







本文是对七月在线课程召回算法进阶的一个简单笔记记录。 本笔记主要围绕课上所讲常见召回方式、协同过滤、关联商品召回、基于图的Swing召回算法、Embedding召回(item2vec|node2vec)、YutubeDNN 、动态多兴趣挖掘模型MIND、多路召回融合。
目录
常见召回方式

U2i
- 基于矩阵分解、协同过滤的结果,直接给u推荐i;
-
指从一个用户到达一个物品,user 到item
- 一般指用户的直接行为,比如播放、点击、购买等;
- 用户查看了一个物品,就会再次给它推荐这个物品
- 结合i2i一起使用,就是用户查看以合物品,就会给他推荐另一个相似的物品,就是u2i2i路径;
i2i:
- 计算item-item相似度,用于相似推荐、相关推荐、关联推荐。 另一种理解,从一个物品到达另外一个物品,item 到 item。
- 应用:头条,在下方列出相似的、相关的文章;
-
算法:
- 内容相似,eg:文章的相似,取标题的关键字,内容相似
- 协同过滤
- 关联规则挖掘等。
- 两个物品被同时看的可能性很大,当一个物品被查看,就给他推荐另一个物品
u2u2i
- u2u2i:基于用户的协同过滤,先找相似用户,再推荐相似用户喜欢的item;从一个用户,到达另一个用户,到达一个物品
- 先计算u2u:两种方法
- 一是:取用户的性别、年龄、职业等人工属性的信息,计算相似性,得到u2u;
- 一是:从行为数据中进行挖掘,比如看的内容和视频大部分很相似,就可以看作一类人;
- 也可以使用聚类的方法进行u2u计算
- u2u一般用在社交里,比如微博、Facebook,推荐感兴趣的人
- userB和UserC相似,如果userB查看了某个商品,就把这个商品推荐给userC;
u2i2i
- :基于物品的协同过滤,先统计用户喜爱的物品,再推荐他喜欢的物品;
- 从一个用户,通过一个物品,到达另一个物品
- 用户查看了一个耳机(u2i),找出和这个耳机相似或者相关的产品(i2i)并推荐给用户
- 对路径的使用,已经从一条线变成两条线
- 方法:就是把两种算法结合起来,先得到u2i的数据,再利用i2i的数据进行扩展,就可以从第一个节点,越过一个节点,到达第三个节点,实现推荐
- 中间的桥梁是item
u2tag2i
- u2tag2i:基于标签的泛化推荐,先统计用户偏好的tag向量,然后匹配所有的Item,这个tag一般是item的标签、分类、关键词等tag;
中间节点是Tag标签,而不是 u 或者 i
-
京东,豆瓣,物品的标签非常丰富、非常详细;比如统计一个用户历史查看过的书籍,就可以计算标签偏好的向量:标签+喜欢的强度。
-
用户就达到了tag的节点,而商品本身带有标签,这就可以互通,进行推荐
-
先算出用户的tag偏好,然后匹配item列表
-
这种方法的泛化性能比较好(推荐的内容不那么狭窄,比如喜欢科幻,那么会推荐科幻的所有内容)
-
今日头条就大量使用标签推荐
-
基于U2I 和U2U2I的区别?
U2I通常是值对于一个用户而言,通过分析此用户本身过去的购买、收藏、点击过某个对象,当下次用户访问时,给其推荐之前有过相关行为记录的内容,具体分析可以通过基于矩阵分解、协同过滤的结果,直接给u推荐i;。 而基于用户的协同过滤,先找相似用户,再推荐相似用户喜欢的item;
用户向量和物品向量相似度计算
最基本的余弦相似度:
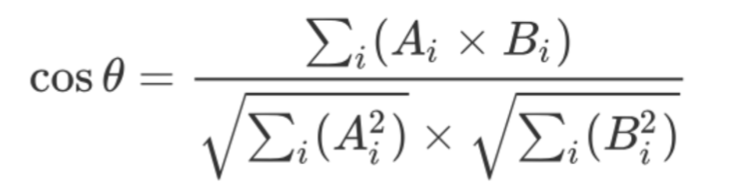

