有的参与者都只与中介进行交互。而观察者模式中的消息队列,就有点类似中介模式中的“中介”,观察者模式的中观察者和被观察者,就有点类似中介模式中的“参与者”。那问题来了:中介模式和观察者模式的区别在哪里呢?什么时候选择使用中介模式?什么时候选择使用观察者模式呢?在观察者模式中,尽管一个参与者既可以是观察者,同时也可以是被观察者,但是,大部分情况下,交互关系往往都是单向的,一个参与者要么是观察者,要么是被观察者,不会兼具两种身份。也就是说,在观察者模式的应用场景中,参与者之间的交互关系比较有条理。而中介模式正好相反。只有当参与者之间的交互关系错综复杂,维护成本很高的时候,我们才考虑使用中介模式。毕竟,中介模式的应用会带来一定的副作用,前面也讲到,它有可能会产生大而复杂的上帝类。除此之外,如果一个参与者状态的改变,其他参与者执行的操作有一定先后顺序的要求,这个时候,中介模式就可以利用中介类,通过先后调用不同参与者的方法,来实现顺序的控制,而观察者模式是无法实现这样的顺序要求的。
解释器模式C语言
解释器
背景
解释器模式(Interpreter Pattern)提供了评估语言的语法或表达式的方式,它属于行为型模式。这种模式实现了一个表达式接口,该接口解释一个特定的上下文。
名词释义
解释器,其实就像正则表达式、SQL语言等一样,把一种特定的语言格式转换成另一个种语言格式。
C语言应用
此模式更多应该吸收它的思维,个人最常用的就是把常用的逻辑语言进行变量提取,并转换成固定的逻辑格式。
例子
现在来设计一个触摸显示屏的后台定时器功能,这个后台定时器需要实现一个功能,就是用户可以添加任意多个定时器,可以设定定时时间,定时触发条件,停止条件及执行动作。举个例子,用户可以设定当按下某个按键时,启动定时,定时每3s执行一次数据A加1的操作,当放开按键时,停止执行。
先来看下普通的实现。
#include <stdint.h>
extern uint8_t KeySta;
uint8_t Cnt = 0;
/* 中断里调用,1s调用一次 */
void TmrTick(void)
{
Cnt++;
if (Cnt > 200) {
Cnt = 200;
}
}
/* 用户操作 */
void UserFunc(void)
{
A += 1;
}
int main(void)
{
if (1 == KeySta) {
if (Cnt >= 3) {
UserFunc();
Cnt = 0;
}
} else {
Cnt = 0;
}
}
如果这时再加一个操作呢,比如用户要求按下按键2,定时每2s执行一次A-1的操作,放开按键2时停止执行。
#include <stdint.h>
extern uint8_t KeySta[2];
uint8_t Cnt[2] = 0;
/* 中断里调用,1s调用一次 */
void TmrTick(void)
{
Cnt[0]++;
if (Cnt[0] > 200) {
Cnt[0] = 200;
}
Cnt[1]++;
if (Cnt[1] > 200) {
Cnt[1] = 200;
}
}
/* 用户操作 */
void UserFunc1(void)
{
A += 1;
}
void UserFunc2(void)
{
A -= 1;
}
int main(void)
{
/* 按键1的动作需求 */
if (1 == KeySta[0]) {
if (Cnt[0] >= 3) {
UserFunc1();
Cnt[0] = 0;
}
} else {
Cnt[0] = 0;
}
/* 按键2的动作需求 */
if (1 == KeySta[1]) {
if (Cnt[1] >= 2) {
UserFunc2();
Cnt[1] = 0;
}
} else {
Cnt[1] = 0;
}
}
如果用户再继续增加类似的按键功能,虽然每次复制代码就可以实现,但改动的地方还是很多,容易出现错误。这里我们来找找规律,上面增加的两个操作中,有哪些是不一样的?不难看出,这里触发条件、解除条件不同,定时的时间不同,执行动作也不同,但其逻辑层面上,是相同的,那我们就可以把相同的逻辑关系抽象出来固化封装。
#include <stdint.h>
/* 解释器的实现 */
void Interpreter(uint8_t tri_cond,
uint8_t time,
void (*func)(void *),
void *pt,
uint8_t *tmr_cnt)
{
if (tri_cond) {
if (*tmr_cnt >= time) {
*tmr_cnt = 0;
func(pt);
}
} else {
*tmr_cnt = 0;
}
}
extern uint8_t KeySta[2];
uint8_t Cnt[2] = 0;
/* 中断里调用,1s调用一次 */
void TmrTick(void)
{
for (uint8_t i = 0; i < 2; i++)
{
Cnt[i]++;
if (Cnt[i] > 200) {
Cnt[i] = 200;
}
}
}
/* 用户操作 */
void UserFunc1(void *pt)
{
A += 1;
}
void UserFunc2(void *pt)
{
A -= 1;
}
int main(void)
