







执行计划的查看
使用EXPLAIN/DESC查看执行计划
insert into trips(client_id,driver_id,city_id,status,request_at) select client_id,driver_id,city_id,status,request_at from trips
mysql> explain select count(*) from Trips where request_at BETWEEN '2011-01-01' and '2032-01-01';
+------------------------------+----------+-----------+---------------+--------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+------------------------------+----------+-----------+---------------+--------------------------------------------------------------------------------------------------------------+
| StreamAgg_20 | 1.00 | root | | funcs:count(Column#9)->Column#7 |
| └─TableReader_21 | 1.00 | root | | data:StreamAgg_9 |
| └─StreamAgg_9 | 1.00 | cop[tikv] | | funcs:count(1)->Column#9 |
| └─Selection_19 | 40960.00 | cop[tikv] | | ge(test.trips.request_at, 2011-01-01 00:00:00.000000), le(test.trips.request_at, 2032-01-01 00:00:00.000000) |
| └─TableFullScan_18 | 40960.00 | cop[tikv] | table:Trips | keep order:false |
+------------------------------+----------+-----------+---------------+--------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
EXPLAIN 的输出
- id: 算子的ID。是算子在整个执行计划中唯一的标识,从上到下,从右至左
- estRows: 估算返回的行数,算子语句将会输出的数据条数
- task: 算子的种类
- root: TiDB执行的
- cop[tikv]: 下推到tikv上执行的
- access object: 访问的对象,例如索引或者表或者分区
- operator info : 算子详细信息
EXPLAIN ANALYZE的输出
EXPLAIN ANALYZE 会执行对应的SQL语句,记录其运行的信息,并且和执行计划一起返回。并且它会多少消耗内存和磁盘的信息
- memory : 算子占用内存空间的阿晓
- disk : 占用磁盘空间的大小
mysql> explain analyze select count(*) from Trips where request_at BETWEEN '2011-01-01' and '2032-01-01';
+------------------------------+----------+---------+-----------+---------------+-------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+-----------+------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+------------------------------+----------+---------+-----------+---------------+-------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+-----------+------+
| StreamAgg_20 | 1.00 | 1 | root | | time:790.6µs, loops:2 | funcs:count(Column#9)->Column#7 | 388 Bytes | N/A |
| └─TableReader_21 | 1.00 | 1 | root | | time:784.5µs, loops:2, cop_task: {num: 1, max: 693.6µs, proc_keys: 0, rpc_num: 1, rpc_time: 663.4µs, copr_cache_hit_ratio: 1.00} | data:StreamAgg_9 | 221 Bytes | N/A |
| └─StreamAgg_9 | 1.00 | 1 | cop[tikv] | | tikv_task:{time:31ms, loops:41} | funcs:count(1)->Column#9 | N/A | N/A |
| └─Selection_19 | 40960.00 | 40960 | cop[tikv] | | tikv_task:{time:31ms, loops:41} | ge(test.trips.request_at, 2011-01-01 00:00:00.000000), le(test.trips.request_at, 2032-01-01 00:00:00.000000) | N/A | N/A |
| └─TableFullScan_18 | 40960.00 | 40960 | cop[tikv] | table:Trips | tikv_task:{time:27ms, loops:41} | keep order:false | N/A | N/A |
+------------------------------+----------+---------+-----------+---------------+-------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+-----------+------+
5 rows in set (0.00 sec)
顺序查看
id的顺序顺序查看技巧:由上至下,从右向左,并列的上边先执行。
