







目录
前言
前段时间学习了学习型索引的开山之作,想运行下代码深入理解下,但是遇到点问题,机缘巧合下看到了这篇论文,A Critical Analysis of Recursive Model Indexes,2021发布的,是对前面提出的学习型索引的批判性总结,尤其是对RMI模型进行了测试,代码我也正在尝试运行,之后运行成功之后再发博客好了。
文章目的
从文章摘要就可以看出来,自从学习型索引被提出来,这个机器学习结合数据库的领域就火起来了,但是那篇第一次提出学习型索引的论文,提出的递归模型索引(RMI),在论文中讲的不是很详细,代码也是后面才开源的,我自己看的时候原理了解了,但对代码不了解,而且配置RMI涉及到设置多个超参数,没有讲的很明白。所以这篇文章进行了第一次独立于发明人的广泛的RMI分析,目的是了解每个超参数对性能的影响。而且也对之前提出的学习型索引模型进行了介绍,我看去是大有收获,就是目前基于各种原因,环境还有软件,还有外网下载速度慢因素,还没有运行代码,之后补上。
文章贡献
(1)学习树结构索引。我们详细回顾了递归模型索引[23],并解释了它们是如何训练的,以及要考虑哪些超参数(第2节)。我们提供了一个关于学习索引的设计维度的详细概述,以及该领域已经很大的工作(第3节)。
(2)超参数分析。我们提出了我们的实验设置(第4节),并进行了一系列广泛的实验,以分析每个超参数对预测精度和搜索区间大小(第5节),查找性能(第6节)和构建时间(第7节)的影响。
(3)配置指南。根据我们的研究结果,我们制定了一个简单的指导方针,在实践中配置RMI(第8节)。
(4)与其他指标的比较。我们将我们的指南在查找时间和构建时间方面产生的RMI与许多学习的索引进行比较,如ALEX [14],PGM-index [16],RadixSpline [21]和RMI的参考实现[26],以及最先进的传统索引,如B-tree [12],ART [24]和Hist-Tree [13](第9节)。
递归模型索引
作者重新对RMI进行了详细的介绍
核心理念
RMI使用数据的累积分布函数(CDF)来计算排序数组中的键的位置。设𝐷为一个数据集,由𝑛=|𝐷| keys.此外,设x是以相等概率取每个键的值的随机变量,并且设FX是x的CDF。然后,排序数组中每个键Xi∈D的位置计算为: 𝑖 = 𝐹𝑋 (𝑥𝑖 ) · 𝑛 = 𝑃(𝑋 ≤ 𝑥𝑖 ) · n
RMI按照我的理解就是,针对一个排序数组,根据CDF函数知道𝑃(𝑋 ≤ 𝑥𝑖 )的概率,最后乘以总数,就知道排序数组中键的位置。

索引查找
我们已经知道了核心理念,但是查找没有想象中的这么简单。查找分两个步骤执行:(1)预测:我们评估的RMI在一个给定的关键产生的位置估计。(2)错误更正:我们在排序阵列中的估计位置周围的区域中搜索关键字以补偿估计误差。
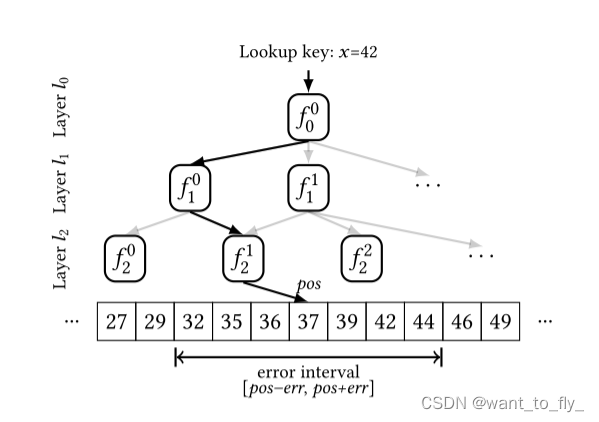
上面的图就是一个查找x=42,先在根模型得到位置估计,然后在根据位置估计选择下一层的
进行评估,继续该过程,直到获得最后一层的位置估计pos。

