








前言
printf命令详解,格式化,awk格式化,printf动作
格式化
printf命令详解
printf命令的作用是按照我们指定的格式输出文本。
- echo 和printf区别
输出文本,echo命令也可以进行输出,它们的区别:
[root@node1 ~]# echo testString
testString
[root@node1 ~]# printf testString
testString[root@node1 ~]#
从上述示例中可以看出,在输出文本时,echo命令会对输出的文本进行换行,而printf命令则不会对输出的文本进行换行,使用转义符\n ,示例如下
[root@node1 ~]# printf "testString\n"
testString
printf的优势
在于格式化输出文本,假设,我们有一串文本需要输出,如下
[root@node1 ~]# echo "abc def ghi jkl"
abc def ghi jkl
有一个小需求,将上述文本按照空格分段,每段单独输出在一行
[root@node1 ~]# echo -e "abc \nabc \ndef \nghi \njkl"
abc
abc
def
ghi
jkl
对于printf,只是通过指定一个固定的"格式",后面的每一段文本都按照指定的格式进行了换行,即使有10000段文本需要换行,也不用担心。
[root@node1 ~]# printf "%s\n" abc def ghi jkl
abc
def
ghi
jkl
printf语法
printf命令的语法如下
printf "指定的格式" "文本1" "文本2" "文本3" ......
[root@node1 ~]# printf "%s\n" abc def ghi jkl
上述语法中的每一个"文本"都会被当做参数项传入printf命令,而每个被传入的参数都会按照指定的"格式"被"格式化"。
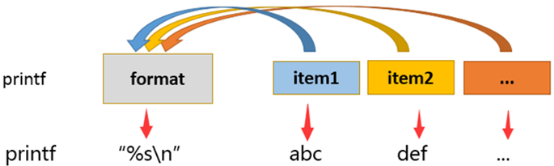
命令中的"%s\n"即为指定的"格式",而后面的每一段字符串,都被当做参数传入到了printf命令中,并按照我们指定的格式进行了格式化。
“%s"代替了命令的abc,代替了def,代替了ghi,代替了每一个传入的参数,在指定的"格式"中,它代表了每一个传入的参数,当指定格式为”%s\n",当abc被当做参数传入printf命令时,printf就会把"%s\n"中的%s替换成abc,于是,abc就变成了我们指定的格式"abc\n",最终printf输出的就是格式化后的"abc\n",以此类推,每一段文本都被当做一个参数传入printf命令,然后按照指定的格式输出了。
格式替换符
“格式替换符"不只有”%s"一种,“%s"代替了每一个传入的参数,并将他们转化成了"字符串类型”,“%f"会将每一个传入的参数转换成"浮点类型”,如下:
[root@node1 ~]# printf "%s \n" 1 19 18 222
1
19
18
222
[root@node1 ~]# printf "%f \n" 1 19 18 222
1.000000
19.000000
18.000000
222.000000
分别使用了"%s"替换符和"%f"替换符格式化了相同的内容,但是格式化后的结果却不同。
"%f"自动将传入的数字添加了小数点,将传入的数字参数替换成了浮点数。
可以根据传入参数的不同,使用不同的"格式替换符"去替换。
- 常用的格式替换符总结如下。
%s 字符串
%f 浮点格式(也就是我们概念中的float或者double)
%b 相对应的参数中包含转义字符时,可以使用此替换符进行替换,对应的转义字符会被转义。
%c ASCII字符。显示相对应参数的第一个字符
%d, %i 十进制整数
%o 不带正负号的八进制值
%u 不带正负号的十进制值
%x 不带正负号的十六进制值,使用a至f表示10至15
%X 不带正负号的十六进制值,使用A至F表示10至15
%% 表示"%"本身
转义符
说完了"格式替换符",再来说说"转义字符",刚才的示例中,只用到了"\n"这个转义符,还有很多其他的转义符,printf中的转义字符与其他程序中的转义字符没有什么不同,此处我们只是总结出来,方便大家使用。
- printf常用的转义符
| 转义符 | 含义 |
|---|---|
