







特征对于算法模型好比做饭的米,是基石。如何选取好的米,pandas就是你在挑选米的品质时的一个强大工具。本文将主要从pandas的工具安装 、基本概念、读取数据、选择性查看数据Series与DataFrame、查看统计信息、筛选数据、groupby操作、value_counts统计、其他工作中已需要用过的记录(如matplot进行画图展示、将数据写入到Excel中)等来展开。
目录
将DataFrame的行去重 .drop_duplicates()
# 将某列的值转换成python list数据结构
pandas的安装
读取数据
1 pandas的安装
pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple --user上面为一种安装方式,-i 后面的镜像源是能大大加快安装包下载速度。
2 基本概念:
pandas中有两大数据结构中:Series和DataFrame、
Series的定义:Series是一种类似于一维数组的对象,它由一组数据(各种NumPy数据类型)以及一组与之相关的数据标签(即索引)组成。
DataFrame可以看成是一种表格型数据结构,由行与列组成,每列可以是不同类型的值。可以通过读取数据来创建,当然也可以通过字典来创建(本文忽略)。
3 读取数据
pd.read_csv(...)
读取的数据对象为HiveSQL select选择出来的数据,用text(或者sublime或者notepad++)去打开是以空格分割的。
实例
import pandas as pddata=pd.read_csv('../data/dt_20200807/10line_of_part-00000',sep='\t',header=None)data.columns=character_list #将各个属性名字组成的list赋值给columns
上面含义是:以pandas去读取dt_20200807/目录下的10line_of_part-00000数据文件,数据的分割符为空格\t。返回一个名为data的DataFrame。
如果是想要加载dt_20200807目录下的所有文件加载到一个DataFrame中则可以利用pd的concat命令去合并。
实例代码为:
# 文件路径。其中的含义是,数据的目录在于当前代码文件的父目录同级的data/dt下。file_dir="../data/dt=20200807"# 读取其中的各个文件并加载到一个list中all_file_list=os.listdir(file_dir)#遍历着去解析每个文件for single_file in all_file_list:#逐个读取每个文件single_data_frame=pd.read_csv(os.path.join(file_dir,single_file),sep='\t',header=None)#只要单个文件的情况if single_file ==all_file_list[0]:all_data_frame=single_data_frameelse:#有多个数据文件的情况all_data_frame=pd.concat([all_data_frame,single_data_frame],ignore_index=True)all_data_frame.columns=character_list
此外,pandas读与写excel数据文件,可以用pd.read_excel() 和DataFrame.to_excel() 。
创建DataFrame 与赋值
创建一个新的DataFrame(单独拉出部分属性进行分析是常用)。pd.DataFrame(columns=['a', 'b']) 和直接从原DataFrame选部分属性与数据。
