







系列文章目录
学习型索引结构---开山之作学习 The Case for Learned Index Structures
学习索引--A Critical Analysis of Recursive Model Indexes(2021) (上)
学习型索引结构--ALEX: An Updatable Adaptive Learned Index
学习型索引----ALEX代码的一些记录
学习索引结构--基于区域划分与降维的高维学习型索引
目录
前言
想看看学习型索引结构有哪些方向,就看了下最近知网上发布的论文,然后就挑了这篇软件学报上发布的论文 基于区域划分与降维的高维学习型索引
一、成果
目前的高维学习型索引采用的方法并不能将数据分布的信息有效利用起来, 而且过于复杂的深度学习模型使得索引初始化开销过大. 结合空间区域划分与降维两种技术, 提出一种新颖的高维学习型索引. 它能更有效地利用数据分布信息提高索引的查询效率, 并利用多段线性模型在保证查找精确度的前提下尽可能减少索引初始化的开销. 分别在随机生成的数据集和开源街区地图数据集上进行实验验证. 结果表明, 与现有的高维索引相比, 其在索引构建、查询效率、以及内存占用方面都有显著提高.
二、详细介绍
常用的高维数据查询类型有范围查询、点查询和最近邻查询等. 范围查询即在给定数据空间中, 返回一定查询范围内的所有数据点; 点查询可以看做一种特殊的范围查询, 即给定的查询范围很小, 只有唯一满足条件的数据点; 最近邻查询是给定数据空间中的一个目标点, 返回空间中距离它最近的一个或几个数据点.
由于大数据应用中数据量的庞大, 使得用遍历的方式对高维数据进行查询变得低效不可行, 所以必须为高维数据搭建专门的索引结构. 最典型的传统高维索引结构有 R树 及其各种变体如 R* 树 、R+ 树 、QR树 等,以及四叉树及其各种变体 .
经典的传统高维索引结构的缺陷很明显,R树的变体------当数据维度较大的时候, 它们的查询速度会骤降, 数据量增加时, 也会影响它们的查询效率, 而且 R树本身内存占用极大, 构建过程也十分耗时。四叉树与 R树类似, 它是将平面空间四等分, 然后在四等分上迭代划分, 它的应用只局限于二维空间, 而且查询与维护的开销较大.
所以在索引结构中引入了机器学习和深度学习的知识, 利用学习的方式来代替传统索引, 将查询转换为模型的一次预测, 这样就可以依赖计算机的计算优势来提高索引查询效率.
最初的高维学习型索引是对整个数据空间进行模型训练, 但是结果并不理想, 模型难以收敛, 精度明显无法满足需求, 而且模型只能针对单一的数据分布, 迁移性很差, 于是数据降维和空间区域划分等策略被运用到了索引结构中. 为了有效地使用学习型方法, 首先需要将高维数据按照一定的顺序排列, 数据降维类索引的思路是先将空间中所有点降至一维, 然后在一维有序数据上训练模型, 这类方法会将全部降维后的数据进行排序, 并对整体数据训练模型, 所以会存在误差大、模型复杂、训练时间久、难以收敛等缺点; 空间区域划分类索引首先在数据轴上对空间进行切分, 然后对数据空间进行排序, 从而使空间内的数据有序, 再利用学习的方式筛选与查询相关的区域, 遍历相关区域内数据点. 这种方法稳定性较差, 查询效率易受查询范围影响.