| \a | 警告字符,通常为ASCII的BEL字符 |
| \b | 后退 |
| \c | 抑制(不显示)输出结果中任何结尾的换行字符(只在%b格式指示符控制下的参数字符串中有效),而且,任何留在参数里的字符、任何接下来的参数以及任何留在格式字符串中的字符,都被忽略 |
| \f | 换页(formfeed) |
| \n | 换行 |
| \r | 回车(Carriage return) |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ | 一个字面上的反斜杠字符,即""本身。 |
| \ddd | 表示1到3位数八进制值的字符,仅在格式字符串中有效 |
| \0ddd | 表示1到3位的八进制值字符 |
示例
每个传入的参数添加一对"括号+空格",可以使用如下命令。
[root@node1 ~]# printf "( %s )" 1 19 28 222
( 1 )( 19 )( 28 )( 222 )[root@node1 ~]#
将每个传入的参数使用"制表符"隔开,可以使用如下命令。
[root@node1 ~]# printf "%s\t " 1 19 28 222
1 19 28 222 [root@node1 ~]#
设置多个"格式替换符"
所指定的"格式"中所包含的"格式替换符"的数量,就代表每次格式化的参数的数量,每个"格式替换符"与参数都是一一对应的,上图中,指定的"格式"中包含两个"格式替换符",那么printf每次进行"格式化"操作时,就会传入两个参数,然后前一个参数对应第一个替换符,后一个参数对应第二个替换符,当本次格式化操作完成以后,再传入下一波参数
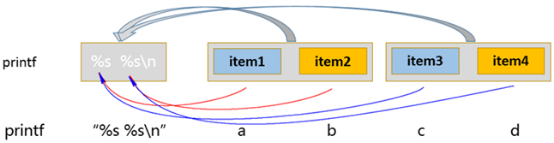
[root@node1 ~]# printf "%s %s\n" a b c d e f g
a b
c d
e f
g
[root@node1 ~]# printf "%s %s %s\n" a b c d e f g
a b c
d e f
g
修饰符
“数字” “+” “-”
- 数字指定输出宽度

"年龄"字段对应的数字都快跑到"性别"字段里面了,这个时候可以指定字段输出宽度

上图中第一个"%7s"中间的7表示当前替换符对应的输出宽度为7个字符宽,如果对应的输出不足7个字符,则用空格补全,如果输出的长度超过7个字符,超出的部分也会显示。同理"%5s"表示当前替换符对应的输出宽度为5个字符的宽度。而这些数字,其称之为"修饰符",修饰符会对相应的"替换符"进行修饰。
- 左对齐/右对齐

与之前的"格式"相比,只是在原来的修饰符前面加入了"-“,”-“表示左对齐,默认不加”-“时表示右对齐,其实”-"也是修饰符。
- +
除了数字和"-“,还有另一种修饰符,就是”+"
"+“不代表右对齐,表达含义示是"正数"前面的"正号”
[root@node1 ~]# printf "体温\n"; printf "%+3d\n" 10 -190
体温
+10
-190
- 小数点修饰符
当替换符为"%f"时,数字修饰符带有小数点,则数字修饰符小数点后的数字表示对应小数精度。
[root@node1 ~]# printf "体温\n"; printf "%+3f\n" 10.1234 -190.12323
体温
+10.123400
-190.123230
[root@node1 ~]# printf "体温\n"; printf "%+3.3f\n" 10.1234 -190.12323
体温
+10.123
-190.123
awk格式化
利用awk中的printf动作,即可对文本进行格式化输出,printf动作的用法与printf命令的用法相似
示例
[root@node1 awkdir]# awk '{print $1}' awktxt3
asdf
123
sdf
printf动作也都不会输出换行符,默认会将文本输出在一行里面。
[root@node1 awkdir]# awk '{printf $1}' awktxt3
asdf123sdf
使用"格式替换符"来指定一下$1的格式
[root@node1 awkdir]# awk '{printf "%s\n",$1}' awktxt3
asdf
123
sdf
注意事项
在awk中使用printf动作时,需要注意以下3点。