# 方式1 :新建一个属性名为interval_sum和ratio的DataFrame new_dfnew_df= pd.DataFrame(columns=['interval_sum', 'ratio'])#增加一行数据,以字符串的format形式赋值自定义索引(自定义index_res)new_df='between_{}_and_{}'.format(start,end) #以format的str形式传参进去,很好区分res_interval_sum_time_range_num_ratio_df.loc[index_res]={"interval_sum":counts_interval_sum_time_start_end,"ratio":ratio_interval_sum_time_start_end}#上面含义是给new_df的一行赋值,并自定义了索引。在进行汇总式数据显示时结果就比较直观展示值的其含义# 方式2 : 从原来的DataFrame中拉取部分属性的值单独来分析time_broadrate_data=all_data_frame.ix[:,['1030252_f_b_duration_info', 'broad_rate']]# 上面含义是将duration_info与broad_rate 的信息单独拉出来做分析,# 方式3 复制一个新的,用作备份(用jupyternotebook分析时,常会对数据进行变换,容易出错,备份一个,就不用重新加载数据了)data_back=all_data_frame.copy()
4 查看属性的值
查看行列,可以用dataframe.ix[ ...]去查看,其中第一个参数为行值,如果取值为:则默认所有行,如果读取指定的某几行,则传入一个局部[] ,对于第二个参数列值,同理类推。行与列的之间的分隔用逗号。返回值类型为一个dataframe或series或某个具体的值。
data=pd.read_csv('./100line_of_table_mds_feature_project_sample_data_v2_test',delimiter="\t")#pandas使用简记#获取所有行所有列print(data.ix[:, :])#获取第2/4/6行的数据print(data.ix[[1,3,5],:])#读取username列所有行的数据print(data.ix[:, 'username'])# 读取所有行,列名为username、verified_type、comment的数据print(data.ix[:, ['username','verified_type','comment']])# 读取第1、3、5行,列名为username、verified_type、comment的数据print(data.ix[[1,3,5], ['username','verified_type','comment']])
其他获取值的方式
.loc 的使用
.loc[],中括号里面是先行后列,以逗号分割,行和列分别是行的标签值和列标签值。
.iloc[]与loc一样,中括号里面也是先行后列,行列标签用逗号分割,与loc不同的之处是,.iloc 是根据行数与列数来索引的。如
data = pd.DataFrame({'A':[1,2,3],'B':[4,5,6],'C':[7,8,9]},index=["a","b","c"])# 注意上面末尾的index值是赋给的行标签值data.loc["b","B"]# 上面获取的值为 5data.iloc[1,1]# 用iloc来表示,注意索引从0开始returned_iloc=data.iloc[1:3,1:3]print("type of returned_iloc: {} \t and value is {}".format(type(returned_iloc),returned_iloc))# 上面返回 <class 'pandas.core.frame.DataFrame'> ,
5 筛选数据
DataFrame筛选出自己想要的数据,可以直接通过列出条件表达式去筛选。基本格式如下:
自己的DataFrame名[条件表达式]
如
获取列A中值比1大的行记录
print(data[data['A']>1])还可以使用 &(并)与| (或)实现多条件筛选
# 找出列A的值大于1 且列B的值小于6的内容print(data[(data['A']>1) & (data['B']<6)])
注意上面,两个筛选条件都用()括起来了。否则会报不能识别的ambiguous的错误。
输出:
A B C
b 2 5 8
6 group by 操作
按某些属性的不同值进行分组统计。分析中常会有这样的需求,比如 查看数据中男女的统计分布差异情况
df.groupby('gender').describe()
groupby 主要是对数据对象主要有三类操作
将数据拆分成组
-
df.groupby(‘key’)
-
df.groupby([‘key1’,’key2’])
-
df.groupby(key,axis=1)
返回一个groupby对象。