{
Interpreter((1 == KeySta[0]),
3,
UserFunc1,
NULL,
&Cnt[0]);
Interpreter((1 == KeySta[1]),
2,
UserFunc2,
NULL,
&Cnt[1]);
return 0;
}
解释器一般可以跟表驱动很好的贴合使用,再加上表驱动,来看下上面代码的实现。
#include <stdint.h>
/* 解释器传参封装 */
struct tagInterpreterPara
{
uint8_t TriCond;
uint8_t Time;
void (*Func)(void *);
void *Pt;
uint8_t TmrCnt;
};
/* 解释器的实现 */
void Interpreter(struct tagInterpreterPara *table)
{
if (table->TriCond) {
if (table->TmrCnt >= table->Time) {
table->TmrCnt = 0;
table->func(table->pt);
}
} else {
table->TmrCnt = 0;
}
}
/********************************后续变更需要更改的地方*********************************/
extern uint8_t KeySta[2];
/* 用户操作 */
void UserFunc1(void *pt)
{
A += 1;
}
void UserFunc2(void *pt)
{
A -= 1;
}
/* 表 */
struct tagInterpreterPara UserTable[] =
{
{KeySta[0], 3, UserFunc1, NULL, 0},
{KeySta[1], 2, UserFunc2, NULL, 0},
};
/***************************************************************************************/
/* 中断里调用,1s调用一次 */
void TmrTick(void)
{
for (uint8_t i = 0; i < sizeof(UserTable)/sizeof(UserTable[0]); i++)
{
UserTable[i].TmrCnt++;
if (UserTable[i].TmrCnt > 200) {
UserTable[i].TmrCnt = 200;
}
}
}
int main(void)
{
for (uint8_t i = 0; i < sizeof(UserTable)/sizeof(UserTable[0]); i++) {
Interpreter(&UserTable[i]);
}
return 0;
}
适用范围
对于有固定行为模式,并且同样的行为有大量重复出现的场景下可以使用。
优势
对于有特定行为模式的语句,可以最大程度地减少重复性动作的编写。
劣势
行为模式完全固化,当需要有新的行为变化时,无法扩展。
转换后的语言可能跟原本的通用语言存在冲突,容易造成应用混乱。
命令模式
背景
命令模式(Command Pattern)是一种数据驱动的设计模式,它属于行为型模式。请求以命令的形式包裹在对象中,并传给调用对象。调用对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执行命令。
名词释义
将实际含义功能映射为命令功能码进行表示,就像007只是一个间谍代号,而不是直接以名字进行区分。这样做的好处是可以统一编号管理。
例子
假如现在要做一个设置串口参数的接口,应该怎么做?先来看下最常修改的串口配置,是波特率吧。所以我们先来实现一个串口波特率的修改。
void Uart_Config(uint32_t baud)
{
/* 修改波特率 */
Uart_SetBaud(baud);
}
后来发现,大部分串口调试助手上面,对串口的设置,基本都有4个,就是波特率,数据位,校验位,停止位。于是我们来修改下设置接口。
void Uart_Config(uint32_t baud,
uint8_t data_bits,
uint8_t parity,
uint8_t stop_bits)
{
/* 修改波特率 */
Uart_SetBaud(baud);
/* 修改数据位 */
Uart_SetDataBits(data_bits);
/* 修改校验位 */
Uart_SetParity(parity);
/* 修改停止位 */
Uart_SetStopBits(stop_bits);
}
但有没有发现,上面这种实现方式,接口变了,函数传参数变了,也就意味着上层调用这个接口的地方也需要变更。而且这里还有一个问题,就是当我只需要修改波特率时,实际确对数据位、校验位和停止位也进行了操作。为了解决上面两个问题,这里引入命令模式,接口只传两个参数,一个是命令类型,一个是设置的数值,函数内根据当前的命令类型来区分数值的作用。
/* 串口命令类型 */
enum emUartCmdType
{
UARTCMD_TYPE_set_baud = 0,
UARTCMD_TYPE_set_data_bits = 1,
