







1 主要几个难点
1。每页会有20个段子,会出现加载更多,点击加载更多,url并没有改变,打开显示网页源代码,并没有获得段子。所以需要用到抓包获取实际段子地址,使用Chrome自带的检查找到真实的地址。
触发一次加载操作,我们获得的真实地址为:
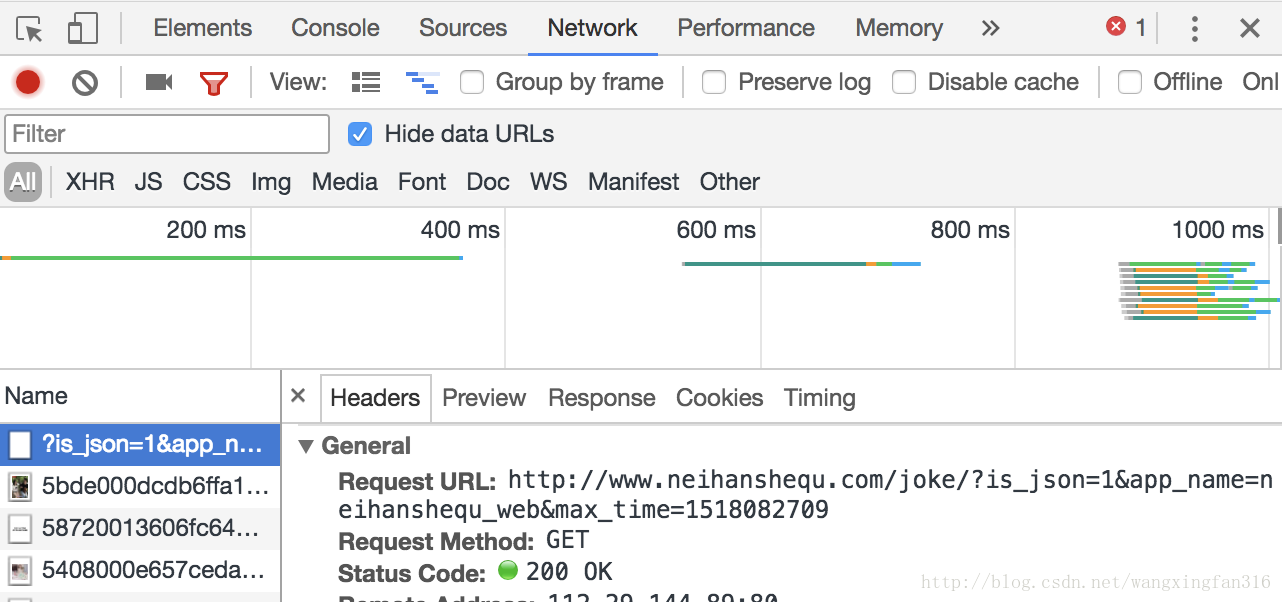
多次触发后分析地址可得到max_time为time.time()获取的当前的时间戳,所以我么可以通过推后time.sleep(2)来更新段子。
2。从网页使用re获取的为unicode,需要将unicode列表转换为汉字。
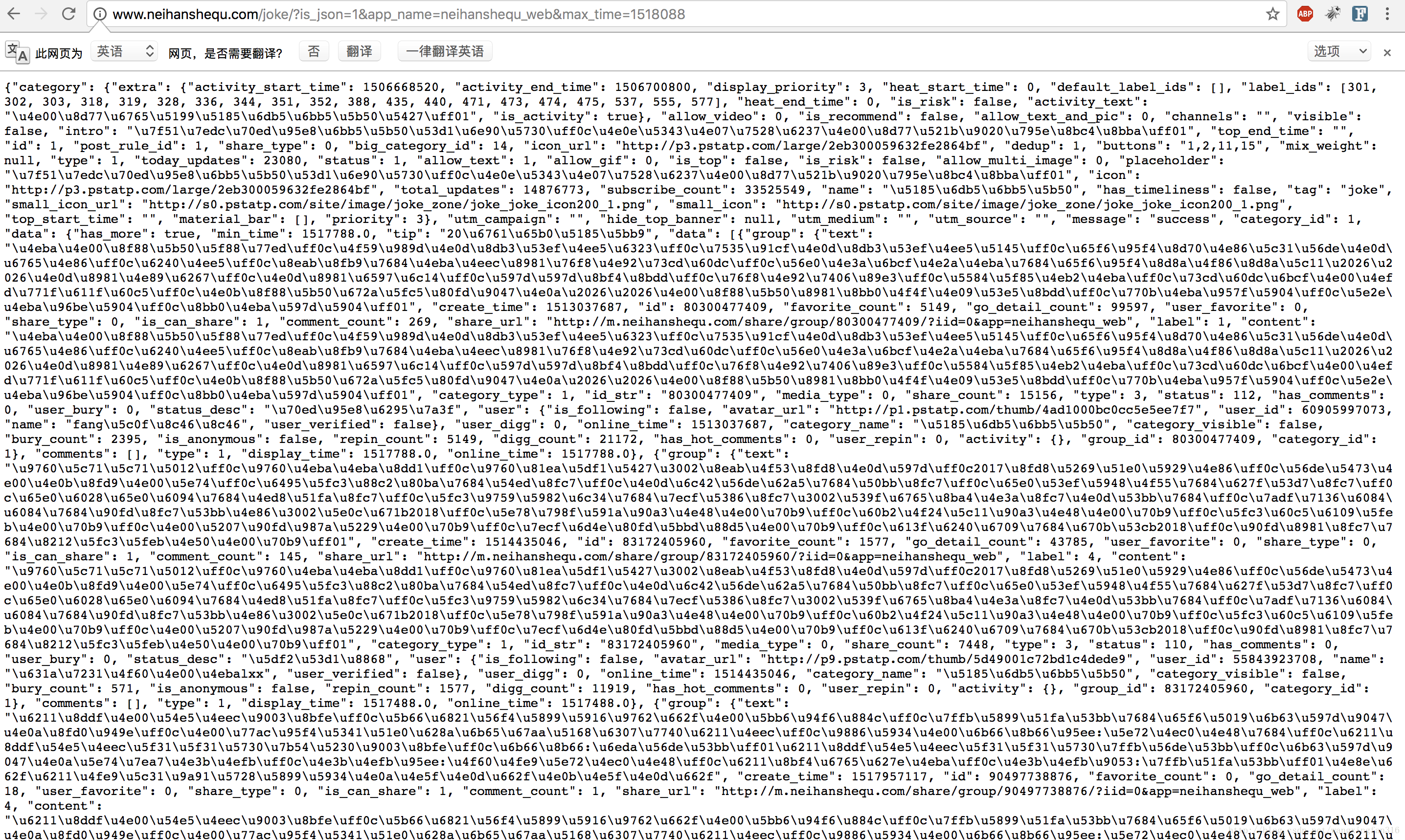
参考上一博客。
3。使用多线程,使用threading模块,可以提高效率,但本题只是简单的看不出太多差别。还有一个问题设置两秒的间隔可能会产生重复。
2 代码
#!/user/bin/env python
#-*- coding:utf-8 -*-
#M10
import urllib.request
import urllib.error
import re
import time
import threading
'''
定义了两个功能相同的线程,演示用
'''
text_list = []#用于存储内容的list
class A(threading.Thread):#定义第一个线程
def __init__(self):#必须要有的方法
threading.Thread.__init__(self)
def run(self):#必须要有的方法
for j in range(0,50,2):
time_page = int(time.time())
url = 'http://www.neihanshequ.com/joke/?is_json=1&app_name=neihanshequ_web&max_time={}'.format(time_page)
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
request = urllib.request.Request(url,headers=header)
try:
text = urllib.request.urlopen(request).read().decode('utf-8')#异常
except urllib.error.URLError as e:
print(e.reason)
print(e.code)
pat = '"group": {"text": "(.*?)"'
text_list_re = re.compile(pat).findall(text)
for x in text_list_re:#一维列表的形式添加到text_list,不用此方法将产生二维列表而报错
text_list.append(x)
time.sleep(2)
f = open('/Users/wangxingfan/Desktop/1.txt','wb')#保存到桌面
#print(len(text_list))
for i in text_list:#写入文件
try:#防止异常是终止
f.write(i.encode('latin-1').decode('unicode_escape').encode('utf-8'))
f.write('\n'.encode('utf-8'))
except:
pass
f.close()
class B(threading.Thread):#定义第二个线程
def __init__(self):#必须要有的方法
threading.Thread.__init__(self)
def run(self):#必须要有的方法
for j in range(1,50,2):
time_page = int(time.time())
url = 'http://www.neihanshequ.com/joke/?is_json=1&app_name=neihanshequ_web&max_time={}'.format(time_page)
header = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
request = urllib.request.Request(url,headers=header)
try:
text = urllib.request.urlopen(request).read().decode('utf-8')#异常
except urllib.error.URLError as e:
print(e.reason)
print(e.code)
pat = '"group": {"text": "(.*?)"'