数据准备
import pandas as pddf = pd.DataFrame({'gender': ['1', '0', '1', '2', '0', '1'],'B': [21, 8, 3, 4, 3, 2],'C': [32, 18, 17, 14, 15, 87]})print(df)
数据:

对于第一种情况:
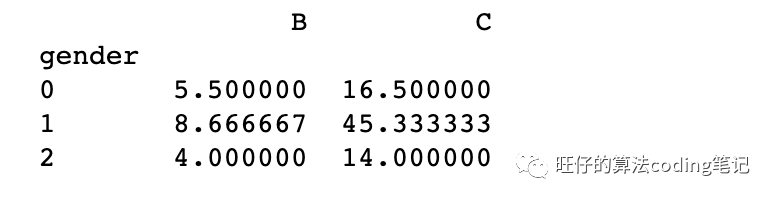
# df.groupby(‘key’)# 按A列分组(groupby),获取其他列的均值print(df.groupby('gender').mean())
输出:
第二种情况 按多列分组
# df.groupby([‘key1’,’key2’])#按多列进行分组(groupby)df.groupby(['gender','B']).mean()
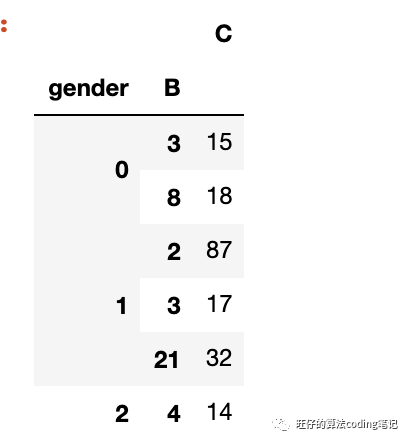
从上面两个实例可以看出,groupby主要是对数据对象进行"拆分-处理-合并"的过程。第一个阶段,即根据提供的一个或多个key将数据拆分为多组。然后将函数(如mean)应用到各个分组去计算得到新值,最后即将各组的执行结果合并到最终的结果对象中输出。
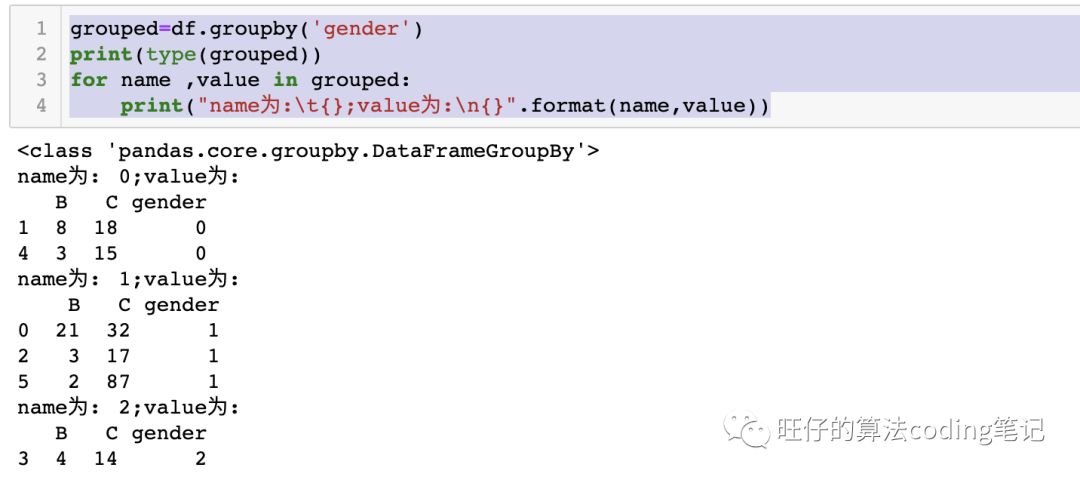
遍历分组,自定义处理
对于groupby得到的对象也可以,以遍历的方式去对得到的值进行单独处理。
grouped=df.groupby('gender')print(type(grouped))for name ,value in grouped:print("name为:\t{};value为:\n{}".format(name,value))# 在此出可以自定义需要进行的处理
也可以直接应用聚合函数agg进行操作,返回得到一个DataFrame
import numpy as npgrouped=df.groupby('gender')agged_func=grouped['B'].agg([np.sum, np.mean, np.std])print(type(agged_func))print(agged_func)

针对不同的列应用多种不同的统计方法agg:
df.groupby('gender').agg({'B':[np.mean, 'sum'], 'C':['count',np.std]})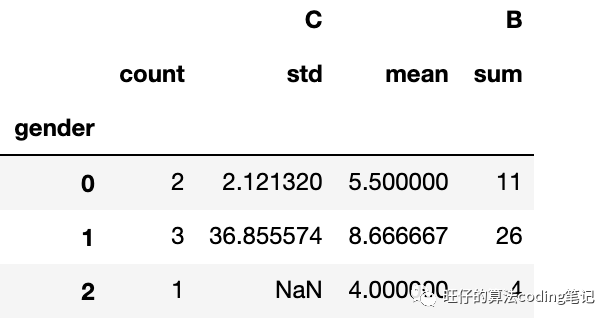
过滤filter()
import numpy as npfilter_data=df.groupby('gender').filter(lambda x : len(x)>2) # 性别中出现次数超过2此的print(filter_data)

对于groupby后返回groupby对象,常用的统计函数还有:
DataFrameGroupBy.quantile() #返回给定分位数的值gender_time_quantile=groupbyed_all_data_frame['1030252_info'].quantile([0,0.05,0.20,0.25,0.30,0.80,0.85,0.9,0.95])DataFrameGroupBy.describe() #生成描述性统计数据
7 value_counts
统计属性各个值出现的次数,返回一个Series。这个可以在工作中可以用于去查看填充的缺失值(如0)的个数,以及其他数据的次数情况。对于选取特征很好用,还可以看到各个值出现的分布情况(导出结果用excel做个图或者调用matplotlib)。
df['gender'].value_counts()
pandas查看统计信息
# 查看描述统计df['C'].describe()
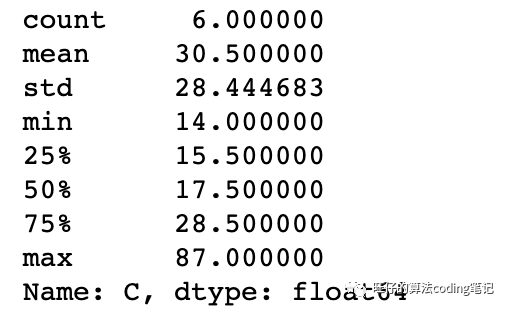
# 查看分位数情况df['C'].quantile([0.1,0.25,0.5,0.75])# 查看最小的两个值df['C'].nsmallest(2)df['C'].nlargest(2)
其他相关操作:
数据类型强转 .astype('data_type')
all_data_frame['time']=all_data_frame['time'].astype('float')# time列的数值类型转换为了float型
保留指定位小数 .round(decimals=2)