1)使用printf动作输出的文本不会换行,如果需要换行,可以在对应的"格式替换符"后加入"\n"进行转义。
2)使用printf动作时,"指定的格式" 与 "被格式化的文本" 之间,需要用"逗号"隔开。
3)使用printf动作时,"格式"中的"格式替换符"必须与 "被格式化的文本" 一一对应。
- “指定的格式” 与 “被格式化的文本” 之间,需要用"逗号"隔开。
[root@node1 awkdir]# awk '{printf "%s\n",$1}' awktxt3
asdf
123
sdf
[root@node1 awkdir]# printf "%s\n" awktxt3
awktxt3
- "格式"中的"格式替换符"必须与 “被格式化的文本” 一一对应
printf命令时,当指定的格式中只有一个"格式替换符",但是传入了多个参数时,那么这多个参数可以重复的使用这一个格式替换符
[root@node1 awkdir]# printf "%s\n" 1 2 3 4 5
1
2
3
4
5
但是在awk中,不能这样使用,在awk中,格式替换符的数量必须与传入的参数的数量相同,换句话说,格式替换符必须与需要格式化的参数一一对应
[root@node1 awkdir]# printf "%s\n" 1 2 3 4 5
1
2
3
4
5
[root@node1 awkdir]# awk 'BEGIN{printf "%s\n", 1,2,3,4,5}'
1
[root@node1 awkdir]# awk 'BEGIN{printf "%s\n%s\n%s\n%s\n%s\n", 1,2,3,4,5}'
1
2
3
4
5
示例
- 利用格式替换符对文本中的每一列进行格式化
[root@node1 awkdir]# cat awktxt3
asdf wer uoiou sdfl
123 ljk3 9xds
sdf 0knm 8hjlk
[root@node1 awkdir]# awk '{printf "第一列 :%s 第二列 :%s\n" , $1,$2 }' awktxt3
第一列 :asdf 第二列 :wer
第一列 :123 第二列 :ljk3
第一列 :sdf 第二列 :0knm
- 利用awk的内置变量FS,指定输入字段分隔符,然后再利用printf动作,进行格式化
awk本身负责文本切割,printf动作负责格式化文本
利用awk的begin模式,结合printf动作,输出一个像样的表格。
[root@node1 awkdir]# awk -v FS=":" 'BEGIN{printf "%-10s\t %s\n","用户名称","用户id"} {printf "%-10s\t %s\n" , $1,$3 }' /etc/passwd
总结
printf命令详解,格式化,awk格式化,printf动作
友情链接
| 目录 | 章节 |
|---|---|
| 版本说明 | 版本说明 |
| 安装MySQL规范 | 1 安装方式 2 安装用户 3 目录规范 |
| MySQL 5.7 安装部署 | 1 操作系统配置 2 创建用户 3 创建目录 4 安装 5 配置文件 6 安装依赖包 7 配置环境变量 8 初始化数据库 9 重置密码 |
| MySQL8 安装 | MySQL8 安装 |
| 源码安装 | 1 安装依赖包 2 生成源码包 3 创建用户 4 编译安装 5 配置数据库 6 连接mysql |
| 多实例部署及注意事项 | 1 多实例概念 2 多实例安装 3 mysqld_multi(多实例第二种安装方式) |
| 目录 | 章节 |
|---|---|
| 生产中MySQL启动方式 | 1、 启动原理 2、参数文件默认位置及优先级 3、 以server方式启动 4、 mysqld_safe方式 5、 mysqld 方式 6、 systemctl 方式 |
| 关库 | 1、相关参数innodb_fast_shutdown 2、相关参数innodb_force_recovery 3、关闭mysql多种方式 |
| 常见MySQL启动失败案例 | 1.、目录权限 2、参数问题 3、配置文件 4、端口占用 5、误删二进制文件 6、undo表空间异常 7、binlog缓冲异常 |
| MySQL启动失败排查方法 | MySQL启动失败排查方法 |