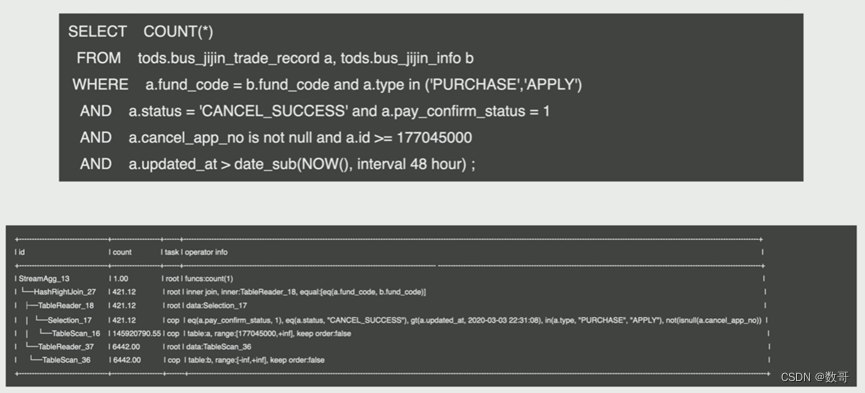
18和37 是并列, 向上的先执行 16-》17-》18-》36-》37-》27-》13
管理执行计划
优化器 Hint
- 通过/*+ … */ 注释的行为跟在select、update、或delete后面
- Hint 不区分大小写
- 多个不同的Hint需要使用逗号隔开

绑定执行计划(SPM)
- 创建绑定
create binding for -- 创建绑定的关键字
select * from t where a> 1 ---被绑定的SQL语句
using
select * from t use index(idx) where a > 2; ---期望替换的带有hint的语句
- 查看绑定
show [global|session] bindings --查看绑定的关键字
select * from t where a > 1 --被绑定的SQL
- 删除绑定
drop[global|session] binding --删除绑定的关键字
select * from t where a > 1 --被绑定的SQL
执行计划中的算子
- 执行计划中的算子
- 汇聚数据类算子
- hash aggregate
- stream aggregate
- 扫描数据类算子
- Point Get/Batch Point Get
- Table Reader
- Index Reader
- Index Lookup Reader
- Index Merge Reader
- 表连接类算子
- Hash Join算子
- Merge Join 算子
- Index Join 算子
- 汇聚数据类算子
汇聚类算子 - Hash Aggregate
- 阻塞时执行,需要整个计算完成才可以对上层算子输出结果
- 不需要提前排序
- 支持并行
- 内存占用较大
- Hash Aggregate 示例
mysql> explain select /*+ hash_agg() */ count(*) from planets;
+---------------------------+---------+-----------+---------------------------------+-----------------------------------+
| id | estRows | task | access object | operator info |
+---------------------------+---------+-----------+---------------------------------+-----------------------------------+
| HashAgg_10 | 1.00 | root | | funcs:count(Column#27)->Column#25 |
| └─IndexReader_11 | 1.00 | root | | index:HashAgg_5 |
| └─HashAgg_5 | 1.00 | cop[tikv] | | funcs:count(1)->Column#27 |
| └─IndexFullScan_9 | 10.00 | cop[tikv] | table:planets, index:name(name) | keep order:false, stats:pseudo |
+---------------------------+---------+-----------+---------------------------------+-----------------------------------+
4 rows in set (0.00 sec)
-
Hash Aggregate工作流程
例如将部门映射成一张hash表,通过hash函数取得对应相同值,进行分析



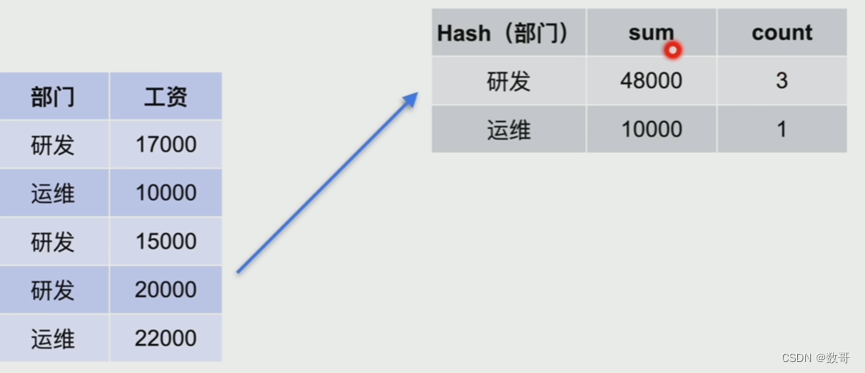
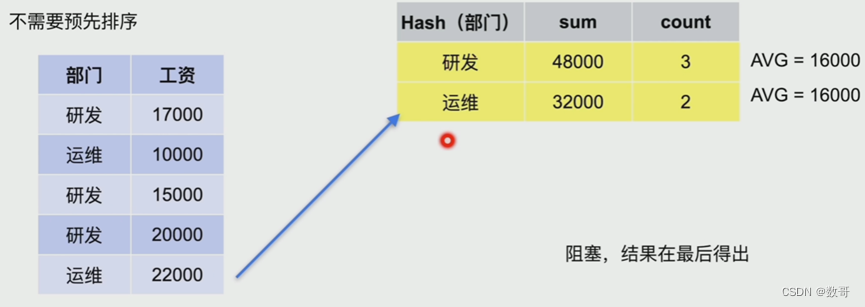
优点: 不需要预先排序,因为它是通过hash函数取得对应的值 然后进行统计分析
缺点: 如果只有一个线程处理,后面的内容需要一行一行的处理,会造成阻塞,结果在最后得出 -
优化措施
优化措施,它会分多个线程,对hash值进行聚合

实际是两张临时表 来扫描两个区域,如果有N个线程,那就N张临时表



汇聚类算子 - Stream Aggregate
- 非阻塞式执行,对于类似limit操作友好
- 内存占用小
- 单线程执行
- Stream Aggregate 示例
mysql> explain select /*+ stream_agg() */ count(*) from planets;
+----------------------------+---------+-----------+---------------------------------+-----------------------------------+
| id | estRows | task | access object | operator info |
+----------------------------+---------+-----------+---------------------------------+-----------------------------------+
| StreamAgg_15 | 1.00 | root | | funcs:count(Column#27)->Column#25 |
| └─IndexReader_16 | 1.00 | root | | index:StreamAgg_8 |
| └─StreamAgg_8 | 1.00 | cop[tikv] | | funcs:count(1)->Column#27 |
| └─IndexFullScan_14 | 10.00 | cop[tikv] | table:planets, index:name(name) | keep order:false, stats:pseudo |
+----------------------------+---------+-----------+---------------------------------+-----------------------------------+
4 rows in set (0.00 sec)
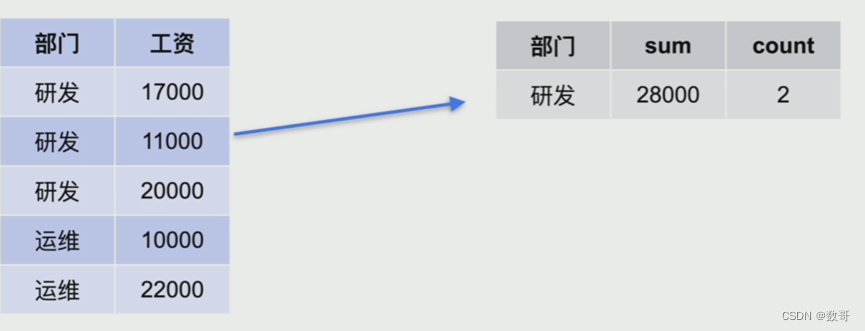
- Stream Aggregate工作流程