以下是论文中提到的RMI的伪代码

初始化RMI 𝑅为一个二维数组,用于存储模型。初始化"keys"数组为一个二维数组,用于存储每个模型的键。将数据集𝐷中的所有键分配给根模型,通过设置keys[0, 0] = 𝐷。接着是一个三层循环,第一层就是遍历层数,第二层是遍历每层的模型,第二层和第二层循环中间紧挨着的就是训练第i层的第j个模型。之后判断是不是最后一层来选择退不退出循环。遍历keys[𝑖, 𝑗]中的所有键。调用函数GetModelIndex(𝑥, 𝑅[𝑖, 𝑗], 𝑙[𝑖 + 1], |𝐷|)来获取键𝑥的模型索引𝑝。将键𝑥添加到下一层的模型𝑝中,即将其附加到keys[𝑖 + 1, 𝑝]中。
目前学习型索引相关的算法(截止这篇文章发布)

FITing-tree.
拟合树[17]使用分段线性近似(PLA)对CDF进行建模。在训练过程中,首先通过贪婪算法将数据集划分为可变大小的片段,在数据的单次传递中。以这样的方式创建这些段,使得它们的线性近似满足用户定义的误差界限。然后通过将片段批量加载到B树中来索引片段。查找包括遍历B树以找到包含关键字的段,基于段的线性近似计算估计位置,以及在估计位置周围的误差范围内搜索关键字。FITing-tree支持插入,或者通过在片段内移动现有键来就地插入,或者使用缓冲策略,其中每个片段都有一个缓冲区,每当缓冲区满时,该缓冲区就会与片段中的其他键合并。不幸的是,在撰写本文时,还没有FITing-tree的开源实现,这使我们无法将其包含在我们的实验中。
ALEX
使用可变深度树结构来近似具有线性模型的CDF。内部节点是线性模型,给定一个关键字,确定子节点。叶节点保存数据,其分布再次由线性模型近似。在查找期间,遍历树直到到达叶节点,然后使用叶的线性模型预测位置,并且最后,使用指数搜索来搜索关键字。像RMI一样,ALEX是自上而下训练的,但是,ALEX具有由成本模型控制的动态结构,该成本模型决定如何分割节点。ALEX支持通过拆分或展开完整节点来插入。
PGM
通过PLA近似CDF。类似于拟合树,PGM索引通过计算满足误差界限的段开始。然而,与FITingTree相反,PGM索引创建在分段数量上最优的PLA模型。每个片段由该片段中的最小键和近似该片段的线性函数表示。之后,通过再次在每个片段的最小键上创建PLA模型,该过程自下而上递归地继续。只要剩下一个段,递归就终止。因此,与ALEX不同,从根模型到段的每条路径长度相等。查找是迭代过程,其中在PGM索引的每个级别上(1)线性模型预测包含键的下一层段,(2)使用二进制搜索在预测周围的误差范围内搜索正确段,以及(3)对于下一层段继续该过程,直到达到键的排序阵列。Ferragina和Vinciguerra [16]还引入了支持更新(动态PGM索引)和段级压缩(压缩PGM索引)的PGM索引变体。PGM索引的大小取决于满足用户定义的误差界限所需的段的数量。
RadixSpline
与上述学习的索引相比,RadixSpline [21]使用线性样条近似CDF。线性样条曲线在数据上一次拟合,并满足用户定义的误差范围。生成的样条线点被插入到基数表中,该基数表将关键帧映射到具有相同前缀的最小样条线点。基数表的大小取决于用户定义的前缀长度。查找包括使用基数表找到查找关键字周围的样条点,在样条点之间执行线性插值以获得估计位置,以及在估计位置周围的误差区间中应用二分搜索以找到关键字。与RMI一样,RadixSpline具有固定的层数,并且不支持更新。
设备环境
所有实验都在具有Intel® Xeon® CPU E5-2620 v4(2.10 GHz,20 MiB L3)和4x 8 GiB DDR4 RAM的Linux机器上进行。我们的代码使用clang-12.0.1编译,优化级别为-O2,并以单线程执行。
因为目前放暑假,身边没有现成的linux的机器,之前搞得wsl2刚好被删了,所以接下来我再重新搞下wsl2然后跑跑看运行下代码,如果运行成功,我就继续更新。














 2477
2477











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









