








 超级会员免费看
超级会员免费看
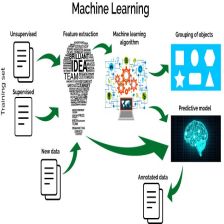
文章大纲
Up until this point, we have focused on data engineering workloads with Apache Spark. Data engineering is often a precursory step to preparing your data for machine learning (ML) tasks, which will be the focus of this chapter. We live in an era in which machine learning and artificial intelligence applications are an integral part of our lives.
Chances are that whether we realize it or not, every day we come into contact with ML models for purposes such as online shopping recommendations and adver‐ tisements, fraud detection, classification, image recognition, pattern matching, and more. These ML models drive important business decisions for many companies. According to this McKinsey study, 35% of what consumers purchase on Amazon and 75% of what they

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