先排序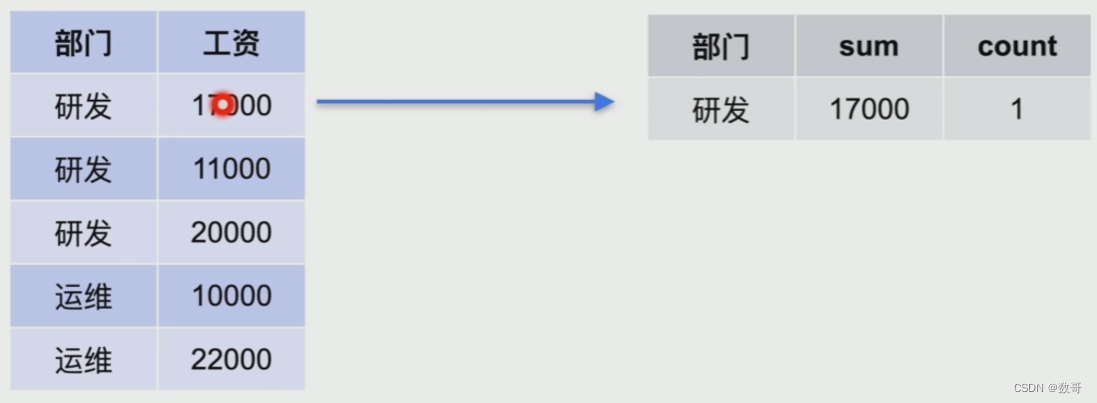
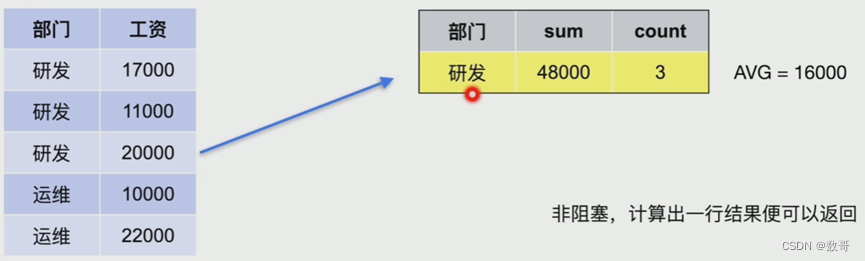
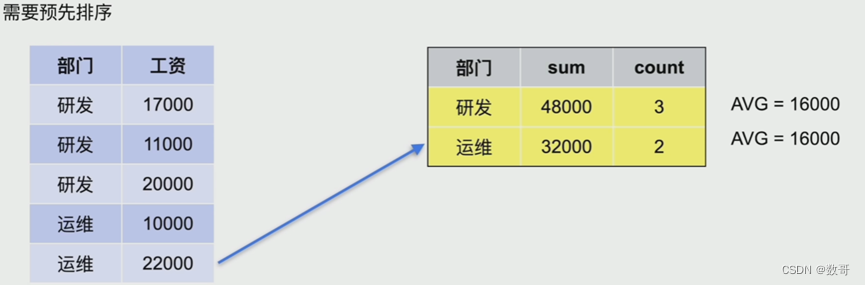
优点:非阻塞,计算出一行结果便可以返回
缺点: 需要预先排序
扫描类算子-PointGet
- 示例
mysql> explain select * from planets where id = 2;
+-------------+---------+------+---------------+---------------+
| id | estRows | task | access object | operator info |
+-------------+---------+------+---------------+---------------+
| Point_Get_1 | 1.00 | root | table:planets | handle:2 |
+-------------+---------+------+---------------+---------------+
1 row in set (0.00 sec)
mysql> explain select * from planets where id in (2,3,4,5);
+-------------------+---------+------+---------------+------------------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------+---------+------+---------------+------------------------------------------------+
| Batch_Point_Get_1 | 4.00 | root | table:planets | handle:[2 3 4 5], keep order:false, desc:false |
+-------------------+---------+------+---------------+------------------------------------------------+
1 row in set (0.00 sec)
扫描类算子-indexReader
indexReader:不用回表,从索引上取得数据
mysql> explain select count(*) from planets ;
+----------------------------+---------+-----------+---------------------------------+-----------------------------------+
| id | estRows | task | access object | operator info |
+----------------------------+---------+-----------+---------------------------------+-----------------------------------+
| StreamAgg_20 | 1.00 | root | | funcs:count(Column#30)->Column#25 |
| └─IndexReader_21 | 1.00 | root | | index:StreamAgg_8 |
| └─StreamAgg_8 | 1.00 | cop[tikv] | | funcs:count(1)->Column#30 |
| └─IndexFullScan_19 | 10.00 | cop[tikv] | table:planets, index:name(name) | keep order:false, stats:pseudo |
+----------------------------+---------+-----------+---------------------------------+-----------------------------------+
4 rows in set (0.01 sec)
扫描类算子-indexLookup
index lookup: 走索引,但要回表
mysql> explain select * from planets use index (name);
+-------------------------------+---------+-----------+---------------------------------+--------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------------+---------+-----------+---------------------------------+--------------------------------+
| IndexLookUp_6 | 10.00 | root | | |
| ├─IndexFullScan_4(Build) | 10.00 | cop[tikv] | table:planets, index:name(name) | keep order:false, stats:pseudo |
| └─TableRowIDScan_5(Probe) | 10.00 | cop[tikv] | table:planets | keep order:false, stats:pseudo |
+-------------------------------+---------+-----------+---------------------------------+--------------------------------+
3 rows in set (0.00 sec)
扫描类算子-TableReader
没有索引,或者索引不合适,直接走表的数据
mysql> explain select * from planets where mass>0.1;
+-------------------------+---------+-----------+---------------+--------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------+---------+-----------+---------------+--------------------------------+