UARTCMD_TYPE_set_parity = 2,
UARTCMD_TYPE_set_stop_bits = 3,
};
void Uart_ConfigCommand(uint32_t cmd,
uint32_t set_para)
{
switch (cmd)
{
case UARTCMD_TYPE_baud:
{
/* 修改波特率 */
Uart_SetBaud(set_para);
break;
}
case UARTCMD_TYPE_data_bits:
{
/* 修改数据位 */
Uart_SetDataBits(set_para);
break;
}
case UARTCMD_TYPE_parity:
{
/* 修改校验位 */
Uart_SetParity(set_para);
break;
}
case UARTCMD_TYPE_stop_bits:
{
/* 修改停止位 */
Uart_SetStopBits(set_para);
break;
}
}
}
上面的实现有没有看到熟悉的优化方式,没错,我们的表驱动又可以派上用场了。下面稍微使用表驱动优化亿点点。
/* 串口命令类型 */
enum emUartCmdType
{
UARTCMD_TYPE_set_baud = 0,
UARTCMD_TYPE_set_data_bits = 1,
UARTCMD_TYPE_set_parity = 2,
UARTCMD_TYPE_set_stop_bits = 3,
};
/* 增加表驱动结构,命令对应操作 */
struct tagUartCmdFunc
{
uint32_t Cmd;
void (*Func)(uint32_t);
};
/* 映射表 */
struct tagUartCmdFunc UartCmdTable[] =
{
{UARTCMD_TYPE_set_baud, Uart_SetBaud},
{UARTCMD_TYPE_set_data_bits, Uart_SetDataBits},
{UARTCMD_TYPE_set_parity, Uart_SetParity},
{UARTCMD_TYPE_set_stop_bits, Uart_SetStopBits},
};
void Uart_ConfigCommand(uint32_t cmd,
uint32_t set_para)
{
for (uint32_t i = 0; i < sizeof(UartCmdTable) / sizeof(UartCmdTable[0]); i++)
{
(UartCmdTable[i].Cmd == cmd)?(UartCmdTable[i].Func(set_para)):(0);
}
}
适用范围
对于函数参数个数会有扩展且相互独立的时候,可以使用命令模式,以增强其扩展方式。
优势
命令易于扩展,不需要修改接口。
当命令之间不冲突时,可以实现继承的效果。
劣势
需要维护一套命令码,命令与实际含义之间没有必然联系,代码不直观。
责任链、观察者模式
一、背景
责任链模式(Chain of Responsibility Pattern)为请求创建了一个接收者对象的链。这种模式给予请求的类型,对请求的发送者和接收者进行解耦。这种类型的设计模式属于行为型模式。
观察者模式(Observer Pattern),则是当一个对象被修改时,则会自动通知依赖它的对象。观察者模式属于行为型模式。
为什么把这两种模式放一起?是因为这两者在C语言里的实现比较接近,责任链是在接收到请求时,分别给接收对象进行处理,当处理的请求不是自身接收对象的请求时(或者是自身的责任范围内的请求,具体视责任链的定义来决定),则传递给下一个接收对象。所以对于责任链来说,只有在职责范围内的请求才会执行。而观察者模式,则是不管职责范围,全体都会执行。所以观察者模式可以看作是责任链的一种特殊情况(即所有条件均满足的情况)。
二、名词释义
既然提到链,那这里肯定会涉及链表,所以这里其实是两部分的内容,一个是责任的划分,一个是链表的表示。而对于观察者,则是少了一个责任划分的条件而已。
三、C语言例子
责任链
比如现在要做一个手机转账的功能,需求是当转账金额不大于100时,直接转,不需要任何提示;当转账金额大于100时,提示确认信息;当转账金额大于1000时,需要密码确认;当转账金额大于10000时,需要手机短信验证码确认。比如当转账金额为20000时,需要提示信息,并且密码确认,并且还需要手机短信验证。
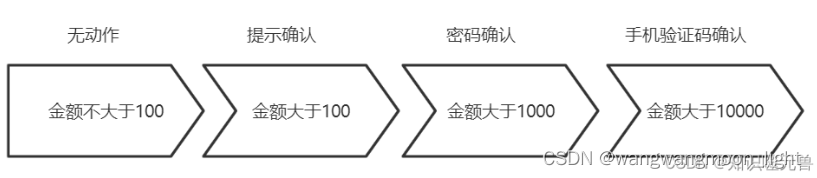
/* 无动作 */
extern void DoNothing(void);
/* 提示 */
extern void Tips(void);
/* 密码确认 */
extern void PswConfig(void);
/* 验证码确认 */
extern void CodeConfig(void);
void TransferFunc(uint32_t value)
{
if (value >= 10000) {
CodeConfig();
} else if (value >= 1000) {
PswConfig();
} else if (value >= 100) {
Tips();
} else {
