







import java.util.*
Collection的API说明指示有3个主要的接口,List, Set 和Map
List:知道索引的位置,知道插入的顺序
Set:不会有重复
Map:用key来搜索(Map 没有继承Collection这个接口,但是仍然算是Collection的一份子(见下图))
 - 小镜子~ - 菜园子")
※TreeSet:(以有序状态保持并可防止重复)
声明类似ArrayList
如果插入有重复,则忽略此次插入(例如下图):
 - 小镜子~ - 菜园子")
以下是输出结果:
 - 小镜子~ - 菜园子")
插入的字符串,会以abcdefg...的顺序自动排列:(因此TreeSet 插入的效率不高,总是要寻找合适的位置)
 - 小镜子~ - 菜园子")
 - 小镜子~ - 菜园子")
还可以利用TreeSet的另一个构造函数TreeSet<T>(Comparator c)来自定义排序方式:
 - 小镜子~ - 菜园子")
注:TreeSet内部的的元素必须是Comparable的(implements Comparable | |创建一种排序 implements Comparator)
※HashSet(可防止重复,可快速查找)
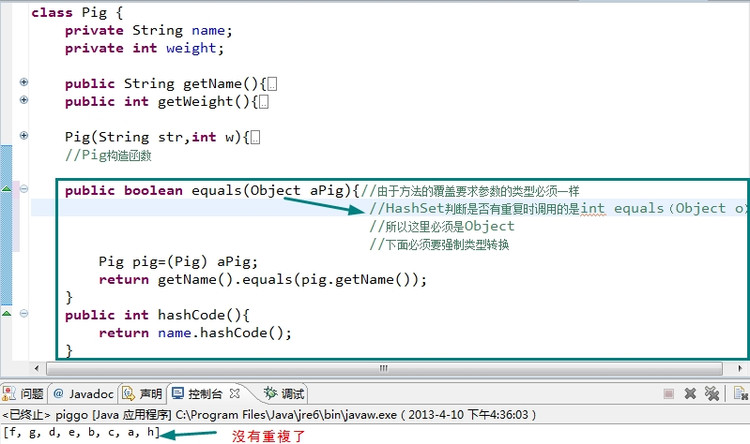
HashSet能避免重复主要是因为它能用equals(Object o)和HashCode()两个条件,判断两个对象是否相等
//注意不同的对象也可能有相同的HashCode, HashSet要调用equals()来判断两个对象是否真的相等。不过两个相等对象的HashCode一定是相等的
但是系统判断两个对象是否相等equals()的方法是狭隘的(仅根据引用是否向着同一个对象地址)(见下图)
所以我们有时候需要自己定义判断对象是否相等的方法
对于要被存放的类,比如HashSet<Pig>,那么在Pig类里,要
覆盖public int hashCode()方法,equals()方法同样要被覆盖
 - 小镜子~ - 菜园子")
(上图有不严谨的地方,不同的对象有不同的id或内存地址,因此HashSet判断他们不等,且很可能有不同的HashCode)
在Class Pig里覆盖HashCode()和equals(Object o):
MAP
map可以理解为映射
※HashMap (可以用成对的name/value来保存与取出)
HashMap有两个类型参数 HashMap<K,V>分别代表key,关键词,value,值
HashMap可以根据关键字来取值
HashMap例:

※LinkedHashMap(类似HashMap,加上可以记住元素插入的顺序这一功能)
LIST
※ArrayList:(可变长集合数组)
e.g. ArrayList <String> songList=new ArrayList<String>();
void ArrayList.add(Object o)在结尾添加o (也可指定位置,一般不)
int ArrayList.size()//返回ArrayList的大小
boolean ArrayList.contains(s)//查询表内是否有s,如果有返回true
boolean ArrayList.isEmpty()//判断ArrayList是不是空表,如果是,返回true
int ArrayList.IndexOf(b)//查询b在表中的位置,
如果有,返回位置(0,1,2,3...),如果没有,经实验,返回-1
E ArrayList.remove(s)
//删除元素,经实验,返回的是被remove的对象
※LinkedList(链表 针对经常插入删除的高效率集合,查找不方便)
更多的List方法已单独列出,见:
http://blog.163.com/it_novice/blog/static/20918306920133891020132/
关于List的sort()方法的深层探究①:
http://blog.163.com/it_novice/blog/static/20918306920133810327415/
关于List的sort()方法的深层探究②:
http://blog.163.com/it_novice/blog/static/20918306920133985433867/















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