| TableReader_7 | 3.33 | root | | data:Selection_6 |
| └─Selection_6 | 3.33 | cop[tikv] | | gt(universe.planets.mass, 0.1) |
| └─TableFullScan_5 | 10.00 | cop[tikv] | table:planets | keep order:false, stats:pseudo |
+-------------------------+---------+-----------+---------------+--------------------------------+
3 rows in set (0.00 sec)
扫描类算子-IndexMerge
当谓词条件中上有多个索引进行数据合并操作的时候
mysql> set @@tidb_enable_index_merge=1;
Query OK, 0 rows affected (0.00 sec)
mysql> explain select * from t use index(idx_a,idx_b) where a>1 or b>1;

表连接类算子-HashJoin
hash join 通常对 没有索引,并且是等值查询
- 示例
mysql> explain select /*+ hash_join(planets,stars) */ planets.mass from planets,stars where planets.sun_iid=stars.id ;
+-----------------------------+---------+-----------+-------------------------------+--------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+---------+-----------+-------------------------------+--------------------------------------------------------------------+
| HashJoin_16 | 2.50 | root | | inner join, equal:[eq(universe.planets.sun_id, universe.stars.id)] |
| ├─IndexReader_23(Build) | 2.00 | root | | index:IndexFullScan_22 |
| │ └─IndexFullScan_22 | 2.00 | cop[tikv] | table:stars, index:name(name) | keep order:false, stats:pseudo |
| └─TableReader_19(Probe) | 10.00 | root | | data:TableFullScan_18 |
| └─TableFullScan_18 | 10.00 | cop[tikv] | table:planets | keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+-------------------------------+--------------------------------------------------------------------+
5 rows in set (0.00 sec)
-
原理
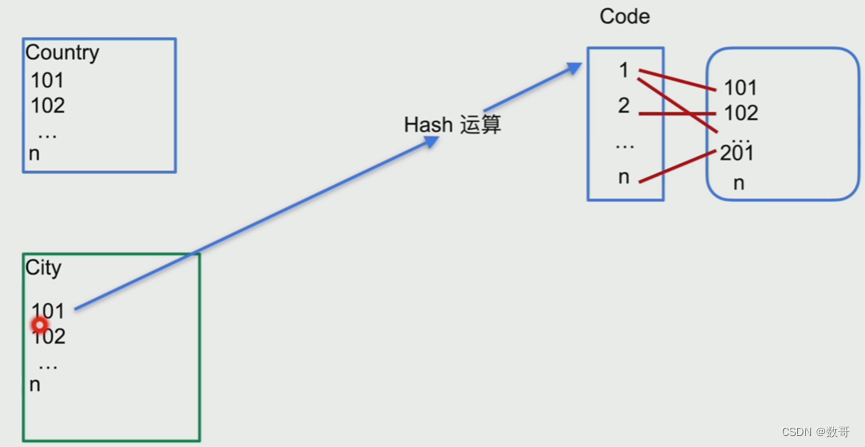
两张表:country city
假设通过对外表/小表/驱动表进行hash运算例如求模100建立一张hash表
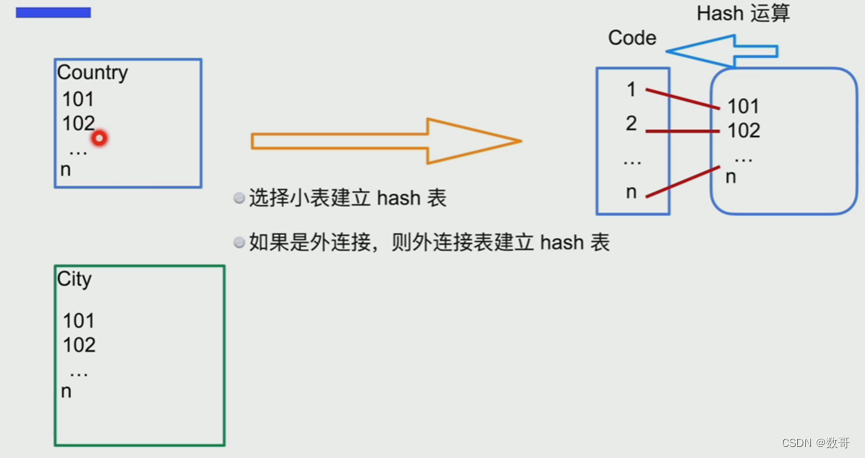
内表在匹配的的时候,例如101这条记录通过求模得到1,匹配hash表当中的2行记录,这个时候只需要扫描2次即可。
-
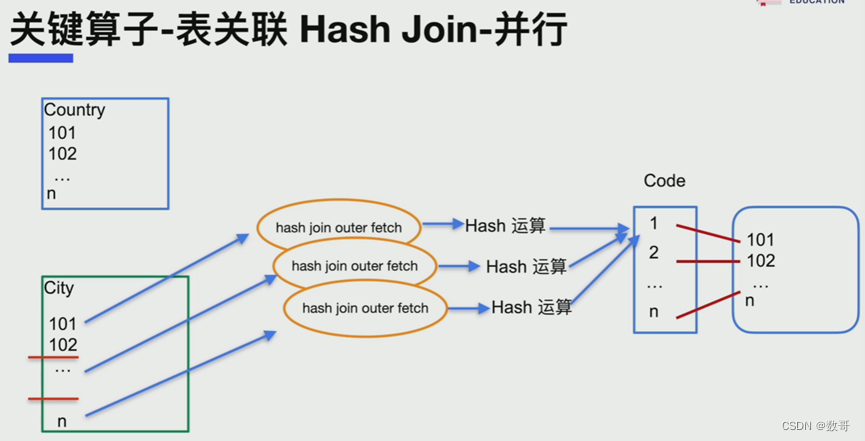
优化措施:并行
将city分成几个区块,然后多个线程并行处理
表连接类算子-Merge Join
-
示例
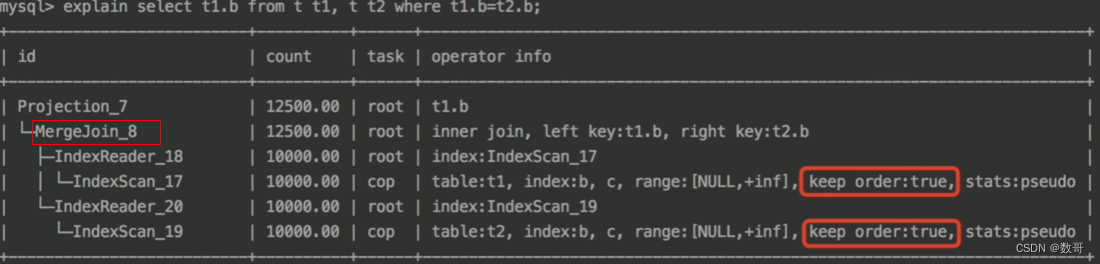
注意:operator info中可以查查看到排序的动作。 -
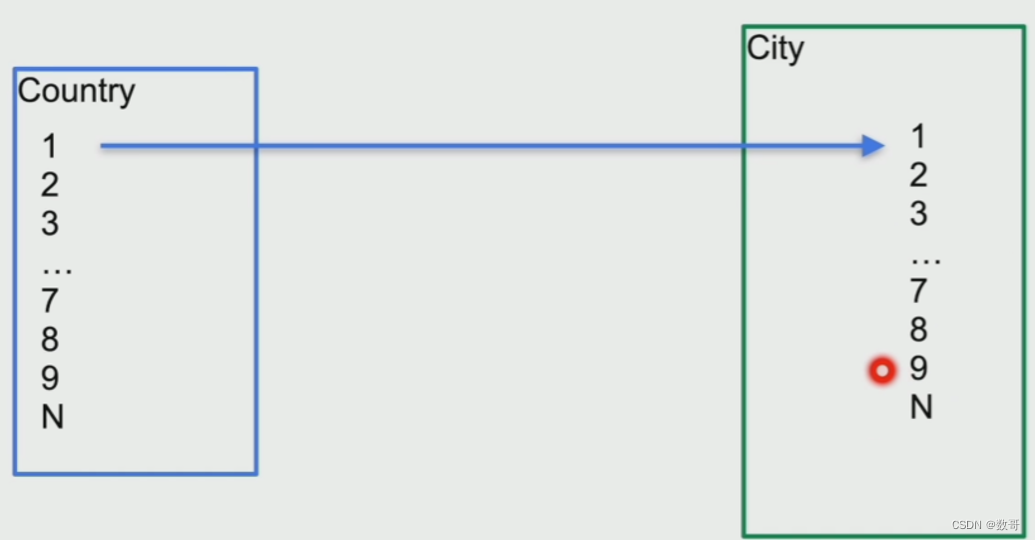
原理
国家和城市两张表
这种算法下,会先进行排序

匹配的时候,因为数据经过排序,一旦匹配到,后续的数据就不需要在扫描匹配了。它的效率不如hashJoin,但比它节约内存
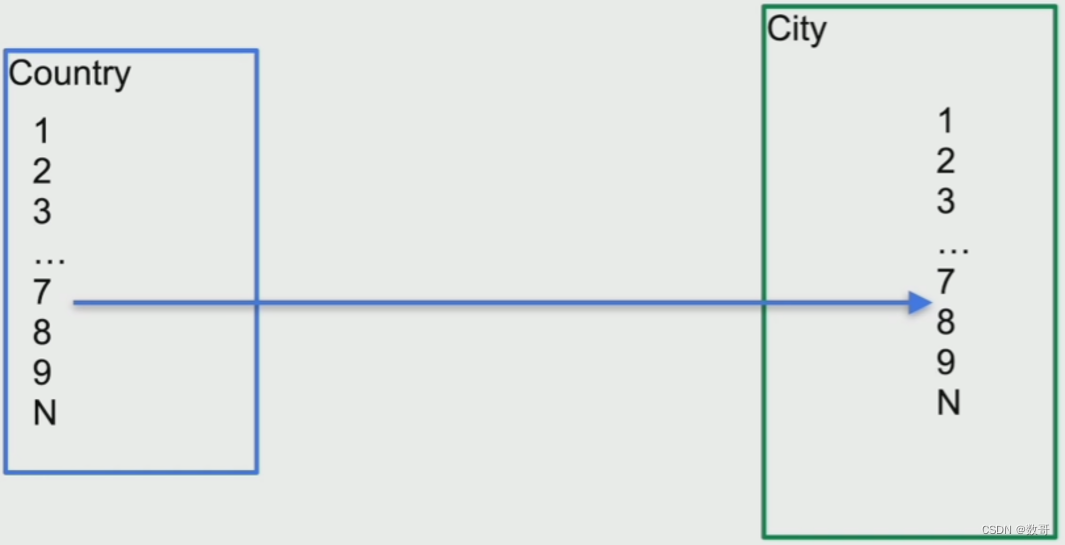
表连接类算子-Index Join
- 示例
mysql> explain select /*+ inl_join(planets,stars) */ planets.name,stars.name from planets,stars where planets.sun_id=stars.id;
+-----------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+
| IndexJoin_11 | 2.50 | root | | inner join, inner:TableReader_8, outer key:universe.planets.sun_id, inner key:universe.stars.id, equal cond:eq(universe.planets.sun_id, universe.stars.id) |
| ├─TableReader_17(Build) | 10.00 | root | | data:TableFullScan_16 |
| │ └─TableFullScan_16 | 10.00 | cop[tikv] | table:planets | keep order:false, stats:pseudo |
| └─TableReader_8(Probe) | 0.25 | root | | data:TableRangeScan_7 |
| └─TableRangeScan_7 | 0.25 | cop[tikv] | table:stars | range: decided by [universe.planets.sun_id], keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
表连接类算子-IndexHashJoin
