







问题场景:
今天我在爬虫汇总数据的时候,采用的数据结构为列表套字典如下:
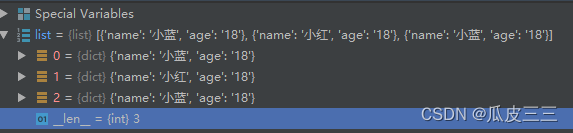
这里有一个列表里面有三个元素类型都是字典,可以看到索引为0和2的元素key和value完全相同。
这是我想去掉其中一个就是一个简单的字典去重方法,列表去重很简单,直接采用set转为集合方法在转回list类型,我尝试了一下,我天真的以为此时的数据结构也可以这样操作。
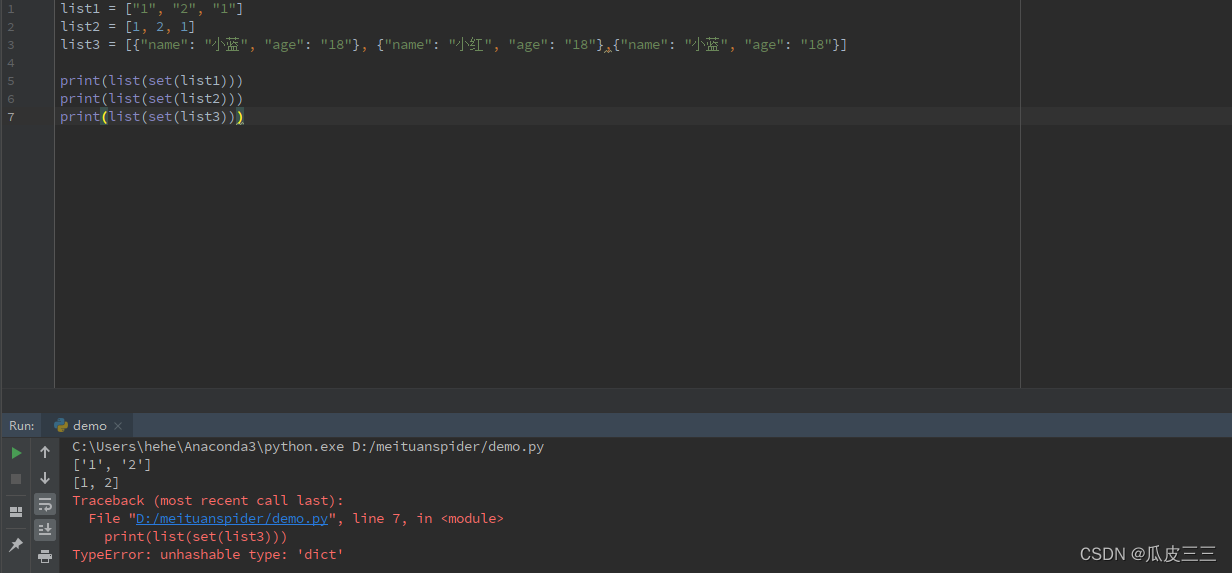
错误提示说 不可哈希类型。
可哈希:int \ float \ str \ tuple
不可哈希: list \ set \ dict
列表嵌套字典去重:
data_list= [{"name": "小蓝", "age": "18"}, {"name": "小红", "age": "18"}, {"name": "小蓝", "age": "18"}]
def DictinList_duplicate(data_list):
"""
列表套字典去重
:return:
"""
seen = set()
new_l = []
for d in data_list:
t = tuple(d.items())
if t not in seen:
seen.add(t)
new_l.append(d)
print(new_l)
- 先创建一个空集合,一个空列表
- 循环我们要传进来的列表,
- 将其字典的items()转化为元组,作为可哈希类型
- 如果集合不存在则添加到集合和空列表中,
第二种方法:
data_list= [{"name": "小蓝", "age": "18"}, {"name": "小红", "age": "18"}, {"name": "小蓝", "age": "18"}]
new_list = [dict(d) for d in (set([tuple(d.items()) for d in data_list]))]
-
先将列表循环去除dict将其转换为元组在放入集合中实现去重,在循环一次将去重后的元组转为字典
-
第一种方法用了外部变量和if判断,这种方法用了两次循环,时间复杂度会高
结果:

-
将字典转为tuple类型放入集合中达到去重的效果,在转为列表
列表嵌套列表去重:
raw_list = [
["百度", "CPY"],
["百度", "CPY"],
["京东", "CPY"],
["百度", "CPY", ]
]
new_list = [list(t) for t in set(tuple(_) for _ in raw_list)]
print(new_list)
结果:
[['京东', 'CPY'], ['百度', 'CPY']]

















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









