







直接上代码
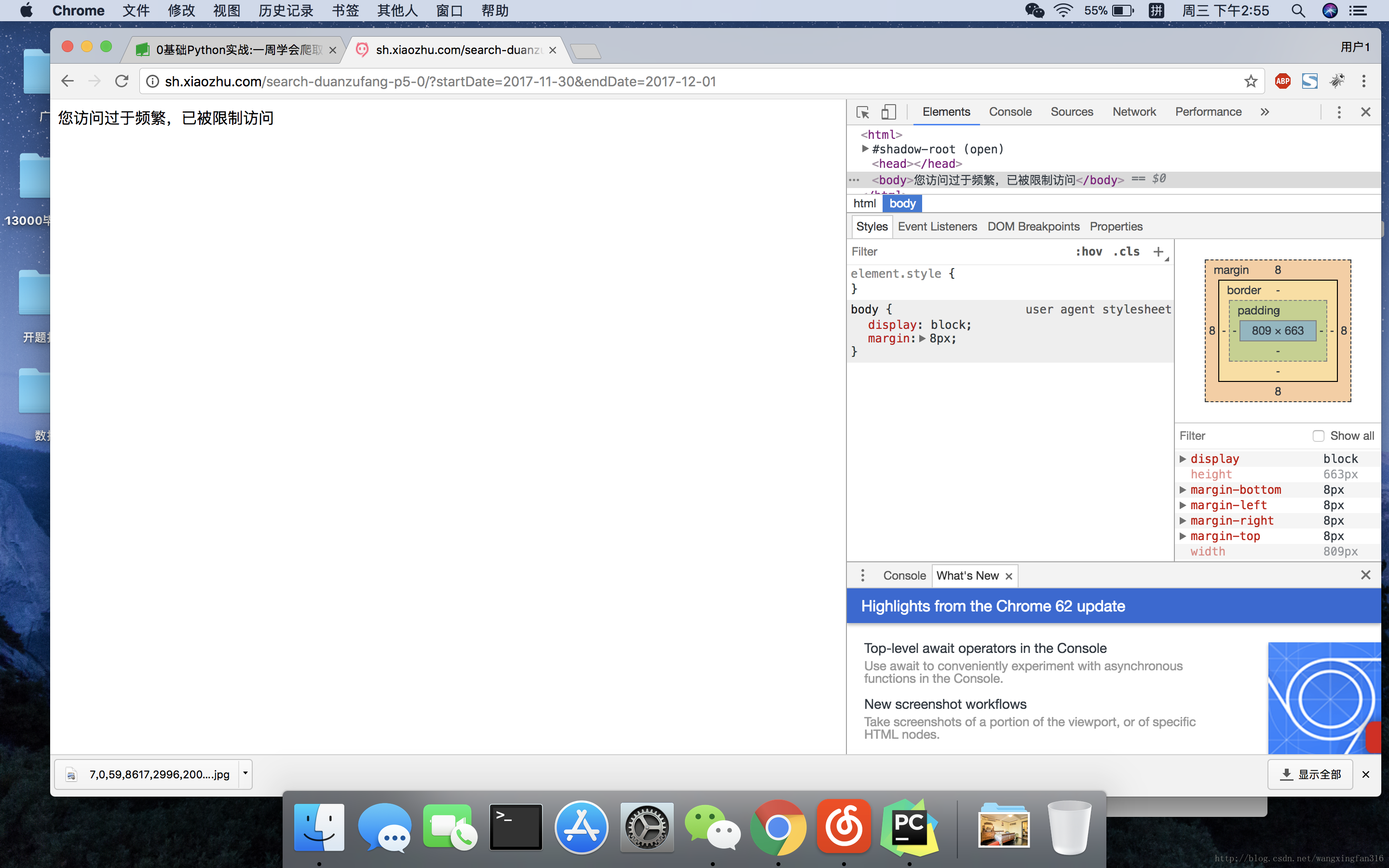
没有添加间隔时间
几页之后就被封了
#!/user/bin/env python
#-*- coding:utf-8 -*-
from bs4 import BeautifulSoup
import requests
import re
#函数求详细信息
def get_detail(urls):
web_data = requests.get(urls)
soup = BeautifulSoup(web_data.text,'lxml')
# 获取标题,select获取列表,[0],获取第一个就是我们要的
titles = soup.select('div.con_l > div.pho_info > h4')[0].text
# 获取地址
addr = soup.select('div.pho_info > p > span')[0].text
# 获取租金
day_cost = soup.select('#pricePart > div.day_l > span')[0].text
# 房源图片
imgs = soup.select('img[id="curBigImage"]')[0].get('src')
# 房东图
load_imgs = soup.select('div.member_pic > a > img')[0].get('src')
# 房东网民
load_names = soup.select('div.w_240 > h6 > a')[0].text
# 房东性别
load_sexs = soup.select('div.member_pic > div')[0].get('class')[0]
#判断房东男女
if load_sexs == 'member_ico':
load_sexs = '男'
else:
load_sexs = '女'
#title, add, day_costs, img, load_img, load_name, load_sex
datas = [titles,addr,day_cost,imgs,load_imgs,load_names,load_sexs]
data = {
'title':datas[0],
'add':datas[1],
'day_cost':datas[2],
'img':datas[3],
'load_img':datas[4],
'load_name':datas[5],
'load_sexs':datas[6]
}
print(data)
#爬取1页中的24个链接
def get_link(url):
#url = 'http://sh.xiaozhu.com/search-duanzufang-0/?startDate=2017-11-30&endDate=2017-12-01'
web_datas = requests.get(url)
soup = BeautifulSoup(web_datas.text,'lxml')
#链接
for i in range(23):
link = soup.find_all(href=re.compile(r'http://sh.xiaozhu.com/fangzi/.'))[i].get('href')
get_detail(link)
get_link('http://sh.xiaozhu.com/search-duanzufang-0/?startDate=2017-11-30&endDate=2017-12-01')
for i in range(2,10):
get_link('http://sh.xiaozhu.com/search-duanzufang-p%d-0/?startDate=2017-11-30&endDate=2017-12-01'%i)过程















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