| 连接MySQL数据库的方式 | 连接MySQL数据库的方式 |
| MySQL数据库用户安全策略 | 1、初始化数据库 2、修改密码 3、删除无用的用户 4、mysql_secure_installation |
| 找回丢失的用户密码 | 找回丢失的用户密码 |
| 目录 | 章节 |
|---|---|
| MySQL字符集和校验规则 | MySQL字符集和校验规则 |
| 查看字符集方法 | 1、查看mysql支持的字符集 2、查看字符集的校对规则 3、查看当前数据库的字符集 4、查看当前数据库的校对规则 |
| MySQL字符集设置 | 1、字符集设置层级关系 2、设置MySQL服务器级别字符集 3、设置创建对象的字符集 |
| 字符集案例 | 1、常用字符集每个汉字占用字节多少 2、大小案例 |
| 插入中文乱码解决 | 插入中文乱码解决 |
| 数据库常见字符集及如何选择字符集 | 数据库常见字符集及如何选择字符集 |
| 生产中如何彻底避免出现乱码 | 生产中如何彻底避免出现乱码 |
| 目录 | 章节 |
|---|---|
| 访问控制 | 1、连接验证(阶段一) 2、允许的连接 3、连接优先级 4、请求验证(阶段二) |
| 用户管理 | 1、新增用户 2、修改用户 3、删除用户 4、查看用户 |
| 密码管理 | 1、密码修改 2、密码过期设置 3、set password 4、密码过期策略 5、密码插件 |
| MySQL用户权限管理 | 1、权限粒度 2、显示账户权限 3、显示账户非权限属性 4、库级权限 5、表级权限 6、列级权限 7、权限回收 |
| 资源限制 | 1、用户创建指定配额 2、修改配额 |
| MySQL用户权限案例 | 1、断掉已清理的用户 2、忘记密码 3、如何禁止一个ip段的某个用户登录 4、创建开发账号 5、创建复制账号 6、创建管理员账号 |
| 目录 | 章节 |
|---|---|
| 缓冲池 | 1、默认引擎 2、设置缓冲池大小 3、优化缓冲池 4、管理缓冲池 5、数据页类型 |
| 线程 | 1、IO线程 2、主线程 |
| index page | index page |
| insert buffer page | insert buffer page |
| 重做日志 | 重做日志 |
| 回滚日志 | 回滚日志 |
| checkpoint,刷写脏页check point | checkpoint |
| 关键特性 | 1、插入缓冲 2、数据写入可靠性提升技术-doublewrite 3、自适应哈希索引-AHI |
| innodb预读预写技术 | 预读写 |
| 目录 | 章节 |
|---|---|
| 参数和配置文件 | 1、文件位置 2、查找参数 3、参数类型 4、参数修改 5、示例一 6、示例二 7、注意事项 |
| 错误日志文件 | 错误日志 |
| 通用日志 | 通用日志 |
| 慢查询日志 | 慢日志 |
| binlog | 1、记录什么 2、用途 3、开启和参数配置 4、日志查看 5、日志刷新 6、删除日志 7、日志分析(mysqlbinlog) 8、利用二进制日志文件恢复误删的表 |
| InnoDB存储引擎表空间文件 | 表空间文件 |
| 主从同步相关文件 | 主从同步文件 |
| 套接字文件 | 套接字文件 |
| pid 文件 | pid 文件 |
| redo log | 1、redo初识 2、日志组 3、与oracle redo的区别 4、相关参数 5、和binlog的区别 6、redo 缓冲区(innodb_flush_log_at_trx_commit) |
| InnoDB存储引擎逻辑结构 | 1、表空间 2、段 3、区 4、页 |
| 表碎片清理 | 1、判断是否有碎片 2、整理碎片 |
| 表空间文件迁移 | 1、需求 2、操作 |
| 目录 | 章节 |
|---|---|
| 常用语句 | 1、导入数据 2、库操作 3、表操作 4、数据操作 5、use性能影响 6、delete、truncate、drop的区别 7、SQL语句分类 |
| 数据类型与性能 | 1、整型 2、浮点型 3、字符串类型 4、日期类型 |
| MySQL约束 | 1、unsigned/signed 2、not null 3、count(*) 为什么慢 4、default 5、unique 6、 auto_increment 7、primary key |
