







文章内容仅用于自己知识学习和分享,如有侵权,还请联系并删除 :)
之前不太会用,单纯想记录一下,后面或许还会用到
目的:结合dask和parallel提高数据计算效率
1. 教程
[1] Pleasingly Parallel Programming: link
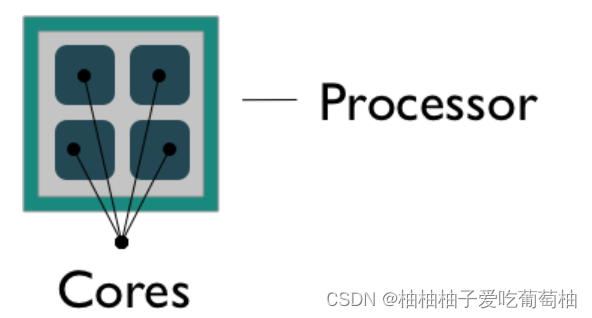
1.1 处理器,核和线程 Processors (CPUs), Cores, and Threads
-
Microprocessor: an integrated circuit that contains the data processing logic and control for a computer.
-
Multi-core processor: a microprocessor containing multiple processing units (cores) on a single integrated circuit. Each core in a multi-core processor can execute program instructions at the same time.
-
Process: an instance of a computer program (including instructions, memory, and other resources) that is executed on a microprocessor.
-
Thread: a thread of execution is the smallest sequence of program instructions that can be executed independently, and is typically a component of a process. The threads in a process can be executed concurrently and typically share the same memory space. They are faster to create than a process.
-
Cluster: a set of multiple, physically distinct computing systems, each with its own microprocessors, memory, and storage resources, connected together by a (fast) network that allows the nodes to be viewed as a single system.
1.2 Parallelization with Dask
主要看了Dask
1.2.1 Dask简介
[2] Dask python库官方安装和使用教程: link
[3] 中文 掘金: dask介绍: link (介绍了chunk)
[4] 中文 腾讯:Python 数据科学 Dask.array:并行计算的利器: link
[5] 中文 风中飞舞:Dask教程 数组: link (这个讲dask array和numpy array的区别,以及chunk讲的很好)
-
定义: Dask is a tool that helps us easily extend our familiar python data analysis tools to medium and big data, i.e. dataset that can’t fit in our computer’s RAM. In many cases, dask also allows us to speed up our analysis by using mutiple CPU cores. Dask can help us work more efficiently on our laptop, and it can also help us scale up our analysis on HPC and cloud platforms. Most importantly, dask is almost invisible to the user, meaning that you can focus on your science, rather than the details of parallel computing.
-
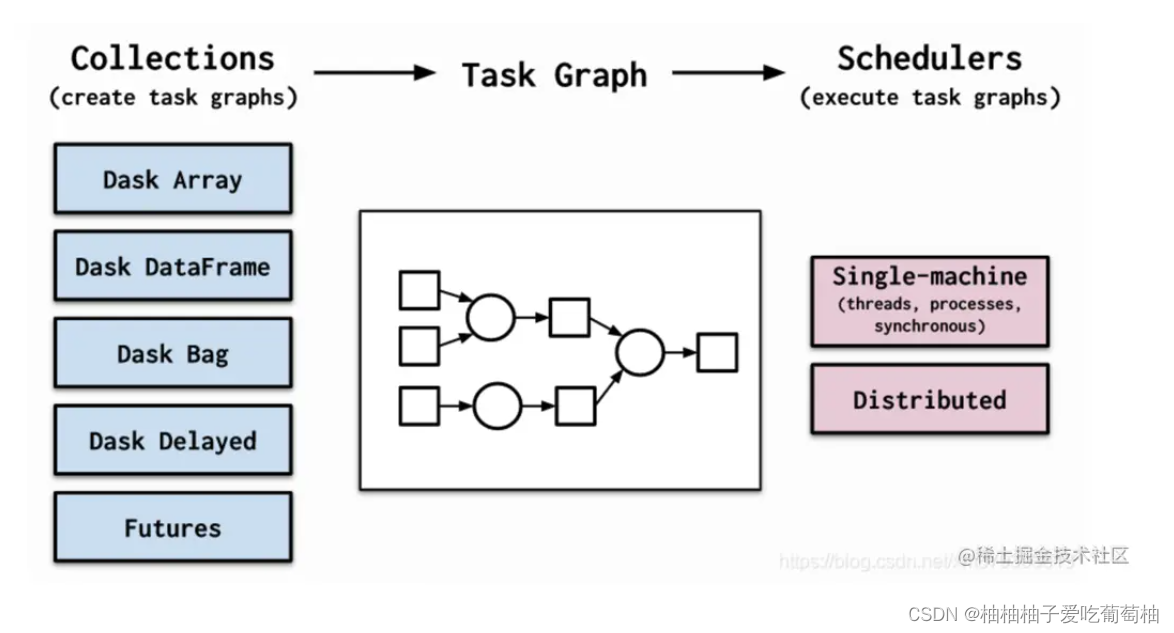
数据结构: 目前dask支持5种主要的数据结构,目前dask支持5种主要的数据结构,分别是
- Array(用于存放类numpy的多维数组),
- DataFrame(不用多说,类pandas的二维表结构的数据帧),
- Bag(更简单的一个数组),
- Delayed(对函数的异步处理封装,针对本地多进程与多线程),
- Futures(对函数的分布式异步提交处理封装,比delayed多提供网络api)
1.2.2 Dask和array
[3] 中文 掘金: dask介绍: link (介绍了chunk)
[4] 中文 腾讯:Python 数据科学 Dask.array:并行计算的利器: link
[5] 中文 风中飞舞:Dask教程 数组: link (这个讲dask array和numpy array的区别,以及chunk讲的很好)
[6] 地学格网数据处理: Computing with Dask: link (讲的很详细)
[7] 地学格网数据处理: Basics of Xarray with Dask Parallization for Earth Data: link
[8] 地学格网数据处理 : An Introduction to Earth and Environmental Data Science: link
-
为什么Dask array运算效率会比较高 ?