相较于hash join 不同的地方是,非驱动表 替换成了索引
mysql> explain select /*+ inl_hash_join(planets,stars) */ planets.name,stars.name from planets,stars where planets.sun_id=stars.id;
+-----------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-----------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+
| IndexHashJoin_13 | 2.50 | root | | inner join, inner:TableReader_8, outer key:universe.planets.sun_id, inner key:universe.stars.id, equal cond:eq(universe.planets.sun_id, universe.stars.id) |
| ├─TableReader_17(Build) | 10.00 | root | | data:TableFullScan_16 |
| │ └─TableFullScan_16 | 10.00 | cop[tikv] | table:planets | keep order:false, stats:pseudo |
| └─TableReader_8(Probe) | 0.25 | root | | data:TableRangeScan_7 |
| └─TableRangeScan_7 | 0.25 | cop[tikv] | table:stars | range: decided by [universe.planets.sun_id], keep order:false, stats:pseudo |
+-----------------------------+---------+-----------+---------------+------------------------------------------------------------------------------------------------------------------------------------------------------------+
5 rows in set (0.00 sec)
表连接类算子-BatchedNestedLoopJoinBasedOnIndex
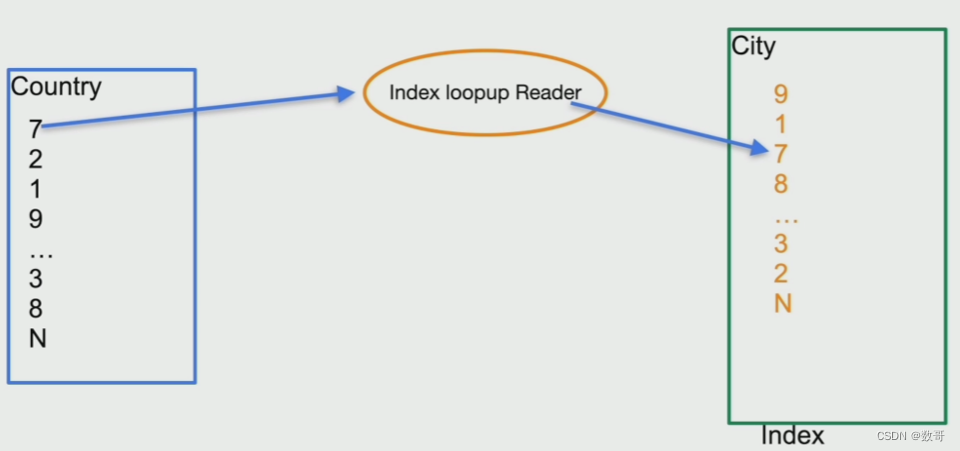
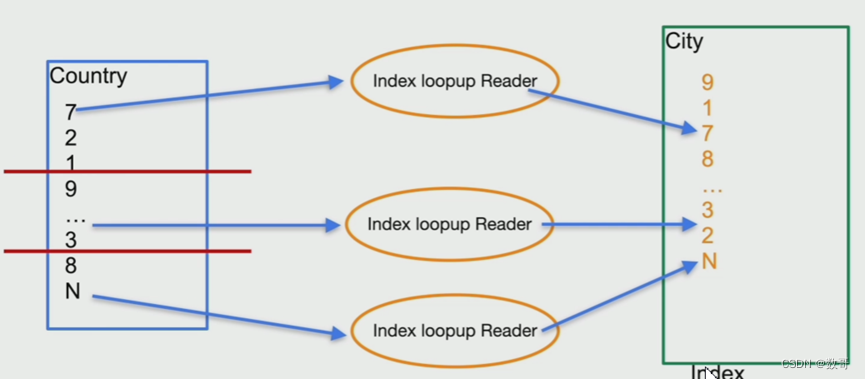
一条条的在分布式的TiKV中处理很慢,优化措施:
- 通过分布式的原生特性,可以并行多线程处理
- 每次处理不是一条条,而是多条,批量处理
实验
查看执行计划
1、造数
mysql> create table t1(a int,b int);
Query OK, 0 rows affected (0.24 sec)
mysql> create table t2(a int ,b int, index idx(b));
Query OK, 0 rows affected (0.17 sec)
mysql>
[root@tidb2 ~]# for i in `seq 10000`; do mysql -uroot -P4000 -h192.168.16.13 -pAa123ab! -e "insert into test.t1 values ($i,floor(rand()*10000000))"; done;
[root@tidb2 ~]# for i in `seq 10000`; do mysql -uroot -P4000 -h192.168.16.13 -pAa123ab! -e "insert into test.t2 values ($i,floor(rand()*10000000))"; done;
2、查看执行计划
mysql> explain select * from t1 where t1.a < (select sum(t2.a) from t2 where t2.b=t1.b);
+----------------------------------+----------+-----------+---------------+--------------------------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+----------------------------------+----------+-----------+---------------+--------------------------------------------------------------------------------------------------------------+
| HashJoin_11 | 10112.88 | root | | inner join, equal:[eq(test.t1.b, test.t2.b)], other cond:lt(cast(test.t1.a, decimal(20,0) BINARY), Column#7) |
| ├─HashAgg_18(Build) | 10112.37 | root | | group by:Column#18, funcs:sum(Column#16)->Column#7, funcs:firstrow(Column#17)->test.t2.b |
| │ └─Projection_39 | 10114.00 | root | | cast(test.t2.a, decimal(10,0) BINARY)->Column#16, test.t2.b, test.t2.b |
| │ └─TableReader_31 | 10114.00 | root | | data:Selection_30 |
| │ └─Selection_30 | 10114.00 | cop[tikv] | | not(isnull(test.t2.b)) |
| │ └─TableFullScan_29 | 10114.00 | cop[tikv] | table:t2 | keep order:false |
| └─TableReader_15(Probe) | 10112.88 | root | | data:Selection_14 |
| └─Selection_14 | 10112.88 | cop[tikv] | | not(isnull(test.t1.b)) |
