






一、数据挖掘起源
人们迫切希望能对海量数据进行深入分析,发现并提取隐藏在其中的信息,以更好地利用这些数据。但仅以数据库系统的录入、查询、统计等功能,无法发现数据中存在的关系和规则,无法根据现有的数据预测未来的发展趋势,更缺乏挖掘数据背后隐藏知识的手段。正是在这样的条件下,数据挖掘技术应运而生。
数据挖掘同样需要数据库系统提供有效的存储、索引和查询处理支持。源于高性能(并行)计算的技术在处理海量数据集方面常常是重要的。分布式技术也能帮助处理海量数据,并且当数据不能集中到一起处理时更是至关重要。

二、什么是数据挖掘
①数据挖掘是在大型数据存储库中,自动地发现有用信息的过程。
②数据挖掘是指从大量的数据中通过算法搜索隐藏于其中信息的过程。
数据挖掘是数据库中知识发现(knowledge discovery in database, KDD)不可缺少的一部分,而KDD是将未加工的数据转换为有用信息的整个过程,该过程包括一系列转换步骤, 从数据的预处理到数据挖掘结果的后处理。
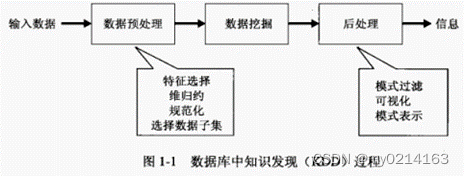
三、数据挖掘任务
数据挖掘任务分为下面两大类
预测任务:根据其他属性值预测特定属性值,被预测的属性一般称为目标变量(因变量),用来做预测的属性称为说明变量(自变量)
描述任务:导出概括数据中潜在联系的模式(相关、趋势、聚类、轨迹和异常)
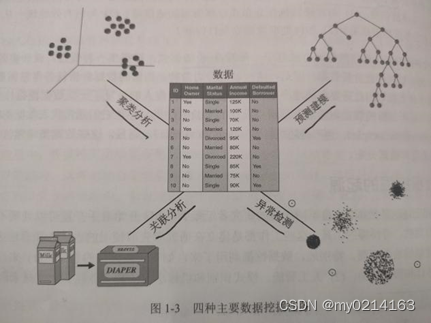
①预测建模:以说明变量函数的方式为目标变量建立模型。两类预测建模任务:分类(预测离散的目标变量)回归(预测连续的目标变量)都是建立一个模型,使目标变量预测值与实际值之间的误差最小。例如预测鸢尾花的种类是分类,预测股票涨跌是回归。
②关联分析:用来发现描述数据中强关联特征的模式。这个模式通常用蕴涵规则或特征子集的形式表示。以有效的方式提取最有趣的模式。例如识别用户访问的web页面和发现用户经常同时购买的商品。
③聚类分析:发现紧密相关的观测值组群。使得与属性不同簇的观测值相比,属于同一簇的观测值相互之间尽可能相似。(就是簇与簇之间尽可能分开,同一簇之间尽可能在一起相似)例如用来对用户分组,文档聚类。
④异常检测:识别其特征显著不同于其他数据的观测值,就是异常点或离群点。为了发现真正异常点而避免将正常的对象标注为异常点。需要具有高检测率和低误报率。例如检测欺诈,疾病的不寻常模式。
四、数据挖掘要解决的问题:
可伸缩,高维性,异种数据和复杂数据,数据的所有权与分布,非传统的分析。
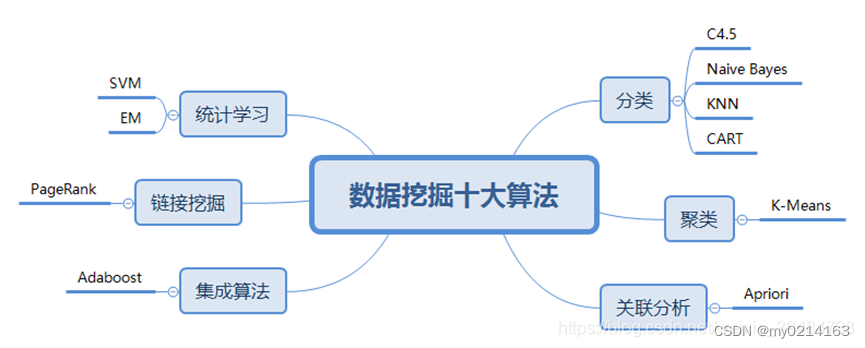
五、数据挖掘十大算法
①C4.5决策树
②K-means聚类算法
③SVM支持向量机
④Apriori
⑤EM
⑥PageRank
⑦Adaboost
⑧KNN分类算法
⑨Naive Bayes贝叶斯算法
⑩CART
















 620
620











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









