




数据挖掘12 – 零样本分类
一、预备知识
1.底层特征(Low-level Features)
底层特征是从原始输入数据中直接提取的、最基础的、通常不具有明确语义含义的数值或信号特征。
例子(以图像为例):
像素强度(灰度值、RGB值)
2.中层属性(Mid-level Attributes / Mid-level Features)
中层属性是在底层特征基础上进一步组合、聚合或抽象得到的具有一定结构或局部语义的特征。它们比底层特征更接近人类可理解的概念,但尚未达到高层语义(如“猫”、“汽车”)的程度。
局部形状(如圆形、矩形轮廓)
材质(如“光滑”、“粗糙”、“金属感”)
3.高层概念
高层概念是从底层特征 → 中层属性 → 进一步抽象得到的语义丰富、结构化、任务导向的信息单元。
回答的是“这是什么?发生了什么?意味着什么?”这类问题。
例子:
物体类别:“猫”、“汽车”、“交通灯”
4.单选题1

答案:A
5.单选题2

答案:C
解释:
底层特征(如像素值、梯度)人类很难直接描述和理解。
中层属性如“轮廓”、“纹理”、“部件” → 人类可以用语言描述
高层概念如“汽车”、“高兴”、“下雨” → 直接可用自然语言表达
6.多选题

答案:AB
二、零样本学习的基本思想(Zero-Shot Learning, ZSL)
利用语义信息(如属性、词向量、文本描述等)建立已见类(seen classes)与未见类(unseen classes)之间的联系,从而将从已见类中学到的知识迁移到未见类上。
多选题:

答案:ABC
D错误:
这个说法虽然表面上合理(不同类确实提取不同特征),但它描述的是传统分类任务中特征提取的基本性质,而不是零样本学习的基石假设。
举个例子:
输入一张 斑马 的图片 → 提取出特征向量 z₁
输入一张 长颈鹿 的图片 → 提取出特征向量 z₂
z₁ ≠ z₂,即特征不同。
但这只是说明模型能区分已知类别。
而零样本学习的关键是:模型从未见过“斑马”这个类别的任何样本!
三、基于直接属性映射(Direct Attribute Prediction, DAP)的零样本分类
1.定义
首先,通过人工定义或学习类别的语义属性(如形状、颜色等),将类别映射到属性空间。
然后,模型学习从输入数据到属性向量的映射。
最后根据属性匹配来识别新类别。
2.例子:
假设我们要构建一个系统,能识别不同动物的照片。
但有个限制:训练时只见过“马”和“老虎”的图片,从未见过“斑马”的图片。
然而,在测试时,我们希望系统也能正确识别“斑马”。
第一步:定义语义属性(人工标注)
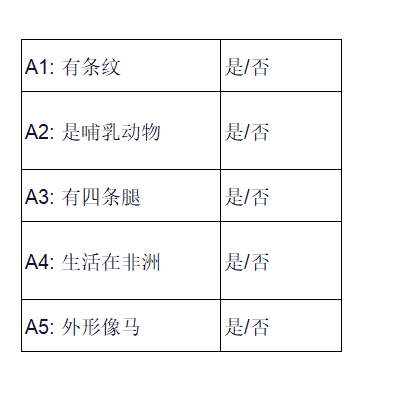
然后,为每个类别(包括未见类)填写属性向量(1=是,0=否):
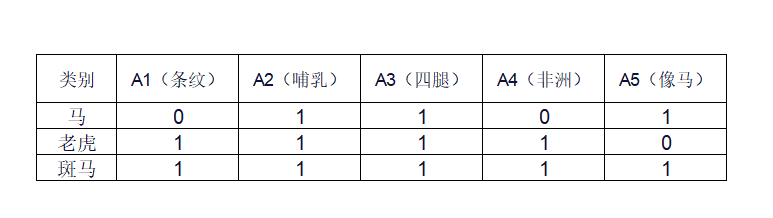
第二步:训练阶段(只用“马”和“老虎”的图像)
对每张训练图像(比如一张马的照片),我们知道它属于“马”,于是知道它的真实属性(如 A1=0, A2=1, …)。
我们为每个属性单独训练一个分类器:
分类器 f₁:输入图像 → 判断“是否有条纹”(A1)
分类器 f₂:输入图像 → 判断“是否是哺乳动物”(A2)
…
分类器 f₅:输入图像 → 判断“外形是否像马”(A5)
这些分类器可以是逻辑回归、SVM、神经网络等。
第三步:测试阶段(遇到一张“斑马”图片)
现在,系统收到一张从未见过的斑马照片。
预测属性:
用训练好的5个分类器分别预测:
f₁(斑马图) → 有条纹?→ 输出概率 0.95
f₂(斑马图) → 是哺乳动物?→ 0.99
f₃ → 四条腿?→ 0.98
f₄ → 非洲?→ 0.85
f₅ → 像马?→ 0.90
得到预测属性向量:
a = [0.95,0.99,0.98,0.85,0.90]
与已知类别属性比对:
计算
a 与每个候选类别(包括未见类“斑马”)的属性向量之间的相似度
(可用余弦相似度或负欧氏距离):
与“马” [0,1,1,0,1] 的距离较大(因为A1和A4不匹配)
与“老虎” [1,1,1,1,0] 的距离也较大(A5不匹配)
与“斑马” [1,1,1,1,1] 非常接近!
做出预测:
系统选择属性最匹配的类别 → “斑马”
这样实现了零样本分类!
3.题目练习
(1)多选题