| └─TableFullScan_13 | 10123.00 | cop[tikv] | table:t1 | keep order:false |
+----------------------------------+----------+-----------+---------------+--------------------------------------------------------------------------------------------------------------+
9 rows in set (0.01 sec)
3、执行并查看执行计划
mysql> explain analyze select * from t1 where t1.a < (select sum(t2.a) from t2 where t2.b = t1.b);
+----------------------------------+----------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+----------+---------+
| id | estRows | actRows | task | access object | execution info | operator info | memory | disk |
+----------------------------------+----------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+----------+---------+
| HashJoin_11 | 10000.00 | 0 | root | | time:84ms, loops:1, build_hash_table:{total:79.9ms, fetch:74.9ms, build:5.04ms}, probe:{concurrency:5, total:414.7ms, max:83.3ms, probe:2.34ms, fetch:412.3ms} | inner join, equal:[eq(test.t1.b, test.t2.b)], other cond:lt(cast(test.t1.a, decimal(20,0) BINARY), Column#7) | 1.07 MB | 0 Bytes |
| ├─HashAgg_18(Build) | 9995.00 | 9995 | root | | time:75.1ms, loops:12, partial_worker:{wall_time:67.869444ms, concurrency:5, task_num:10, tot_wait:210.402437ms, tot_exec:9.078728ms, tot_time:220.66839ms, max:45.617063ms, p95:45.617063ms}, final_worker:{wall_time:79.824609ms, concurrency:5, task_num:25, tot_wait:330.977695ms, tot_exec:44.187184ms, tot_time:375.177565ms, max:76.089309ms, p95:76.089309ms} | group by:Column#18, funcs:sum(Column#16)->Column#7, funcs:firstrow(Column#17)->test.t2.b | 3.80 MB | N/A |
| │ └─Projection_39 | 10000.00 | 10000 | root | | time:40.6ms, loops:11, Concurrency:5 | cast(test.t2.a, decimal(10,0) BINARY)->Column#16, test.t2.b, test.t2.b | 189.1 KB | N/A |
| │ └─TableReader_31 | 10000.00 | 10000 | root | | time:32.4ms, loops:11, cop_task: {num: 1, max: 32.2ms, proc_keys: 10000, tot_proc: 9ms, tot_wait: 10ms, rpc_num: 1, rpc_time: 32.2ms, copr_cache_hit_ratio: 0.00} | data:Selection_30 | 156.8 KB | N/A |
| │ └─Selection_30 | 10000.00 | 10000 | cop[tikv] | | tikv_task:{time:7ms, loops:14}, scan_detail: {total_process_keys: 10000, total_process_keys_size: 449822, total_keys: 10001, rocksdb: {delete_skipped_count: 0, key_skipped_count: 10000, block: {cache_hit_count: 1, read_count: 0, read_byte: 0 Bytes}}} | not(isnull(test.t2.b)) | N/A | N/A |
| │ └─TableFullScan_29 | 10000.00 | 10000 | cop[tikv] | table:t2 | tikv_task:{time:7ms, loops:14} | keep order:false | N/A | N/A |
| └─TableReader_15(Probe) | 10000.00 | 10000 | root | | time:80.5ms, loops:11, cop_task: {num: 1, max: 80.5ms, proc_keys: 10000, tot_proc: 53ms, rpc_num: 1, rpc_time: 80.5ms, copr_cache_hit_ratio: 0.00} | data:Selection_14 | 156.8 KB | N/A |