| SQL编程高级 | 1、查询Syntax 2、查询列 3、where子句 4、group by … having子句 5、order by子句 6、limit子句(分页) 7、聚合函数 8、合并查询 9、多表查询 10、子查询 |
| 表的元数据库管理 | 1、统计应用库哪些表没有使用innodb存储引擎 2、如何查看表中是否有大对象 3、统计数据库大小 4、统计表的大小 |
| 目录 | 章节 |
|---|---|
| MySQL索引与二分查找法 | 1、什么是索引 2、索引的优缺点 3、索引的最大长度 4、二分查找法:折半查找法 5、mysql一张表存多少数据后,索引性能就会下降? |
| 剖析b+tree数据结构 | 1、B和B+树的区别 2、索引树高度 3、非叶子节点 4、指针 5、叶子节点 6、双向指针 7、b+tree插入操作 8、b+tree删除操作 |
| 相辅相成的聚集索引和辅助索引 | 1、聚集索引 2、聚集索引特点 3、聚集索引的优势 4、辅助索引 |
| 覆盖索引与回表查询 | 1、回表查询 2、覆盖索引 |
| 创建高性能的主键索引 | 1、主键索引创建的原则 2、主键索引的特点 3、为什么建议使用自增列作为主键 |
| 唯一索引与普通索引的性能差距 | 1、唯一索引特点 2、普通索引特点 3、唯一索引与普通索引的性能差距 |
| 前缀索引带来的性能影响 | 1、作用 2、坏处 |
| 如何使用联合索引 | 1、什么是联合索引 2、创建原则 3、排序 |
| Online DDL影响数据库的性能和并发 | 1、5.6版本之前 2、新版本 3、online ddl语法 4、相关参数 5、示例 6、影响 |
| pt-ocs原理与应用 | 1、安装pt-osc 2、pt-osc语法 3、案例 4、pt-osc原理 |
| 生产中索引的管理 | 1、建表时创建索引 2、建表后创建索引 3、查看索引 |
| SQL语句无法使用索引的情况 | 1、where条件 2、联合索引 3、联表查询 4、其他情况 |
| 目录 | 章节 |
|---|---|
| 最常用的STATISTICS和TABLES | 1、STATISTICS:用于存放索引的信息 2、TABLES:用于存放库表的元数据信息 |
| 判断索引创建是否合理 | 1、选择性 2、索引创建的建议 |
| 检查联合索引创建是否合理 | 1、联合索引创建是否合理 2、有了联合索引(a,b),还需要单独创建a索引吗? |
| 如何查找冗余索引 | 查找冗余索引 |
| 查找产生额外排序的sql语句 | 额外排序的sql语句 |
| 查找产生临时表的sql语句 | 临时表的sql语句 |
| 全表扫描的sql语句 | 全表扫描的sql语句 |
| 统计无用的索引 | 无用的索引 |
| 索引统计信息 | 1、存储索引统计信息 2、如何查看索引统计信息 |
| 目录 | 章节 |
|---|---|
| 简单嵌套查询算法-simple nested-loop join | simple nested-loop join |
| 基于索引的嵌套查询算法-index nested-loop join | index nested-loop join |
| 基于块的嵌套查询算法- block nested-loop join | block nested-loop join |
| Multi-Range Read | MRR |
| bached key access join | BKA |
| mysql三层体系结构 | 体系结构 |
| Index Condition Pushdown | 索引条件下推 |
| 一条查询SQL语句是怎样运行的 | 查询SQL语句 |
| 一条更新SQL语句是怎样运行的 | 更新SQL语句 |
| MySQL长连接与短连接的选择 | 1、相关参数 2、断开连接 |
| 执行计划explain | 1、语法 2、执行计划解析 |
| 目录 | 章节 |
|---|---|
| MySQL查询优化技术 | 概览 |
| 子查询优化 | 1、优化器自动优化 2、优化措施:子查询合并 3、优化措施:子查询上拉技术 |
| 外连接消除 | 外连接消除 |
| 生产环境不使用join联表查询 | 不使用join |
| group by分组优化 | 1、group by执行流程 2、为什么group by要创建临时表 |