DoNothing();
}
}
上面这种实现其实没什么问题,但如果后面要加个操作,比如金额大于10w时,需要本人视频核对。那这个时候就需要去改动TransferFunc这个函数主体内容,一不小心可能还会把原本那些金额的处理给变更成其他操作。为了让执行逻辑与变更对象解耦开,这里使用责任链的方式。
/* 定义责任链的结构 */
struct tagTransfer
{
uint32_t Value;
void (*Func)(void);
struct tagTransfer *Next;
};
/* 无动作 */
extern void DoNothing(void);
/* 提示 */
extern void Tips(void);
/* 密码确认 */
extern void PswConfig(void);
/* 验证码确认 */
extern void CodeConfig(void);
/* 定义链头 */
struct tagTransfer *Head = NULL;
void TransferAddList(uint32_t value, void (*func)(void))
{
struct tagTransfer *last = Head;
struct tagTransfer *next = malloc(sizeof(struct tagTransfer));
if (NULL != next)
{
next->value = value;
next->func = func;
/* 按责任等级排个序 */
if (NULL == last) {
last = next;
} else {
for (;NULL != last->next; last = last->next) {
/* 按从大到小排序 */
if (value > last->next->value) {
next->next = last->next;
last->next = next;
return ;
}
}
last->next = next;
}
}
}
/* 责任链执行判断 */
void TransferFunc(uint32_t value)
{
struct tagTransfer *last = Head;
for (;NULL != last; last = last->next)
{
if (value > last->value) {
last->func();
} else {
break;
}
}
}
但对于嵌入式端,没必要使用动态链接的形式增减责任链内容,这里有另一种更适用于嵌入式的静态链接,没错,就是我们的老朋友表驱动。下面用表驱动的例程来展示下。
/* 定义责任链的结构 */
struct tagTransfer
{
uint32_t Value;
void (*Func)(void);
};
/* 无动作 */
extern void DoNothing(void);
/* 提示 */
extern void Tips(void);
/* 密码确认 */
extern void PswConfig(void);
/* 验证码确认 */
extern void CodeConfig(void);
/* 做好责任划分的静态定义 */
static const struct tagTransfer FuncTable[] =
{
{0, DoNothing},
{100, Tips},
{1000, PswConfig},
{10000, CodeConfig},
};
/* 责任链执行判断 */
void TransferFunc(uint32_t value)
{
for (uint8_t i = 0; i < sizeof(FuncTable) / sizeof(FuncTable[0]); i++)
{
if (value >= FuncTable[i].Value)
{
FuncTable[i].Func();
}
}
}
观察者模式
对于观察者模式,可以使用同样的结构,只是使用的场景不大一样,一般需要订阅、通知的场景,就像公众号,只要订阅了公众号,当公众号有新的推文时,会直接通知到所有订阅这个公众号的人。当前技术中,有使用这种方式的,比较典型的,就是MQTT协议。
这里我们也来做个小例子,比如现在有个触摸屏,当点击屏幕的按键时,需要显示按键被按下的状态,另外还需要响一下蜂鸣器。那我们先用常规思路处理一下。
/* 按键状态 */
enum emKeyState
{
KEY_STA_bounce = 0, /* 按键弹起 */
KEY_STA_press = 1, /* 按键按下 */
};
extern uint8_t KeySta = KEY_STA_bounce;
/* 蜂鸣器动作 */
extern void BuzzerFunc(void);
/* 显示屏刷新 */
extern void DisplayFunc(void);
void main(void)
{
while(1) {
/* 按键按下时动作 */
if (KEY_STA_press == KeySta) {
/* 蜂鸣器响 */
BuzzerFunc();
/* 界面刷新 */
DisplayFunc();
}
}
}