| └─Selection_14 | 10000.00 | 10000 | cop[tikv] | | tikv_task:{time:53ms, loops:14}, scan_detail: {total_process_keys: 10000, total_process_keys_size: 449806, total_keys: 25563, rocksdb: {delete_skipped_count: 7781, key_skipped_count: 33343, block: {cache_hit_count: 9, read_count: 0, read_byte: 0 Bytes}}} | not(isnull(test.t1.b)) | N/A | N/A |
| └─TableFullScan_13 | 10000.00 | 10000 | cop[tikv] | table:t1 | tikv_task:{time:36ms, loops:14} | keep order:false | N/A | N/A |
+----------------------------------+----------+---------+-----------+---------------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+--------------------------------------------------------------------------------------------------------------+----------+---------+
9 rows in set (0.10 sec)
绑定执行计划
任务:采用hint和SPM的方法绑定还行计划
- 造数
create table t1 (a int,b int,c varchar(10),d varchar(20));
create table t2 (a int,b int,c varchar(10),d varchar(20));
[root@tidb2 ~]# for i in `seq 10000`; do mysql -uroot -P4000 -h192.168.16.13 -pAa123ab! -e "insert into test.t1 values ($i,floor(rand()*10000000),substring(MD5(RAND()),1,5),substring(md5(rand()),1,10))"; done;
[root@tidb2 ~]# for i in `seq 10000`; do mysql -uroot -P4000 -h192.168.16.13 -pAa123ab! -e "insert into test.t2 values ($i,floor(rand()*10000000),substring(MD5(RAND()),1,5),substring(md5(rand()),1,10))"; done;
2、添加索引
create index t1_ind_1 on t1(a);
create index t1_ind_2 on t1(a,b,c);
create index t2_ind_1 on t2(a);
create index t2_ind_2 on t2(a,b,c)
3、查看原执行计划
mysql> explain select t1.a,t1.b,t1.c,t2.b from t1,t2 where t1.a = t2.a and t1.b > t2.b order by t1.b,t2.b;
+--------------------------------+----------+-----------+-----------------------------------+------------------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+--------------------------------+----------+-----------+-----------------------------------+------------------------------------------------------------------------------------------+
| Sort_8 | 10000.00 | root | | test.t1.b, test.t2.b |
| └─MergeJoin_11 | 10000.00 | root | | inner join, left key:test.t1.a, right key:test.t2.a, other cond:gt(test.t1.b, test.t2.b) |
| ├─IndexReader_42(Build) | 10000.00 | root | | index:Selection_41 |
| │ └─Selection_41 | 10000.00 | cop[tikv] | | not(isnull(test.t2.b)) |
| │ └─IndexFullScan_40 | 10000.00 | cop[tikv] | table:t2, index:t2_ind_2(a, b, c) | keep order:true |
| └─IndexReader_39(Probe) | 10000.00 | root | | index:Selection_38 |
| └─Selection_38 | 10000.00 | cop[tikv] | | not(isnull(test.t1.b)) |
| └─IndexFullScan_37 | 10000.00 | cop[tikv] | table:t1, index:t1_ind_2(a, b, c) | keep order:true |
+--------------------------------+----------+-----------+-----------------------------------+------------------------------------------------------------------------------------------+
8 rows in set (0.00 sec)
4、通过hint强制走指定的索引
mysql> explain select t1.a,t1.b,t1.c,t2.b from t1,t2 use index(t2_ind_1) where t1.a = t2.a and t1.b > t2.b order by t1.b,t2.b;