| order by排序优化 | 排序优化 |
| MySQL性能抖动问题 | 性能抖动问题 |
| count(*)优化 | count(*)优化 |
| 磁盘性能基准测试 | 1、安装sysbench 2、生成文件 3、测试文件io 4、清除文件 |
| MySQL基准测试 | 1、生成数据 2、测试(读) 3、测试(写) 4、清理数据 |
| 目录 | 章节 |
|---|---|
| 认识事务 | 认识事务 |
| 事务控制语句 | 1、开启事务 2、事务提交 3、事务回滚 |
| 事务的实现方式 | 1、原子性 2、一致性 3、隔离性 4、持久性 |
| purge thread线程 | purge thread线程 |
| 事务统计QPS与TPS | 1、QPS 2、TPS |
| 事务隔离级别 | 1、隔离级别 2、查看隔离级别 3、设置隔离级别 4、不同隔离级别下会产生什么隔离效果 |
| 事务组提交group commit | 组提交 |
| 事务两阶段提交 | 两阶段提交 |
| MVCC多版本并发控制 | 1、MVCC原理 2、MVCC案例 |
| 目录 | 章节 |
|---|---|
| 认识锁 | 1、锁的作用 2、加锁的过程 3、锁对象:事务 |
| innodb行锁 | 1、行锁类型 2、共享锁(S锁) 3、排他锁(X锁) |
| 索引对行锁粒度的影响 | 1、行锁粒度有哪些 2、在RC隔离级别下不同索引产生的锁的范围 3、RR隔离级别下不同索引产生锁的范围 |
| FTWRL全局读锁 | FTWRL全局读锁 |
| innodb表锁 | innodb表锁 |
| innodb意向锁与MDL锁 | 1、意向锁 2、意向锁作用 3、意向锁冲突情况 4、MDL锁 |
| 自增锁 | 自增锁 |
| 插入意向锁 | 插入意向锁 |
| 死锁 | 1、什么是死锁 2、相关参数 3、避免死锁 4、锁的状态 |
| 两阶段锁协议 | 两阶段锁协议 |
| 目录 | 章节 |
|---|---|
| 1. 系统状态 | show status |
| 2. 慢查询 | 2.1 慢查询开启 2.2 简单示例 2.3 数据准备 |
| 3. mysqldumpslow | 3.1 语法 3.2 常见用法 |
| 4. pt-query-digest | 4.1 安装 4.2 语法选项 4.3 报告解读 4.4 用法示例 |
| 5. 优化工具(soar) | 5.1 安装配置 5.2 添加数据库 5.3 语句优化 |
15、备份恢复原理和实战_逻辑备份_物理备份_金融行业备份还原脚本
| 目录 | 章节 |
|---|---|
| 1.生产中备份方式 | 1.1 物理备份与逻辑备份 1.2 联机与脱机备份 1.3 完整备份与增量备份 1.4 常用命令 |
| 2.mysqldump备份 | 2.1 相关参数 2.2 备份所有数据库 2.3 备份指定数据库 2.4 备份指定表 2.6 只导出结构 2.7 只导出数据 2.8 --tab(生成文本,类似load) 2.8 mysqldump原理 2.9 binlog异步备份 2.10 利用mysqldump全备及binlog恢复数据 |
| 3.xtrabackup | 3.1 Xtrabackup安装 3.2 原理 3.2 备份过程 3.4 恢复原理 3.3 相关参数 3.4 xtrabackup相关文件 3.5 备份示例 3.6 还原示例 |
| 4.binlog备份和恢复(数据库恢复) | 4.1 找到恢复时间点 4.2 增量恢复 |
| 5. 生产环境的备份恢复实战 | 5.1 实施部署 5.1.1 环境清单 5.1.2 备份目的 5.1.3 备份说明 5.1.4 实施步骤 5.1.5 全备脚本 5.1.6 差异备份脚本 5.2 实施部署备份还原 5.2.1 Xtraback还原全量/差异备份 5.2.2 故障点数据恢复 5.2.3 增量恢复 |
16、主从复制,gtid,并行复制_半同步复制_实操案例_常用命令_故障处理
| 目录 | 章节 |
|---|---|
| 1.认识主从复制 | 1.1 主从复制原理深入讲解 1.2 主从复制相关参数 1.3.主从复制架构部署 1.4从库状态详解 1.5 .过滤复制 |