如果这时候需要再执行一个点亮LED的动作,那就需要找到按键按下这个判断条件,增加一个点亮LED的动作。
/* 按键状态 */
enum emKeyState
{
KEY_STA_bounce = 0, /* 按键弹起 */
KEY_STA_press = 1, /* 按键按下 */
};
extern uint8_t KeySta = KEY_STA_bounce;
/* 蜂鸣器动作 */
extern void BuzzerFunc(void);
/* 显示屏刷新 */
extern void DisplayFunc(void);
/* 点亮LED灯 */
extern void LEDFunc(void);
void main(void)
{
while(1) {
/* 按键按下时动作 */
if (KEY_STA_press == KeySta) {
/* 蜂鸣器响 */
BuzzerFunc();
/* 界面刷新 */
DisplayFunc();
/* 点亮LED灯 */
LEDFunc();
}
}
}
上面这种写法有问题么?实现起来没问题,也添加功能也很方便,但是有个问题,就是如果现在想把按键的功能封装起来放一个模块里,这时候按键触发的执行动作应该怎么处理?总不能把功能也封装进去,那以后每加一个功能就得改一次模块。所以这里就要用到观察者模式了。
这里的按键按下,可以看作是一个事件,当触发这个事件时,需要执行蜂鸣器响、界面刷新、点亮LED灯等操作。其实就是当发生了按键按下的事件时,需要同步通知蜂鸣器、界面和LED同步动作。这个模式在嵌入式里其实就是一个回调函数的应用。下面我们来看下怎么实现。
/*************************按键模块的实现.c****************************/
/* 按键状态 */
enum emKeyState
{
KEY_STA_bounce = 0, /* 按键弹起 */
KEY_STA_press = 1, /* 按键按下 */
};
/* 观察者链表结构 */
struct tagKeyFunc
{
void (*Func)(void);
struct tagKeyFunc *Next;
};
struct tagKeyFunc *Last = NULL;
uint8_t KeySta = KEY_STA_bounce;
/* 回调函数注册 */
void KeyPress_AddFunc(void(*func)(void))
{
struct tagKeyFunc *next = malloc(sizeof(struct tagKeyFunc));
next->Func = func;
next->Next = Last;
Last = next;
}
/* 事件触发时执行注册的回调函数 */
void KeyEventFunc(void)
{
struct tagKeyFunc *cur = Last;
/* 按键按下时,执行所有注册的功能 */
if (KEY_STA_press == KeySta)
{
for (; NULL != cur; cur = cur->Next)
{
cur->Func();
}
}
}
/********************************************************************/
/***************************应用.c*********************************/
extern void KeyPress_AddFunc(void(*func)(void));
extern void KeyEventFunc(void);
/* 蜂鸣器动作 */
extern void BuzzerFunc(void);
/* 显示屏刷新 */
extern void DisplayFunc(void);
/* 点亮LED灯 */
extern void LEDFunc(void);
void main(void)
{
/* 按键触发功能注册 */
KeyPress_AddFunc(BuzzerFunc);
KeyPress_AddFunc(DisplayFunc);
KeyPress_AddFunc(LEDFunc);
while(1)
{
KeyEventFunc();
}
}
/********************************************************************/
四、适用范围
责任链,适用于不同操作对象各自有明确的职责划分。
观察者,适用于需要遍历通知的场景。
五、优劣势
优势
两者都有一个比较明显的优势,就是把触发事件和执行功能两者解耦开。
如果使用链式结构,可以很方便地进行动态添加和删除。
劣势
功能执行的位置比较有局限性,不灵活,比如上面例子,所有功能只能在按键按下时才能执行,如果需要在弹起时执行则不能实现,需要另外增加一个弹起执行的回调,也就是功能执行的位置完全取决于事件开放的位置。
使用回调时,不容易发现无限递归的情况,即使用时有A回调B,B回调A这种无限调用的风险。















 308
308











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









