









李宏毅机器学习系列-半监督学习
什么是半监督学习
顾名思义应该是一般有标签,一般没标签吧,差不多,只是没标签的占大多数,比如下图,我们有6张图,只有两张是有标签的,另外4张没标签,我们要做分类,这个就可以是半监督学习:

通常我们的监督学习是这么定义的,有R个样本,每个样本都对应标签,比如做图片分类:

那半监督学习就是这样,除了有刚才的监督学习的样本外,还有U个没标签的样本,U的数量远大于R,如果未被标签的样本用做训练集了那就叫做Transductive Learning(直推式学习),比如聚类算法,也就是拿来一起训练。如果没有一起训练叫做Inductive learning(推理式学习)就是不训练仅仅当测试,比如K近邻算法:

那为什么我们要进行版监督学习呢,不是我们没有数据,而是没有打过标签的数据,我们很多的数据是没标签的,打标签成本又比较高:

为什么版监督学习有用呢,因为未标签的数据分布可以给我们一些信息,比如下面的例子,我们知道猫跟狗在哪里,还有其他一些没标签的点,虽然我们不知道他们的标签,但是很显然的他们是可以分开的:

或许我们应该这么来分是比较好的:

但是版监督学习往往是伴随一些假设的,有没有用还是看假设跟实际情况的符合程度,比如下面的点是只狗,被错误的分在了猫里,或许是因为他们的背景颜色一样吧:

所以版监督学习有没有用,还是要看假设是不是合理的:

半监督学习的假设

生成模型上的半监督学习
下面是我们以前讲过的生成模型的例子,我们根据先验概率
P
(
C
i
)
P(C_i)
P(Ci)和不同的均值
μ
\mu
μ和协方差矩阵
∑
\sum
∑去找到共享协方差矩阵的不同均值的高斯模型
P
(
x
∣
C
i
)
P(x|C_i)
P(x∣Ci),从而可以求出分类的概率
P
(
x
∣
C
i
)
P(x|C_i)
P(x∣Ci),如下图:

如果现在有一堆没有标签的样本绿色,分布如下面,这样我们的高斯模型就要调整了,因此相关的参数也要调整:

或许高斯分布应该是这样的,也即我们的未标签的数据会重新去估计相应的参数,重新构建高斯模型:

我们来简单的看下具体是怎么做的,首先先初始化参数:
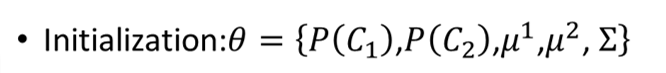
然后我们去未标签数据的后验概率:

然后我们要进行模型的更新
N
1
N_1
N1是属于
C
1
C_1
C1的样本的总个数,
N
N
N是所有样本的总个数,包括有标签和没标签的。本来我们的先验概率就是
P
(
C
1
)
=
N
1
N
P(C_1)= \frac{N_1}{N}
P(C1)=NN1,但是现在有了未被标签的数据,如果我们知道他们是
C
1
C_1
C1的概率,就是第一步计算的
P
(
C
1
∣
x
u
)
P(C_1|x^u)
P(C1∣xu),我们就可以把他们累加起来即
∑
x
u
P
(
C
1
∣
x
u
)
\sum _{x^u}P(C_1|x^u)
∑xuP(C1∣xu),把概率加起来其实就是他们是
C
1
C_1
C1的个数,因为你想如果他们都是,那概率是1,个数就是全部加起来啦,只是现在是小数,累加起来是一样的,本来就算个比例,所以这样先验概率
P
(
C
1
)
P(C_1)
P(C1)更新了。参数
μ
\mu
μ也是同样的道理,加了未标签的那部分,其他的参数也用类似的方法算出来:

更新完了,然后继续回到第一步去更新概率,反复循环,最后会收敛,但是这个结果跟初始值关系比较大,总得流程就是这样,也就是EM算法步骤的大致流程:

我们来看下上面的理论依据是什么,先看看有标签的最大似然估计:

如果加上未被标签的就是:
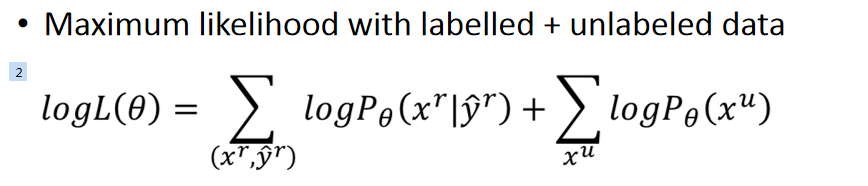
因为
x
u
x^u
xu可以是来自不同类别的,所以:
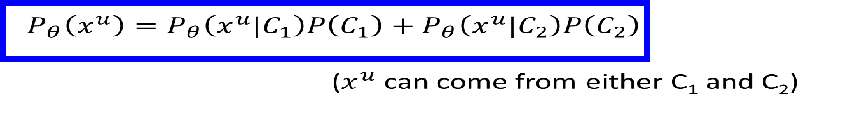
接下来我们要最大化目标函数,因为这个是非凸函数,所以我就只能慢慢的迭代来使得目标函数慢慢变大,直到收敛,前面做的更新步骤就是这个原理。
Low-density Separation非黑即白
这个假设就是这个世界是非黑即白的,我们来看个例子,有两堆数据,很显然的我们可以这样分:

但是如果仅仅考虑带标签的,我们也可以这样分:

但是如果考虑到未标签的,第二个分发就不太好了:

而第一个分发就像一条鸿沟一样,把他们分开,在边界线周围的样本密度是很低的,基本不会出现样本,也就对应Low-density Separation。
自学习
这个假设最有代表性的方法就是自学习,简单来说就是我们用有标签的先训练一个模型,然后用模型去给未标签的打标签,然后取一部分数据加到训练集里去,继续训练模型,但是这个方法对于回归没啥用,因为回归本来就是按找模型出来的结果,你再次把相同的数据给进去,出来的结果跟第一次出来的结果是一样,因此不会进行学习,所以没用:

自学习跟刚才讲的生成模型的学习很像,只是一个是硬分类,也就是给定了是哪一类,而另外一个是软分类,就是每个类别有概率大小。如果考虑用神经网络来分类,硬分类和软分类的输出是不一样的,可见如果拿软分类的结果再去训练,其实是学习不到什么的,跟上面讲的一个道理,输出是一样的,没有损失,学不到东西。因此一定要用硬分类,因为我们假设了这个时间是非黑即白的,而且是低密度的,不会又什么模交叉模糊的地方,所以不会存在又像A一点,又像B一点:

熵正则化
还有一个进阶版的方法熵正则化,比如我们用神经网络求一个分布,有5个类别,因为假设是非黑即白,所以我们希望分布是比较集中的,因此下面两种情况都是好的,他们的熵都是0,熵表示不确定性的程度,即结果越确定,熵越小,所以下面两种情况都比较确定,分布分别都集中在1和5上:

但是如果分布比较平均,那就1到5都有可能性,不确定性大了,熵就大了:
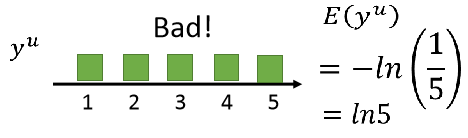
我们计算熵的公式是这样的,就是把5个类别的概率和相加取负数,是个正值:

那么我们可以重新设计损失函数,前面部分是有标签的,可以用交叉熵来衡量,后面是无标签的部分,也就是熵越小越好,因为还有个
l
a
m
b
d
a
lambda
lambda参数调节哪个权重大,所以看起来就像是正则化,所以叫熵正则化:

半监督SVM
还有一种方法,基于SVM,比如下图左边的分布,我们想把他分开,而且边界和样本之间的距离越大越好,我们穷举所有的未标签样本类别的可能性,比如右边的三种情况,找出边界和样本之间距离最大和最小化误差的情况。但是穷举法好像不太现实,所以有人提出了一种近似的方法,就是每次改一个数据的标签,看看有没改进,有就继续这样做,具体可以看下图左下角的论文:

Smoothness Assumption(平滑假设)
这个假设就像近朱者赤近墨者黑一样,假设输入很相似,那输出也相似。更精确地说法应该是输入不是均匀分布的,如果两个样本很接近,且在密度比较大的范围里,那么输出也应该接近,也就是说输入之间需要密度大的路径连接。看下图右边的图,
x
1
,
x
2
x_1,x_2
x1,x2之间的密度比较大,
x
2
,
x
3
x_2,x_3
x2,x3之间的密度小,就好像是在不同的岛屿上,中间隔着海峡,那我们就认为
x
1
,
x
2
x_1,x_2
x1,x2是同类的,他们在同一个岛屿上:

就像手写数字一样,左边的手写2可以转化到右边的2,而2通常没办法转换到3,所以左边那个跟2的相似度比3大:

其实人脸能识别也一样,可以看到左边的脸可以过渡到右边,其实是同一个脸的不同面:
再来看看文章分类,一般来说我们都是根据词的分布来分类的,通常会把有重复词比例比较大的文字归为一类,比如下图d1,d3可能是一类,d2,d4可能是一类:

但是现实情况大多数有重复词的概率很低,因为世界上的词很多,一篇文章跟另一篇文章的词重复率不会很高,有标签和没标签的文章词重复率不高,现实情况可能是这样的:

但是如果未标签样本足够多的话,可以看到d1和d5像,d5和d6像,d6和d7像,d7和d3像,所以他们应该跟d1是同类的,同理d4,d8,d9和d2是同类的:

那这个要怎么做呢,最简单的就是聚类啦,就不多讲了:

另一种方法是基于图的,简单的可以理解为我们把每个样本点都跟最近的样本连接起来,如果发现一条密度比较大的路径相连,那这些点就是同一类的,比如网站上的超链接,相互连接,一般是属于同一类内容,还有论文之间的引用:

通常这个图是要自己建的,我们可以定义两个样本之间的相似度,比如用K Nearest Neighbor,K Nearest Neighbor等,一个是找K个相似度最大的连接起来,一个是跟他相似度超过某个阈值的点相连起来。当然还可以用边的权重来近似点之间的相似度,比如用Gaussian Radial Basis function,为什么要取exp呢,为的就是让距离远的相似度越小,距离近的越大,将他们的差距拉大,就容易分开:

其实这个图的思想就是,相连的几率会相互传递,比如x是类1的,和他相连的是类1的概率就大了,然后旁边有连接的概率也会增大,标签会影响相邻点的标签概率:

理想情况就是这样,相邻的都是一类:

但是如果数据不够多的话,可能在中间会有断开的情况:

上面说的都是定性的理解图方法,下面来定量的理解下,我们定义一个平滑程度的函数S,越小越平滑,我们有两个网络,我们分别求每个点之间的差异然后求和,会发现第一个图是0.5,第二个是3,越小说明越平滑:

然后我们可以进行一些转换,y就是所有标签合并的向量,L是矩阵=D-W,W等于每个点对其他点的边权重矩阵,D是W的每一行的和放在对角线上:

于是我们发现平滑程度S是依赖于y的,于是我们可以把目标函数加上一个正则项,让他同时最小化误差的时候也要最小化平滑函数。当然我们可以把这个平滑函数放在任意的层输出中,使得他每一层的输出都平滑:

Better Representation
简单的来说就是我们要发现事物背后的规律,要发现背后的影响因素,就像这个神雕侠侣的图,杨过要剪胡子,他不是观察胡子怎么动,而是发现胡子是跟随头动的,于是观察头的动向来剪胡子:

总结
本篇主要介绍了半监督学习的一些概念和假设,很多半监督学习的方法都是基于一定的假设,思维导图:

好了,今天就到这里了,希望对学习理解有帮助,大神看见勿喷,仅为自己的学习理解,能力有限,请多包涵,图片来自李宏毅课件,侵删。















 545
545











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









