






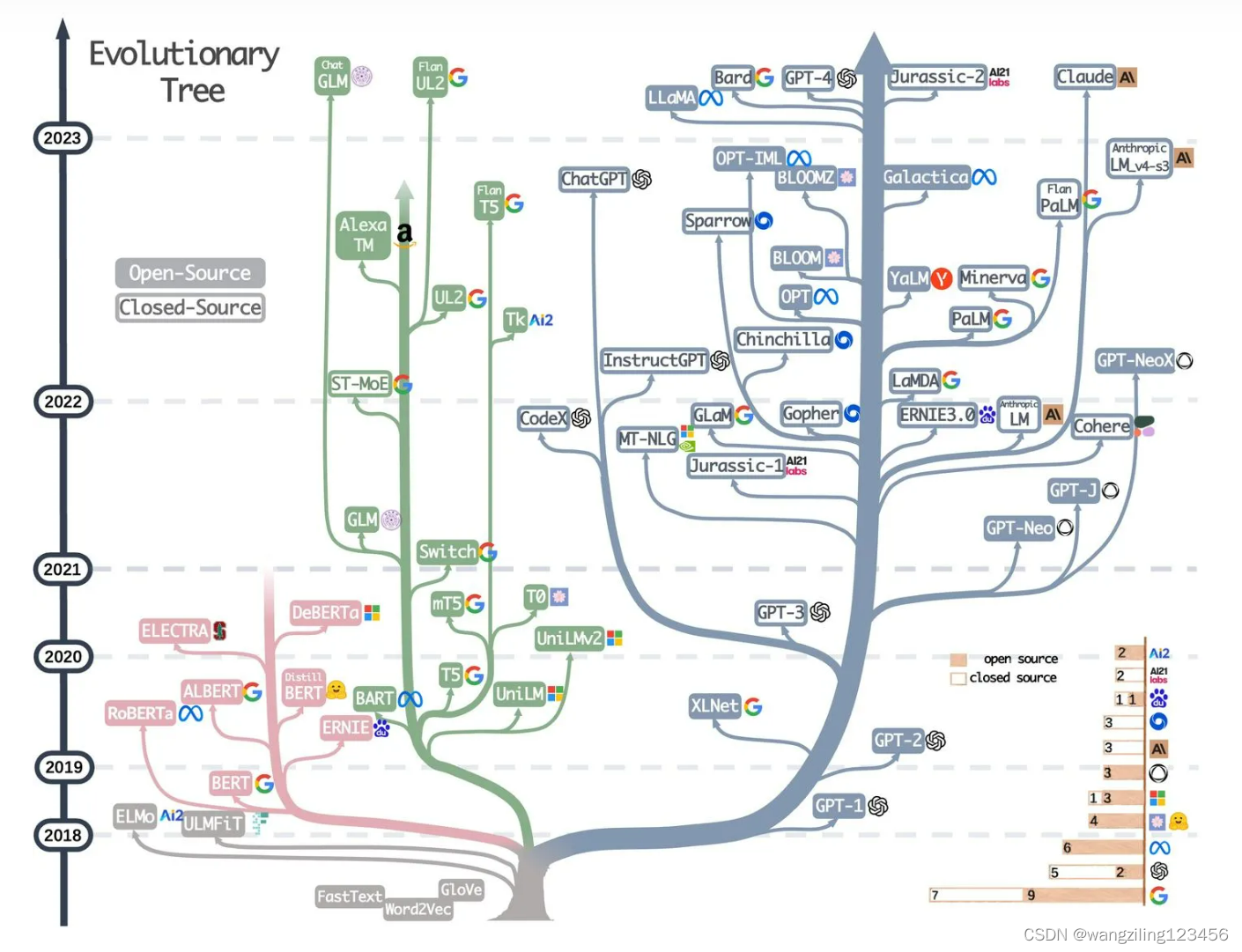
起源
transformer模型,它由级联的encoder和decoder组成。输入一段文本,编码器把它压缩到潜空间,再用解码器翻译成新的文本。
encoder-only ——BERT派
像善于分析的专家,输入一段文本,可以将文本拆解的头头是道
本质是把高维数据压缩到低维空间
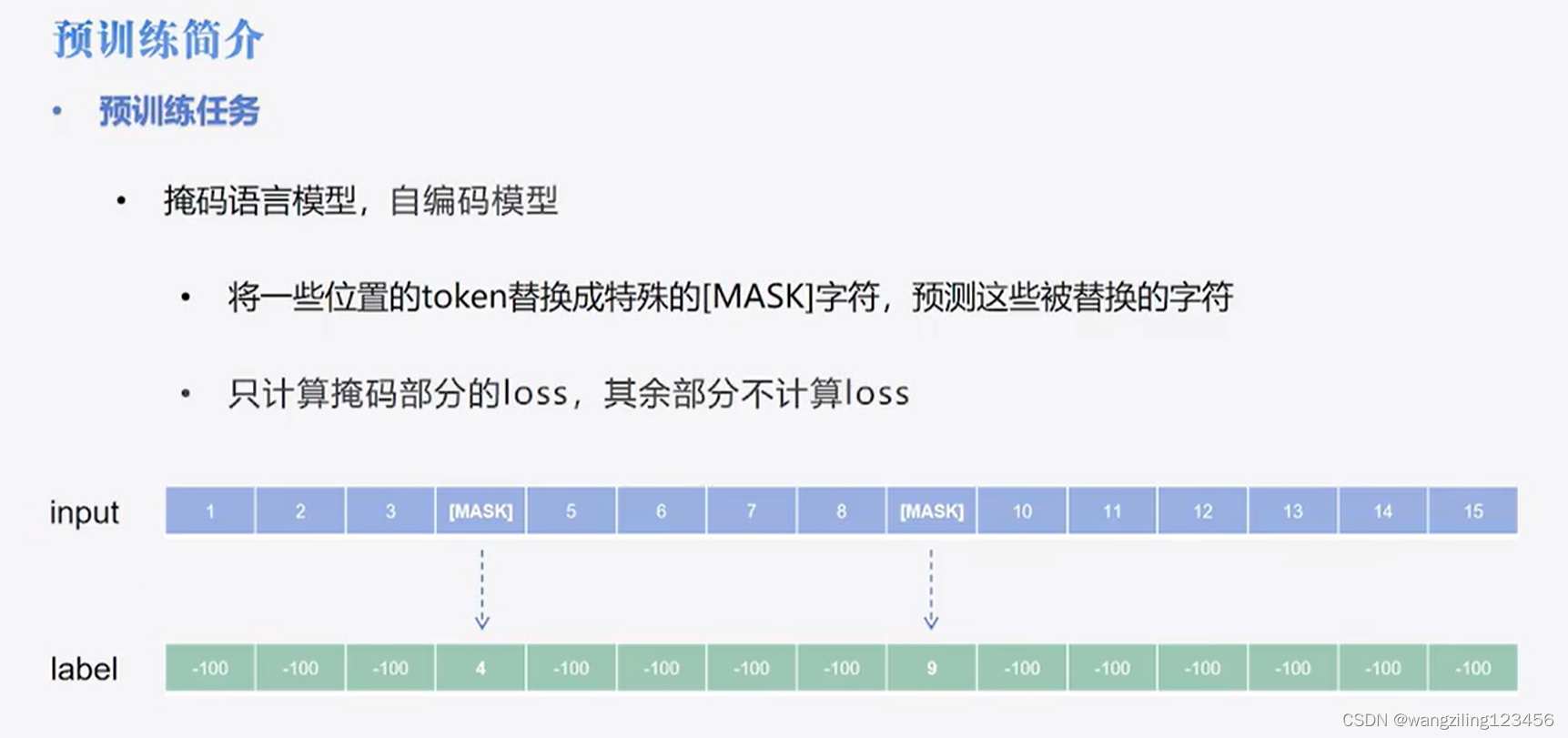
本质是完形填空的模式,给定一个句子,随即掩盖掉一些词,然后让模型预测是什么,训练要同时考虑上下文 ,这就体现了BERT的双向性,比单向的搜索空间更大,因为他需要在整个词汇表中找最合适的词来填充每个空
decoder-only ——GPT派
会讲故事的专家,能流畅的自说自话
采用的是自回归序列,给定一个序列,模型预测之后可能出现的不同单词,计算概率,选择最大概率输出,不断迭代能输出完整的句子
本质上他学习的是词与词之间的造句关系,搜索空间相对较小,就像一个人在不断自我学习,锻炼讲故事的能力
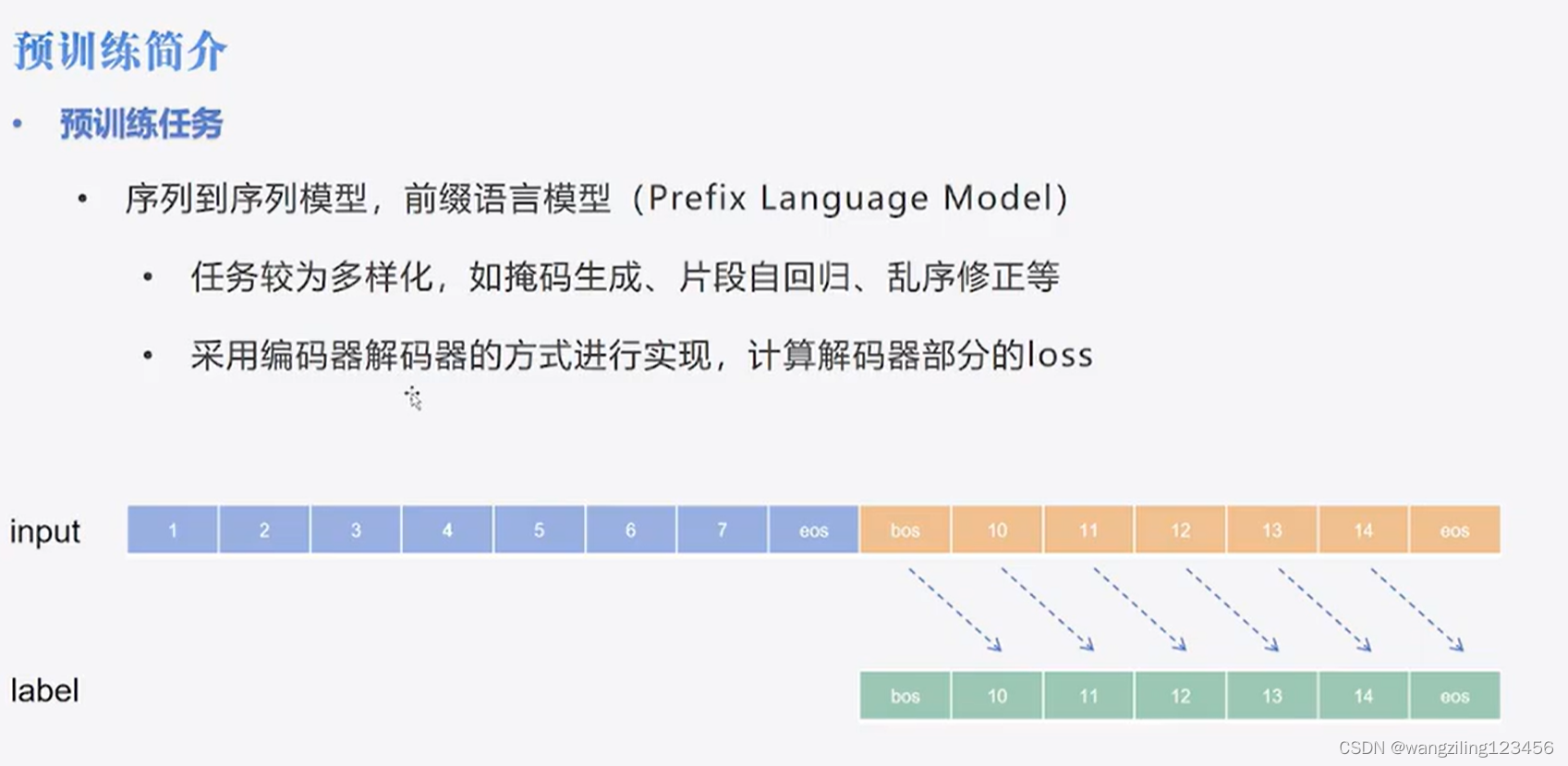
encoder+decoder ——T5派
GPT派
相比于gpt-2,谷歌的gopher验证了通过扩大模型的规模有效处理复杂任务的可行性,chinchilla验证了增加数据比增加模型参数更有效,llama则通过不到十分之一的参数便实现了堪比gpt系列的性能
大模型训练流程图




参考视频
动画科普LLM大模型进阶之路:为何GPT之外一定要关注LLaMA_哔哩哔哩_bilibili
【手把手带你实战HuggingFace Transformers-实战篇】实战演练之预训练模型_哔哩哔哩_bilibili


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