其实dask并没有真正的把所有分块后的数据读入内存,只是在内存中存放了一个指针,该指针指向了这些数据块,这里涉及一个重要概念–Delayed(延迟计算) [3]
Dask.array的核心设计思想之一是将数组拆分成小块,并使用延迟计算的方式执行操作。这种分块策略有以下几个优势 [4] :
-
处理大规模数据:将数据拆分成小块,可以使Dask.array处理比内存更大的数据集。每个小块可以在内存中处理,从而有效地利用计算资源。
-
并行计算:Dask.array可以利用多核或分布式系统来并行执行计算。每个小块可以在不同的处理器上并行计算,从而加快计算速度。
-
节约资源:Dask.array只在需要时执行计算,避免了一次性加载整个数组到内存中,节约了内存和计算资源
-
补充 [6]: Dask array的区别和 numpy array的不同,调用前不占空间, 直到we call .compute() on a dask array, the computation is trigger and the dask array becomes a numpy array.
补充[6]: chunk的概念
The dask array representation reveals the concept of “chunks”. “Chunks” describes how the array is split into sub-arrays. We did not specify any chunks, so Dask just used one single chunk for the array. This is not much different from a numpy array at this point.
补充[8]: 关于Distributed Clusters 分布式集群一个常见的错误是过早使用分布式模式。对于较小的数据,分布式实际上比默认的多线程调度程序或根本不使用 Dask 要慢得多。只有当数据远大于计算机内存所能处理的容量时,才应该使用分布式。
- 案例讲解
- [6] Computing with Dask: link (讲的很详细)
1.2.3 Dask和xarray
dask和xarry和rioxarray结合可以更高效的处理遥感数据
-
xarray 和dask的关系: Almost all of xarray’s built-in operations work on Dask arrays.
link -
rioxarray 和dask的关系: rioxarray extends xarray with the rio accessor, which stands for “raster input and output. link
[7] 地学格网数据处理: Basics of Xarray with Dask Parallization for Earth Data: link
[8] 地学格网数据处理 : An Introduction to Earth and Environmental Data Science: link
[9] 地学格网数据处理 : link (xarray函数中没有自己想要的)
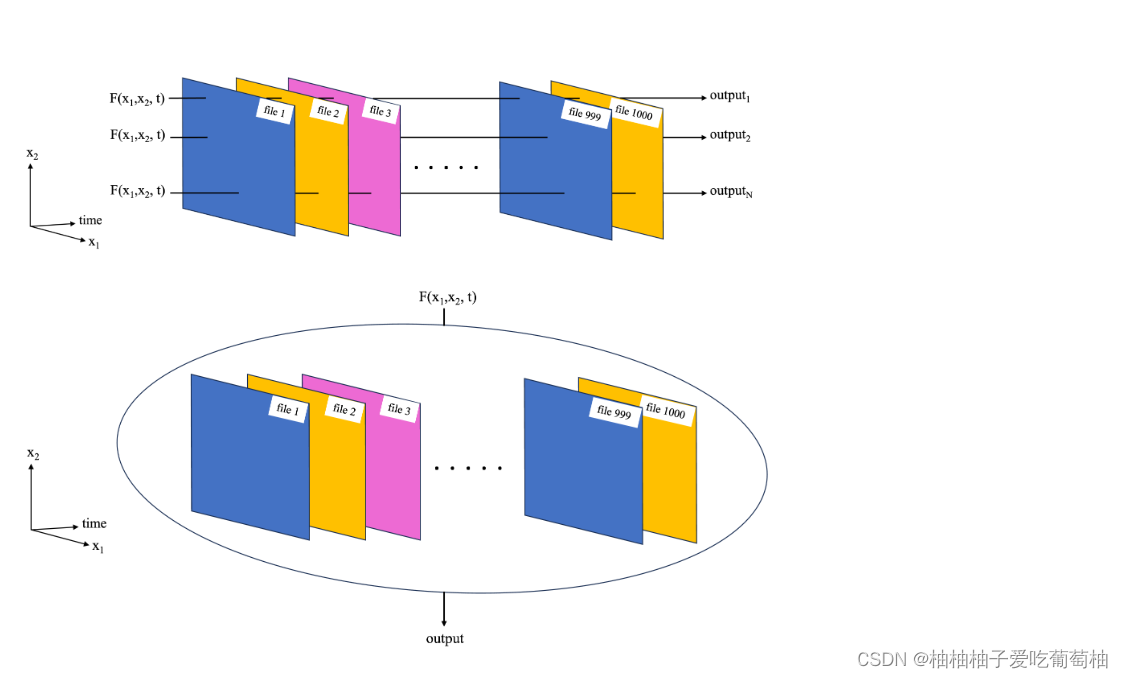
作者主要介绍了了处理地学数据并行运算的两种情况: computation which is easily iterable over multiple files和computation which is not easily iterable over multiple files.
