







最近学习索引结构的进步建议用近似学习模型来替代现有的索引结构,比如b树。在这项工作中,我们提出了一个统一的基准,它将三种已经学习过的索引结构的优化实现与几种最先进的传统基准进行比较。通过使用四个真实的数据集,我们证明了在内存中只读工作负载下,学习索引结构在密集数组上的性能确实优于非学习索引。我们研究了缓存、流水线、数据集大小和密钥大小的影响。我们研究了学习的索引结构的性能,并建立了一个解释为什么学习的模型能取得如此好的性能。最后,我们研究了学习索引结构的其他重要特性,例如它们在多线程系统中的性能和构建时间。
1.
虽然索引结构是数据库管理系统中研究最充分的组成部分之一,但最近的工作[11,18]为这个几十年前的话题提供了一个新的视角,展示了如何使用机器学习技术来开发所谓的学习索引结构。与传统的索引结构(如[9,14,15,19,30,32])不同,学习索引结构构建底层数据的显式模型来提供有效的索引
更糟糕的是,缺乏开源实现迫使研究人员重新实现[18]技术,或使用封底计算,以与学习的索引结构进行比较。虽然这本身不是一件坏事,但我们很容易不优化基线,或做出其他不现实的假设,即使是出于最好的意图,这可能会使主要内容变得空洞。
在本文中,我们试图从三个方面解决这些问题:(1)我们提供了一个RMIs的第一个开源实现,供研究人员进行比较和改进;(2)我们创建了一个包含多个真实数据集和工作负载的存储库,用于测试;(3)我们创建了一个基准测试套件,它可以方便地与已知的和传统的索引结构进行比较。为了避免与弱基线进行比较,我们的开源基准测试套件[4]包含了广泛使用的索引结构实现,这些索引结构由原始作者进行了调整,或者两者兼有。