+-------------------------------------+----------+-----------+-----------------------------------+-----------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------------------+----------+-----------+-----------------------------------+-----------------------------------------------------------------------------------+
| Sort_8 | 10000.00 | root | | test.t1.b, test.t2.b |
| └─HashJoin_40 | 10000.00 | root | | inner join, equal:[eq(test.t1.a, test.t2.a)], other cond:gt(test.t1.b, test.t2.b) |
| ├─IndexLookUp_56(Build) | 10000.00 | root | | |
| │ ├─IndexFullScan_53(Build) | 10000.00 | cop[tikv] | table:t2, index:t2_ind_1(a) | keep order:false |
| │ └─Selection_55(Probe) | 10000.00 | cop[tikv] | | not(isnull(test.t2.b)) |
| │ └─TableRowIDScan_54 | 10000.00 | cop[tikv] | table:t2 | keep order:false |
| └─IndexReader_52(Probe) | 10000.00 | root | | index:Selection_51 |
| └─Selection_51 | 10000.00 | cop[tikv] | | not(isnull(test.t1.b)) |
| └─IndexFullScan_50 | 10000.00 | cop[tikv] | table:t1, index:t1_ind_2(a, b, c) | keep order:false |
+-------------------------------------+----------+-----------+-----------------------------------+-----------------------------------------------------------------------------------+
9 rows in set (0.01 sec)
5、通过SPM创建执行计划绑定
create binding for
select t1.a,t1.b,t1.c,t2.b from t1,t2 where t1.a = t2.a and t1.b > t2.b order by t1.b,t2.b
using
select t1.a,t1.b,t1.c,t2.b from t1,t2 use index(t2_ind_1) where t1.a = t2.a and t1.b > t2.b order by t1.b,t2.b
mysql> explain select t1.a,t1.b,t1.c,t2.b from t1,t2 where t1.a = t2.a and t1.b > t2.b order by t1.b,t2.b;
+-------------------------------------+----------+-----------+-----------------------------------+-----------------------------------------------------------------------------------+
| id | estRows | task | access object | operator info |
+-------------------------------------+----------+-----------+-----------------------------------+-----------------------------------------------------------------------------------+
| Sort_8 | 10000.00 | root | | test.t1.b, test.t2.b |
| └─HashJoin_40 | 10000.00 | root | | inner join, equal:[eq(test.t1.a, test.t2.a)], other cond:gt(test.t1.b, test.t2.b) |
| ├─IndexLookUp_56(Build) | 10000.00 | root | | |
| │ ├─IndexFullScan_53(Build) | 10000.00 | cop[tikv] | table:t2, index:t2_ind_1(a) | keep order:false |
| │ └─Selection_55(Probe) | 10000.00 | cop[tikv] | | not(isnull(test.t2.b)) |
| │ └─TableRowIDScan_54 | 10000.00 | cop[tikv] | table:t2 | keep order:false |
| └─IndexReader_52(Probe) | 10000.00 | root | | index:Selection_51 |
| └─Selection_51 | 10000.00 | cop[tikv] | | not(isnull(test.t1.b)) |
| └─IndexFullScan_50 | 10000.00 | cop[tikv] | table:t1, index:t1_ind_2(a, b, c) | keep order:false |
+-------------------------------------+----------+-----------+-----------------------------------+-----------------------------------------------------------------------------------+
9 rows in set (0.00 sec)















 3636
3636











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