-
A computation which simply needs to be replicated many times, such as applying the same computation to 1000 files. 对每个文件的操作都一样
The first schematic (below) shows an example for a common NASA Earthdata set format, where each file contains data for one timestamp, as well as spatial dimensions such as x1=latitude, x2=longitude. We want to apply a function F(x1,x2) to each file.
Alternately, each file could correspond to a satellite orbit, and x1, x2 are the satellite cross-track and along-track dimensions.

-
A computation which cannot trivially be replicated over multiple files, or over parts of a single file. 需要同时读取多个文件再处理
In the example of the NASA Earthdata set, where each file corresponds to a separate time stamp, this type of parallelization challenge could correspond to taking the mean and standard deviation over time at each latitude, longitude grid point (second schematic below).
In this case, data from all the files is required to compute these quantities.
Another example is an empirical orthogonal function (EOF) analysis, which needs to be performed on the entire 3D dataset as it extracts key modes of variability in both the time and spatial dimensions (third schematic).
================结合链接[7]理解============
================结合链接[7]理解============
import dask
from dask.distributed import Client, LocalCluster
# 1. 不够快
%%time
#sstdata['analysed_sst'].mean(dim='time').compute() # Un-comment to test computation time.
# 2. 调用Clinent函数
# client = Client()
Client(n_workers=2, threads_per_worker=2, memory_limit='1GB'):
# 参数含义:
n_workers=2: This tells the system to use 2 separate computers or cores to run your computations. 计算机的核。
threads_per_worker=2: This tells each of the 2 computers or cores to use 2 separate "threads" (or parts) to run
the computations. This allows the computations to be split up and run in parallel, which can make them faster.
memory_limit='1GB': This tells the system to limit the amount of memory that each of the 2 computers or cores can use to 1 gigabyte (GB). This can be useful to prevent the system from using too much memory and slowing
down.
# 3. 调用后速度变快
%%time
meansst_2dmap = sstdata['analysed_sst'].mean(dim='time').compute()
- 补充案例:并行运算时候,xarray函数中没有自己想要的函数,解决方法 [9] link
Custom workflows and automatic parallelization
方法1: Almost all of xarray’s built-in operations work on Dask arrays. If you want to use a function that isn’t wrapped by xarray, one option is to extract Dask arrays from xarray objects (.data) and use Dask directly.
方法2: Another option is to use xarray’s apply_ufunc() function, which can automate embarrassingly parallel “map” type operations where a function written for processing NumPy arrays should be repeatedly applied to xarray objects containing Dask arrays. It works similarly to dask.array.map_blocks() and dask.array.blockwise(), but without requiring an intermediate layer of abstraction.
一些想法:
提高代码的运行效率主要从两个维度出发:减小内存占用和并行。
-
dask: 先考虑读入数据内存占用。 dask数据结构的好处: dask array和 xarray只有调用的时候值得时候才会占用内存,这是其相对于numpy的好处,会减小内存的占用。
-
dask+ parallel: 再考虑如何提高计算效率,计算效率可以结合并行。但是如果想让速度更快,还是得用并行,并行的方法可以直接调用dask库,或者参考[9] link
参考文献
[1] Pleasingly Parallel Programming: link
[2] Dask python库官方安装和使用教程: link
[3] 中文 掘金: dask介绍: link (介绍了chunk)
[4] 中文 腾讯:Python 数据科学 Dask.array:并行计算的利器: link
[5] 中文 风中飞舞:Dask教程 数组: link (这个讲dask array和numpy array的区别,以及chunk讲的很好)
[6] 地学格网数据处理:Computing with Dask: link (Dask array 讲的很详细)
[7] 地学格网数据处理:Basics of Xarray with Dask Parallization for Earth Data: link
[8] 地学格网数据处理 : An Introduction to Earth and Environmental Data Science: link
[9] 地学格网数据处理 : link (xarray函数中没有自己想要的, 解决方法)

















 1167
1167

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