针对上述问题, 本文尝试结合空间区域划分和数据降维两种策略, 尽可能将数据分布的信息全部利用起来, 构造符合数据分布的高维学习型索引结构, 提升高维数据查询效率. 除此之外利用最简单的多段线性模型, 在保证查询精确度的前提下, 尽可能降低索引的构建开销和存储开销.
三、增强高维学习型索引 IHDL
本文的目标是尽可能利用高维数据的数据分布信息, 构建高效的学习型索引; 同时尽可能降低索引构建和存储的开销, 实现轻量级高维索引. 由于数据本身分布存在差异, 所以将全部数据进行降维排序处理或者是对数据轴进行均匀划分, 并不能有效地将数据分布的信息利用起来, 而且只靠单个机器学习模型很难学习空间数据的整体分布规律, 模型的误差较大. 所以如何根据数据分布将空间分区域处理, 并在每个区域内训练高效的模型结构成了提升高维学习型索引效率的关键.
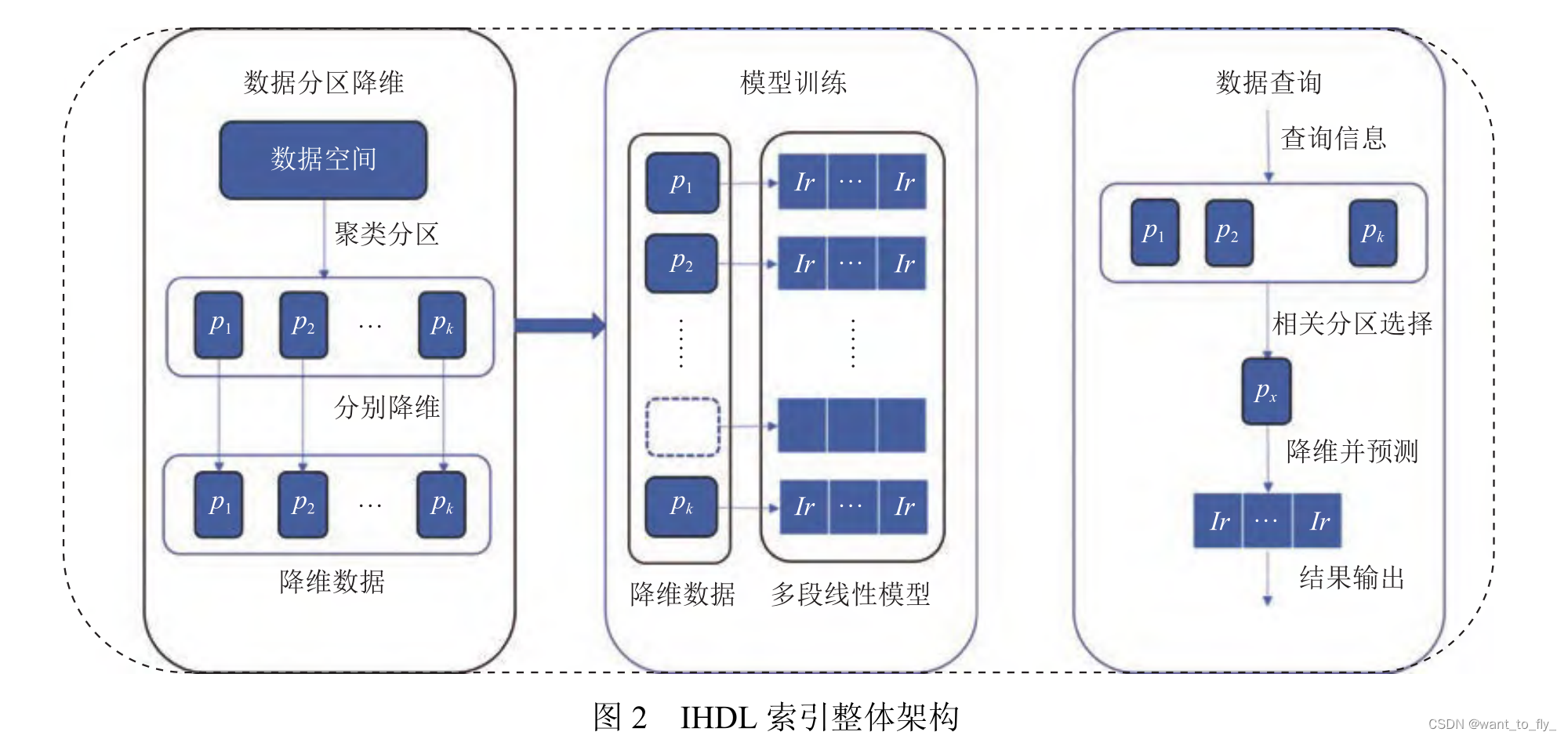
IHDL索引设计了 3个处理阶段对数据分布进行学习:
(1)利用聚类算法根据数据的聚集程度将空间划分成K个区域, 使相同区域内的数据分布尽可能集中, 不同区域之间的数据分布尽可能分散, 这样有利于下一步的模型训练;
(2)对每个空间区域中的数据, 利用 Hilbert编码的方式分别进行降维排序处理, Hilbert编码是现有降维技术中稳定性最好的, 可以在保证空间数据相对位置的前提下实现降维, 而且当数据空间改变, 编码阶数增大的时候,也可以保证数据点之间的相对位置不被改变;
(3)针对每个区域已经降维的数据进行学习型模型的训练, 尽可能去拟合对应空间区域的数据分布. 除此之外, 由于不同数据区域的模型都是独立训练维护, 所以有数据更新需要进行模型重新训练的时候, 只需要对数据更新涉及区域重新训练模型即可, 不需要对整个索引结构进行更改, 从而极大地减少了索引维护的成本, 提高了索引的可扩展性.
3.1聚类
大多空间数据存在一定的聚集性, 如在地图类型数据集中, 整体数据点的分布存在区域性, 反映在现实地图中, 就可以理解为, 有的区域内地点与建筑分布较为密集, 而有的区域则比较稀疏. 所以根据数据分布的聚集情况进行空间划分,可以有效地将分布较为相似的数据划分到同一个区域, 而且分布相似的点进行 Hilbert编码以后, 可以使模型更容易学习, 精度更高.
本文采用基于划分的聚类算法 K-means, 这是一种简单有效的无监督学习算法, 可以快速实现区域划分, 而且最大限度地保证数据区分度. 由于高维数据存在维度诅咒的问题, 即当数据维度过高时, 各数据点直接的距离会趋于一致使得一般距离公式失效的现象. 所以 K-means需要根据数据的维度对距离公式进行选择, 当数据维度较低时采用较为简单的欧式距离, 数据维度过高时采用余弦相似性.