text_list_re = re.compile(pat).findall(text)
for x in text_list_re:
text_list.append(x)
time.sleep(2)
f = open('/Users/wangxingfan/Desktop/1.txt','wb')#保存到桌面
for i in text_list:#写入文件
try:#防止异常是终止
f.write(i.encode('latin-1').decode('unicode_escape').encode('utf-8'))
f.write('\n'.encode('utf-8'))
except:
pass
f.close()
a = A()#实例化
a.start()#启动线程
b = B()
b.start()
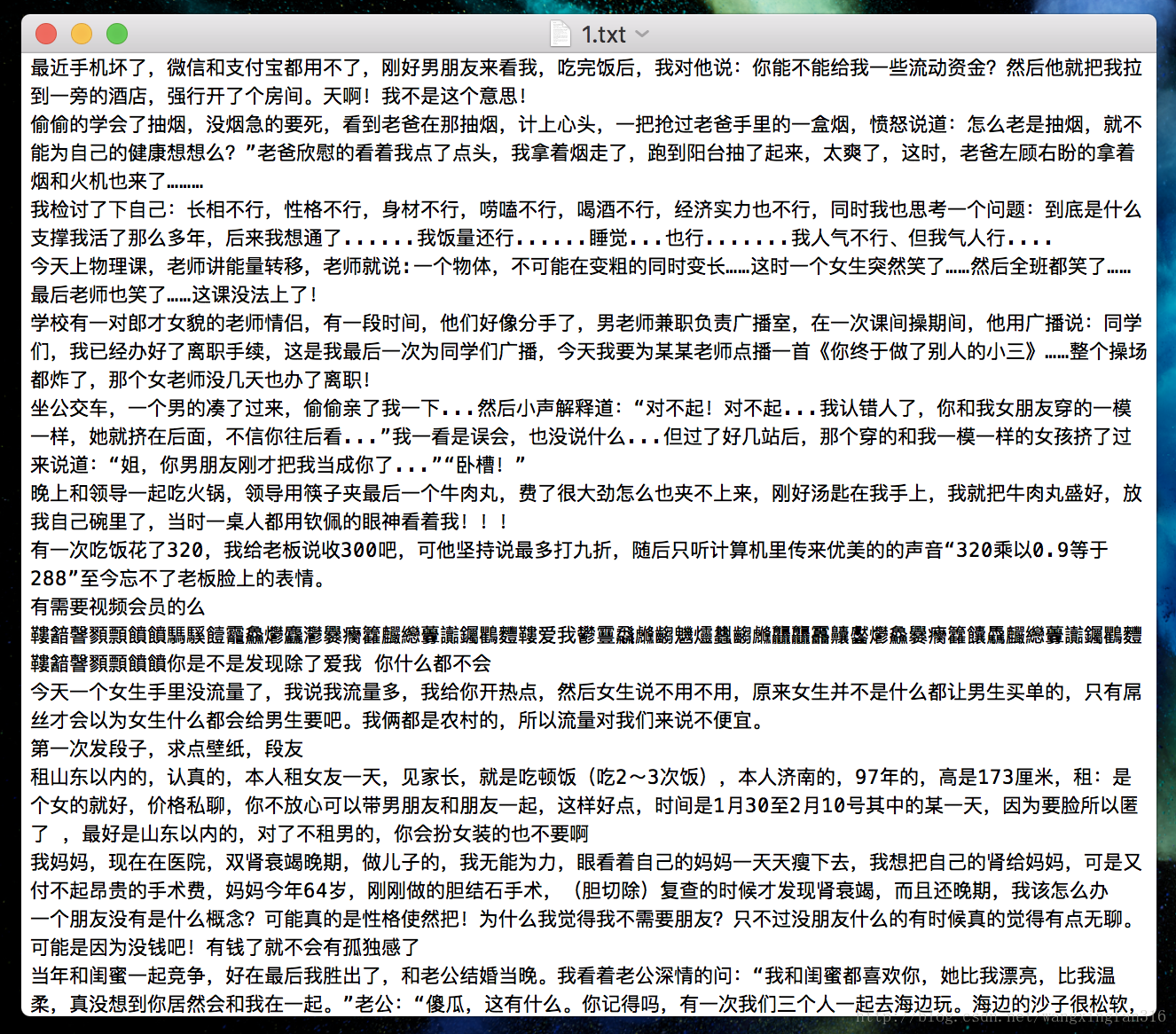
3 结果
最终结果隔一段时间产生一次乱码,不知原因在哪















 9867
9867

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