答案:ABC
**A正确。**在DAP方法中,首先要从图像(或其他输入)中提取视觉特征。
**B正确。**这正是“直接属性映射”的核心。
模型学习的是:如何从视觉特征 → 预测每个语义属性(如“有条纹”、“是哺乳动物”等)。
即建立从特征到属性的映射关系(通过独立的分类器实现)。
C正确
要做零样本分类,必须知道未见类别的语义信息。
比如“斑马”对应的属性向量 [1,1,1,1,1] 就是它的属性描述。
测试时,系统会将预测出的属性与这些描述进行匹配。
因此,目标类的属性描述是必不可少的先验知识。
D错误
在DAP中,没有直接学习从特征到类别的映射。
它不直接建模“这个图像属于哪个类别”,而是:
先预测属性 → 再用属性比对类别。
所以它绕过了“特征→类别”的直接映射。
如果存在这种映射,就不是真正的“零样本”,因为需要训练时见过该类别。
(2)多选题

答案:ABCD
四、特征提取
1.定义
给定一张图片,如何提取区分其中目标类型的特征,即形成目标的表示。
2. 选择特征提取方式:深度卷积神经网络(CNN)
(2)多选题

答案:ABCD
解释:
A正确。
在CNN的第一层,卷积核常学习到类似Sobel、Prewitt的滤波器,用于检测边缘、线条、纹理等低级特征。
B正确。
这正是卷积操作的核心优势:共享权重 + 滑动窗口。
同一个卷积核在整个图像上滑动,因此无论该特征出现在哪个位置,都能被检测到。
C正确。
池化的作用:
1)降低空间维度,减少计算量;
2)增强对小范围位移的鲁棒性(例如,一个特征稍微移动了一点,只要仍在池化窗口内,最大值仍能被保留);
3)提高了平移不变性;
4)同时保留主要信息,提升特征的抽象能力。
D正确。
标准CNN的卷积核是固定方向的,比如它学会检测“从左上到右下的斜边”,但如果物体旋转了(比如变成水平),它就无法识别。
CNN本身不具有旋转不变性(Rotation Invariance)。
3.特征-属性映射
是将原始数据中的“特征”与某种语义或结构上的“属性”建立对应关系。
多选题:

答案:ABCD

















 2927
2927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