算法 1展示具体的聚类及空间区域划分的过程. D为空间数据集, 首先根据 K-means算法进行迭代, 计算每个数据点与所有中心点的距离, 选择与其距离最近的簇作为自己的标签, 全部数据计算之后, 更新聚簇中心点, 再次迭代全部数据, 直至聚类簇不发生改变为止. 最后根据聚类返回的聚簇中心点和聚簇边界, 将数据空间划分成 K个部分.
3.2降维与模型训练
空间区域划分, 已经将整个高维空间划分成了K个部分. 接下来就是针对每个区域进行降维处理, 并对降维的数据进行模型训练. 在一维空间中, 数据之间有自然的大小关系, 对于范围查询只要返回两个边界点之间的全部数据即可, 但是高维数据本身没有固定的相对大小,无法进行有规则的排序, 学习型索引只适用于有序数据, 所以需要运用 Hilbert的映射方式, 将高维数据映射成一维.

该曲线将高维空间的数据点全部串连起来, 使得高维数据有了固定的排序, 这样就可以实现高维数据向一维的映射. 除此之外, Hilbert曲线还具有很好的聚集性, 在空间中相近的点在 Hilbert曲线上也一定相近, 这就使得编码后的数据保留了原始数据的分布特点.
对于已经降至一维的数据, 首先我们尝试使用全连接神经网络进行拟合, 用 Hilbert编码作为神经网络的输入,数据在一维序列里的位置作为每个数据的标签, 神经网络采用双隐藏层, 采用 ReLU做激活函数进行非线性变换,用预测值与真实值的均方差 (MSE)做代价函数, 对模型进行多次训练循环, 尽可能降低每个分区内模型的预测误差.
当分区内数据量较小的时候, 降维数据的线性特征较为明显,所以并不需要训练有非线性变换的神经网络. 采用多段线性模型来拟合降维后的数据分布不仅可以满足精度要求, 更可以减少模型训练的复杂度、提高查询速度、减少模型的训练时间. 多段线性模型的构建过程采用自适应树 [9]中提及的思路, 对一维有序数列进行遍历, 增量式地进行构建, 判断每个节点是否满足前一个线性函数预设的误差边界, 如果不满足就以该节点为起点, 构建新的一个线性函数, 最后将所有线性函数的起点和斜率存到树形结构中. 具体算法如算法 2所示.
多段线性模型的分段依据是误差边界, 所以只需要控制误差边界的大小就可以保证模型的准确性, 例如当误差边界与 R树的节点容量相同时, 可以看作其准确性与 R树相同. 除此之外, 多段线性模型也统一了每个分区的误差边界, 极大地减少模型训练带来的不确定性.

3.3数据查询
在降维数据上训练得到 K个独立的模型, 而且所有模型都有共同的误差边界, 使用索引进行查
询时, 首先定位与查询相关的空间区域, 计算每个相关区域内与查询区域的交集. 由于 Hilbert曲线满足非封闭性,所以对于给定的查询超矩形, Hilbert曲线一定会与超矩形相交, 这就使得该超矩形内数据的 Hilbert编码最大值与最小值必然出现在查询矩形的边界上. 所以范围查询可以转换成两次点预测, 只需要计算交集边界上的 Hilbert编码最大最小值, 然后在线性模型中分别进行预测, 返回预测值 和 Pre (min)和Pre(max).
IHDL不仅实现了常见的范围查询, 它采用查询转换的方法将最近邻查询转换成范围查询以此来实现最近邻查询. 如算法 3所示, M为数据区域的数据密度, 在查询转换的时候, 首先根据分区内的数据密度预测一个初始的查询范围, 返回该范围内距离查询点最近的前 K个数据点. 如果范围内点数量小于 K, 则再次根据数据密度将查询范围逐渐扩大, 直至返回全部满足条件的数据. 算法平均复杂度为 O(m×K), 其中 m为进行范围查询的次数, K为最近邻查询点数量.

总结
这篇论文主要的方法就是高纬度的数据首先通过聚类进行分区,然后通过Hilbert降维成了一维,然后对一维数据进行训练,得到模型,通过分析,并没有使用神经网络而是分段使用线性回归,效果好,还快。最后最重要一点。。。。。我没找到源码,太难了orz。找到源码Q我一下,好心人,对于研究生来说也太难了。简单的看了下,之后在看会修改好好看。















 760
760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









