






计算多样性指数
#设置工作目录
setwd(“F:\论文\博士文章1\数据”)
#需要加载vegan包和picante包,没有安装需要先安装
library(vegan)
library(picante)
library(readxl)
library(vegetarian)
library(writexl)
#读入抽平后的otu表
a = read_excel(“6agb株丛数.xlsx”,sheet = “原整理好数据”)
a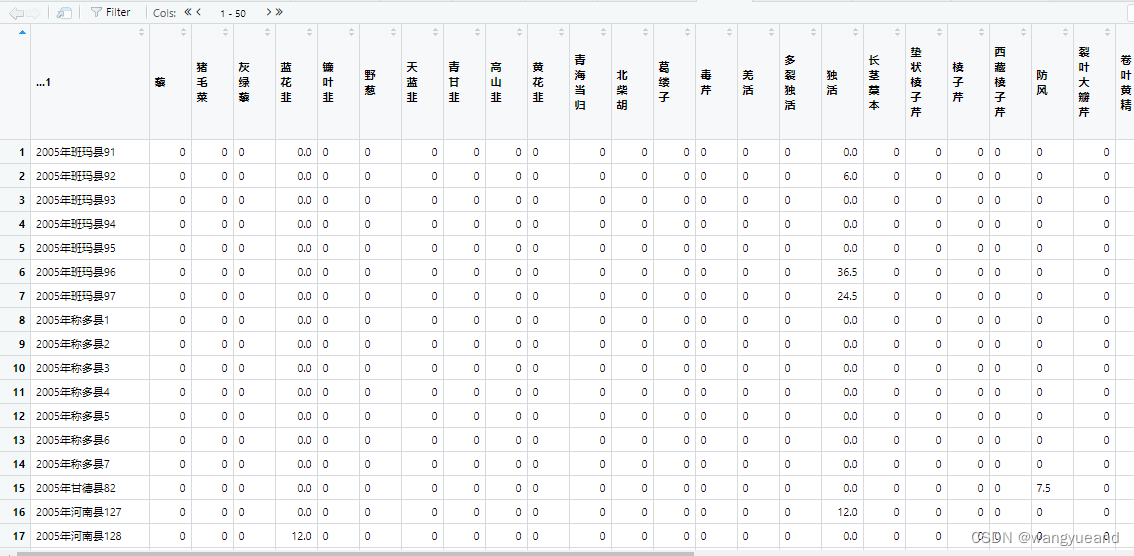
#将otu数据转置
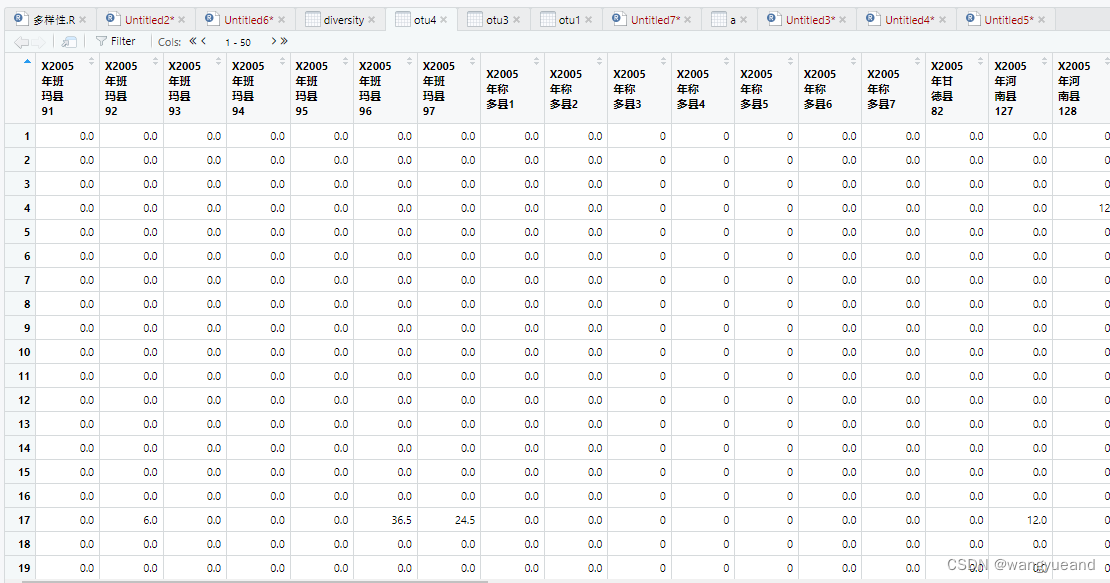
otu <- t(a)
otu1 <- as.data.frame(otu)
otu2 <- otu1
colnames(otu2)=otu1[1,]
otu3 <- otu2[-1,]
otu4 =as.data.frame(lapply(otu3,as.numeric))#将表格变为数字格式**
otu4
shannon <- diversity(otu4,index = “shannon”,MARGIN = 2,base = exp(1)) ## Shannon 多样性指数, MARGIN=1 计算行的多样性 index默认为“shannon”
simpson <- diversity(otu4,index = “simpson”,MARGIN = 2,base = exp(1)) ## Simpson多样性指数
SR <- specnumber(otu4,MARGIN = 2) ## 物种丰富度:相当于每一行大于0 (生物量、盖度或多度) 的物种数
Pielou <- shannon/log(SR) ##均匀度指数
diversity <- data.frame(shannon,simpson,SR,Pielou) ##将物种丰富度、Shannon多样性指数、Simpson多样性指数和Pielou’ 均匀度指数放置在一个数据框中
write_xlsx(diversity,“F:/论文/博士文章1/数据/8-diversity.xlsx”)

















 1419
1419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