all_data_frame['broad_rate']=all_data_frame['broad_rate'].round(decimals=2)# 注意与python的直接用round不同ratio_bigger_25=round(float(count_bigger_25)/float(data_total),2)
将DataFrame的行去重 .drop_duplicates()
uuid_time_uni=uuid_time.drop_duplicates()按某个列的值进行排序
df.sort_index(by=[]) 或sort_values(by=[])by参数可以指定根据哪一列数据进行排序,其中参数 ascending是设置升序和降序(选择多列或者多行排序要加[ ])
time_vc_sort=_time_vc.sort_index(by=['time_length'],ascending=True)# 按照time_length的值进行升序排序,返回得到一个新的DataFrame time_vc_sort
对某列的数据进行累计求和 .cumsum()
# 计算不同完播率值的对应ratio占比的累计和 cumsum_ratiobroad_vc_sort['cumsum_ratio']=broad_vc_sort['in_interval_ratio'].cumsum()
# 将某列的值转换成python list数据结构
df = pd.DataFrame({'a':[1,3,5,5], 'b':[3,5,6,2]})# 方法1df['a'].values.tolist()# 方法2df['a'].tolist()
Pandas 中直接做图
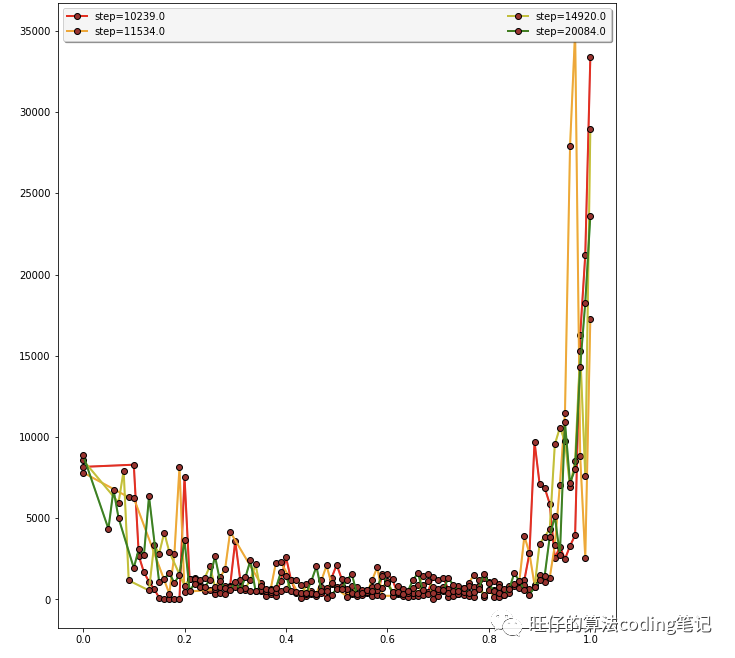
简单的数据分析与做图可以借助matplotlib.pyplot 直接将pandas数据结构中的里的数据画成图。直接plt.plot(横坐标值,列坐标值,其他参数)即可。同样可以进行图例设置。
# 设置图的大小plt.figure(figsize=(10, 11.5)) #第一个参数为横坐标长度,第二个为纵坐标多个值画到同一张图里,将各个”y”在一个for里循环打印即可,横坐标为同一个# 设置图的大小plt.figure(figsize=(10, 11.5))# list_step_broad_dfcolor_s = ['red', 'orange', 'y', 'green', 'cyan', 'blue', 'purple','pink','grey'] # 红橙黄(浅黄)绿青蓝紫 粉色 灰色count=0 # 用于记录区分颜色## 看各个完播率的占比图 # 前4个画到一起多个值画到同一张图里,将各个”y”在一个for里循环打印即可,横坐标值只要保持一致即可for step in time_step_value: # 按time_step_value 里的值去遍历画图#list_step_broad_df 是一个元素为DataFrame的listtemp_step_broad=list_step_broad_df[step]# 下面将list_step_broad_df 各个DataFrame的指定列值画到同一张图中if int(step) <=4: #画图只画前7个区间(2.5,7.5,12.5,17.5,22.5,27.5,32.5)# 图上看分布plt.plot(temp_step_broad.broad_rate, # 横坐标视频时长temp_step_broad.in_interval_ratio,# 纵坐标视频量的值linestyle = '-', # 折线类型linewidth = 2, # 折线宽度color = color_s[count], # 折线颜色marker = 'o', # 点的形状markersize = 6, # 点的大小markeredgecolor='black', # 点的边框色markerfacecolor='brown',label="step={}".format(step*INTERVAL))## 设置图例leg = plt.legend(loc='upper left', ncol=2, mode="expand", shadow=True, fancybox=True)leg.get_frame().set_alpha(0.9)else:continue
pandas 读写 Excel