| 2 .gtid复制 | 2.1 什么是GTID? 2.2 GTID主从配置 2.5 gtid维护 2.4 GTID的特点 2.3 工作原理 2.4 gtid相关状态行和变量 |
| 3. 并行复制 | 3.1 延迟的原因 3.2 并行复制设置 3.3 查看并行复制 |
| 4. 增强半同步复制 | 4.1 异步复制 4.2 半同步复制 4.3 增强半同步复制 4.4 配置增强半同步 |
| 5. 案例 | 5.1 主库删除操作导致sql线程关闭案例 5.2 主从复制中断解决方案及案例 5.3 延迟复制 5.4 主库drop误操作利用延迟复制恢复案例 |
| 6 常用命令 | 6.1 启动线程 6.2 关闭线程 6.3 查看 6.4 重置 6.5 主从数据一致性校验 |
| 目录 | 章节 |
|---|---|
| MHA | 介绍 |
| 架构和相关组件 | 架构和相关组件 |
| 工作流程 | 工作流程 |
| MHA高可用架构部署 | 1、环境准备 2、软件安装 3、创建软链接 4、配置各节点互信 5、节点免密验证 6、mha管理用户 7、配置文件 8、状态检查 9、开启MHA |
| 主库宕机故障模拟及处理 | 主库宕机故障模拟及处理 |
| MHA VIP自动切换 | VIP自动切换 |
| MHA主从数据自动补足 | MHA主从数据自动补足 |
| 目录 | 章节 |
|---|---|
| Atlas读写分离高性能架构 | 介绍 |
| 安装配置 | 安装配置 |
| 配置注解 | 配置注解 |
| 启动和关闭 | 启动和关闭 |
| 读写分离架构应用 | 读写分离架构应用 |
| 创建应用用户 | 创建应用用户 |
| Atlas在线管理 | Atlas在线管理 |
| 读写分离避坑指南 | 读写分离避坑指南 |
| 目录 | 章节 |
|---|---|
| 1.MyCAT分布式架构入门及双主架构 | 1.1 主从架构 1.2 MyCAT安装 1.3 启动和连接 1.4 配置文件介绍 |
| 2.MyCAT读写分离架构 | 2.1 架构说明 2.2 创建用户 2.3 schema.xml 2.4 连接说明 2.5 读写测试 2.6 当前是单节点 |
| 3.MyCAT高可用读写分离架构 | 3.1 架构说明 3.3 schema.xml(配置) 3.4 文件详解 3.4.1 schema标签 3.4.2 table标签 3.4.3 dataNode标签 3.4.4 dataHost 3.4 读写测试 3.5 故障转移 |
| 4.MyCAT垂直分表 | 4.1 架构 4.2 新建表 4.3 配置mycat 4.4 验证 |
| 5 MyCAT水平分表-范围分片 | 5.1 新建表 5.2 schema.xml 5.2 rule.xml 5.3 autopartition-long.txt 5.4 验证 |
| 6. MyCAT水平分表-取模分片 | 取模分片 |
| 7. MyCAT水平分表-枚举分片 | 枚举分片 |
| 8. MyCAT全局表与ER表 | 全局与ER表 |
| 8.1 全局表 | 8.1.1 特性 8.1.2 建表 8.1.3 配置 8.1.4 验证 8.1.5 分析总结(执行计划) |
| 8.2 ER表 | 8.2.1 特性 8.2.2 建表 8.2.3 配置 8.2.4 测试验证,子表是否跟随父表记录分片 8.2.5 分析总结(执行计划) |
| 目录 | 章节 |
|---|---|
| 1. sysbench | 1.1 用途 1.2 安装 1.3 版本 1.4 查看帮助 1.5 测试过程阶段 |
| 2 CPU 性能测试 | 2.1 测试原理 2.2 查看帮助 2.3 测试 |
| 3. 内存性能测试 | 3.1 查看帮助信息 3.2 测试过程 |
| 4.磁盘性能基准测试 | 4.1 查看帮助 4.2 生成文件(prepare) 4.3 测试文件io(run) 4.4 结果分析 4.5 清除文件(cleanup) |
| 5. 线程测试 | 5.1 查看帮助信息 5.2 测试过程 |
| 6. MySQL基准测试 | 6.1 语法参数 6.2 生成数据 6.3 测试(读) 6.4 测试(写) 6.5 清理数据 |



















 4489
4489

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