注意理解此优点: 可以推荐冷门物品(相对基于用户的协同过滤容易推荐较热门商品而言)以及效果可解释。
基于协同过滤召回
U2U2I : 基于user的协同过滤,和你类似的人也喜欢;
U2I2I: 基于item的协同过滤,喜欢这个物品的人也喜欢
基于用户相似和基于物品相似的推荐哪个更好?如何选择:
不同场景不一样,好坏与场景相关。 需要考虑计算复杂度、多样性和精度来综合决定。 对于用户数量往往是超过物品数量,尤其是对于大的电商、新闻资讯,所以更优先itemCF,商品购买场景下 : 相似用户的稳定度是要小于物品的稳定度,item的相对更稳定。
新闻资讯类、社交场景类,userCF 相对itemCF是更优的,用户的喜好稳定度是更高,而新闻item、和商品item是不断更新变化产生与剔除的。 有时会要同时考虑两种的,userCF 更偏向于推荐热门的物品,ItemCF 不会偏向推荐热门.
如何计算协同过滤?
第一步,产生一个表格并进行缺失值填充。 此处注意: 通常武断的打分是按0填充,此外可以按类别或者其他方式的均值或者中位数填充,如对于没看过的某部电影,则可以按照对过往这类电影的平均得分或打分中位数进行填充。尤其是对于用户本身行为就很稀疏的情况更不能武断的打填充0,需要进行平滑操作。
第二步,根据余弦相似度(或者其他如Jaccard相似度等) 计算用户间的相似分数
第三步,根据相似分数给用户推荐商品,利用平均加权法。比如U1和U2得到相似分数,给U1推荐I2的打分。
关联商品召回
背景:问题背景: 威化饼干和奥利奥的关联性更强还是和旺仔牛奶的关联性更强?
Q: 如何找到用户未来可能交互的商品?A: 挖掘商品关联关系,根据用户历史交互商品,找到这些商品的关联品。对于购物类商品APP页面的推荐(商品的布局) 超市货架货物的摆放等会需要用到。
如何计算: 需要考虑商品交互距离alpha和交互行为方向 θ(某商品交互之后的商品,比交互之前的商品关联性高)
商品交互距离 distance: 同一用户越近交互的商品,两者关联性越高;交互行为方向 θ(某商品交互之后的商品,比交互之前的商品关联性高)

其中从一个用户的记录中得到一对关联商品的一次得分为阿尔法乘上theta,最终这对关联商品的总得分是所有用户记录中出现的这对关联商品得分的求和。(注意不是求平均而是求和,原因是如果最终得分是计算每次得分的平均值会导致对于只是偶然出现的高得分的成为了最终得分高了,而这个偶然的高分并不能衡量整体,所以要求平均
Swing算法
是阿里内部(目前没有论文)使用较多的基于图的召回算法

思想: 两个用户都购买了某个物品,且两个用户所有购买的物品中,共同购买的物品只有这两个,说明这两个用户兴趣差异非常大,然而却同时购买了这两个物品,则说明这两个物品相似性非常大,类似最大最小原理。
基于Embedding召回
Item2Vec本质是用户交互序列sequence维度,基于item共现性来训练item embedding的方法,训练方式完全类比word2vec(item序列中的item类比句子中的单词)的训练方式,包括CBOW和skip gram两种,训练加速方法包括分层softmax和负采样。(skip gram + negative sampling 使用较多)

在实际应用中存在一些不足:
1、只能学习训练数据中 window_size 内当前词和上下文词的相关性,无法表达未登录词与当前词的相关性;
2、负样本和正样本的定义无法表达上下文场景中上文和下文的关系。



基于Youtue DNN

todo 待继续理解与查清楚: ” 函数softmax(X,W)里面两个值,隐藏层输入的信息X,权重矩阵W,这个权重矩阵W是不断优化更新的,W矩阵的列向量商品的向量,X 是用户向量“
动态多兴趣挖掘模型MIND
这个还没有怎么弄清楚,只了解到是通过分析兴趣进行权重调解拿到兴趣向量,需要结合论文找相关案例在详细看看




多路召回融合
多路召回,各有倾向性
多路召回,工程并发


鸣谢与参考:
https://www.julyedu.com/course/七月在线官方课程
https://www.zhihu.com/question/291559021/answer/805717414















 527
527











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