import pandas as pd# 将excel加载读进来,发挥一个dataframedf1 = pd.read_excel(file_name, sheet_name='Sheet1')
将pandas数据写入生成一个excel文件。将数据写入一个Excel中。有时候matplotlib.pyplot的图还是没有excel灵活的,需要将数据写入excel进行分析。
df.to_excel(output_file,index=True)注:数据写入 Excel,需要首先安装一个 engine,由 engine 负责将数据写入 Excel,pandas 使用 openpyx 或 xlsxwriter 作为写入引擎。
读取与解析内容为字典格式的数据到DataFrame
可以参考https://blog.csdn.net/qq_40837600/article/details/104580842 类似的做法
pandas中 clip截断函数
#将完播率大于1的情况截断取值1,下截取0.0all_data_frame['broad_rate']=all_data_frame['broad_rate'].clip(lower=0.000000,upper=1.000000)
s = pd.DataFrame(columns=['a','b'],data=[[0.0345, 0.488888],[1.747959, 0.399998],[-1.45, 0.008888],[0.998359,1.747959],[0.399998, 0.998359]])s['a']=s['a'].clip(lower=0.000000,upper=1.000000)print("s:\n{}".format(s))# print("cliped: s:{}")# a b# 0 0.034500 0.488888# 1 1.000000 0.399998# 2 0.000000 0.008888# 3 0.998359 1.747959# 4 0.399998 0.998359
Pandas某列小数转化为百分数的形式输出
print("缺失率为:{:.4f}%".format(character_loss_rate[character_list[i]] * 100))看到这,其实已经可以做基本的数据分析了,不用害怕自己不会,很多东西都是边做边查边积累,重点是要知道有这些工具函数的存在和知道原来是可以这么做的。加油!
微信公众号 旺仔的算法笔记
欢迎一起交流呀
鸣谢与参考:
https://blog.csdn.net/qq_33289694/article/details/103552228
https://blog.csdn.net/zutsoft/article/details/51482573
https://www.cnblogs.com/guxh/p/9420610.html
https://www.cnblogs.com/lemonbit/p/6810972.html
https://blog.csdn.net/Jt1123/article/details/50086595
https://www.yiibai.com/pandas/python_pandas_groupby.html
https://zhuanlan.zhihu.com/p/46465082
http://blog.leanote.com/post/boom/GroupBy%E7%BB%84%E5%90%88%E5%88%86%E5%89%B2%E5%BA%94%E7%94%A8
plt.plot画图颜色大全
https://blog.csdn.net/lly1122334/article/details/105556963
多种图的图示与样例代码。直接选择图,点击进去即可得到源代码
https://matplotlib.org/2.1.1/api/_as_gen/matplotlib.pyplot.subplot.html#matplotlib.pyplot.subplot
pandas 读写 Excel https://www.jianshu.com/p/c3c2ac84fb02















 6214
6214











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