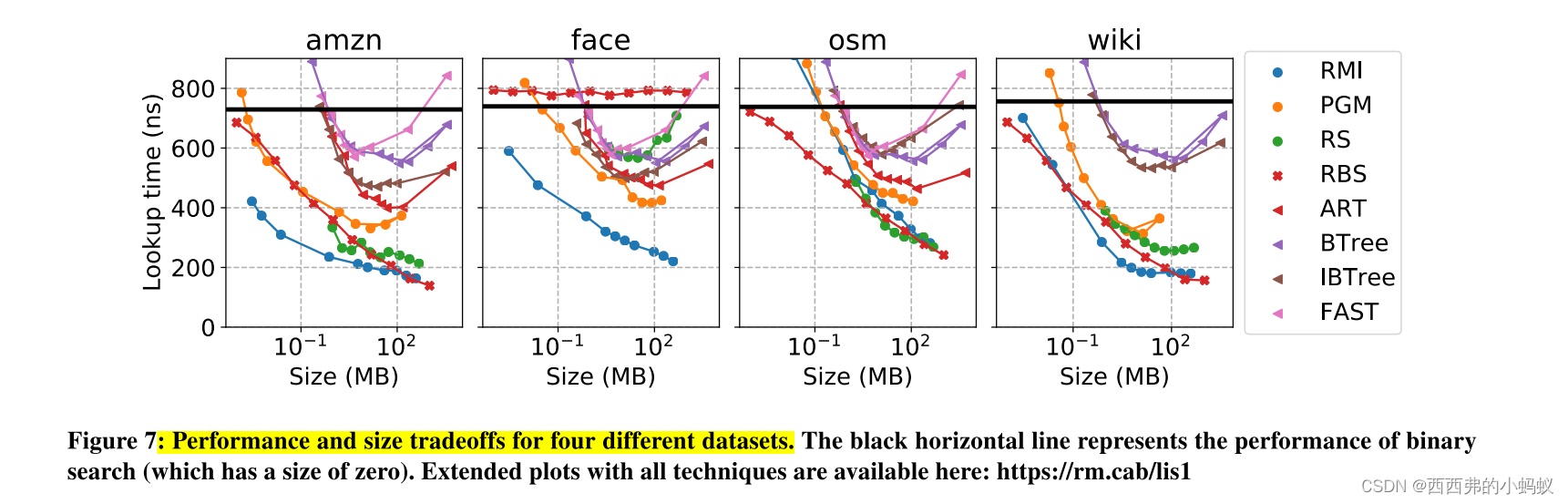
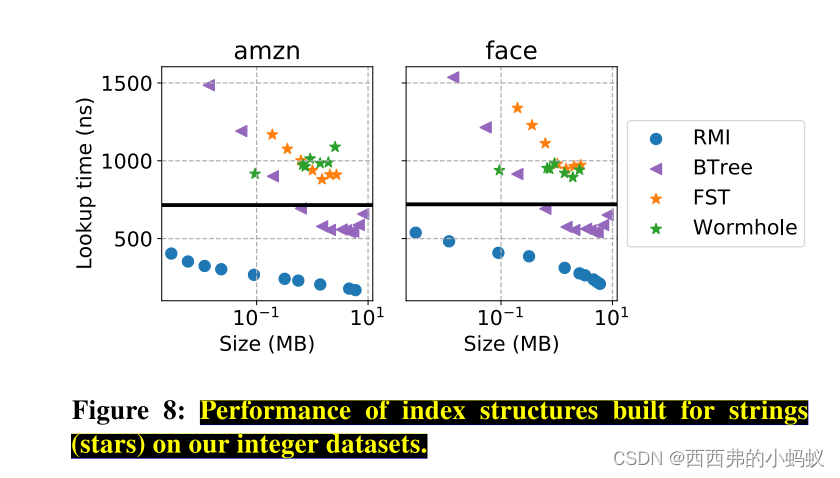
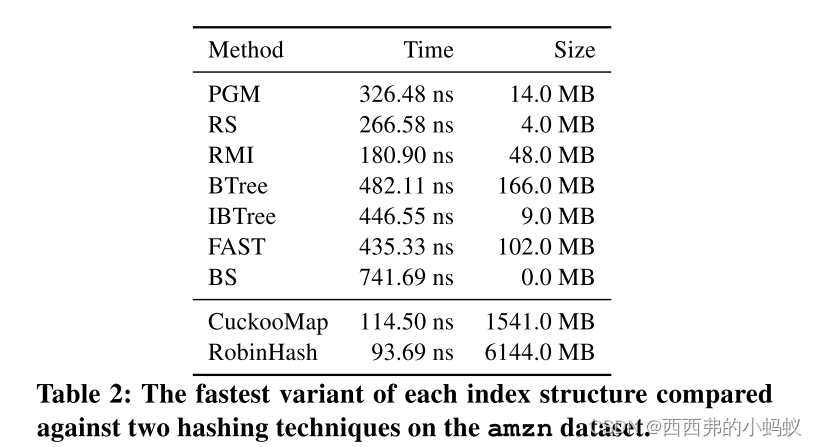
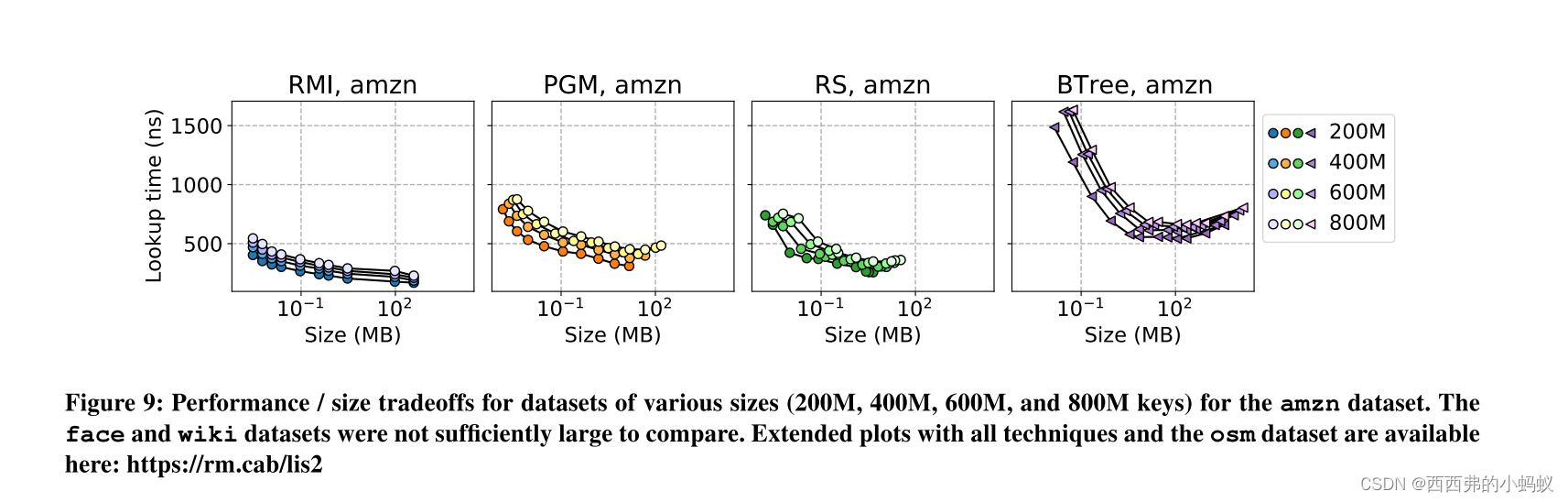
Understanding learned indexes 除了提供一个用于未来研究的开源基准测试外,我们还试图更深入地理解已学习的索引结构,扩展[16]的工作。首先,我们提出了三种最近学习的索引结构(RMIs [18], PGM[12]和RS[17])的帕累托分析。几种传统的索引结构,包括树、tries和哈希表。我们表明,在热缓存、紧密循环设置中,所有三种学习索引结构变体都可以提供比几种传统索引结构更好的性能/大小权衡。我们将这种分析扩展到多个数据集大小,32和64位整数,以及不同的搜索技术(即二进制、线性、插值)。
其次,我们分析了为什么学习的索引结构能取得如此好的性能。虽然我们无法找到一个完全解释索引结构性能的指标(直观地看,这样的指标似乎不存在),但我们提供了性能计数器和其他属性的统计分析。最重要的解释变量是缓存丢失,尽管缓存丢失本身不足以对统计意义重大的解释。令人惊讶的是,我们发现分支缺失并不能解释为什么学习的索引结构比传统结构性能更好,就像[18]中最初宣称的那样。事实上,我们发现学习索引结构和传统索引结构都能有效地使用分支
第三,我们分析索引结构在存在内存围栏、冷缓存和多线程环境下的性能,以测试更真实设置下的行为。在所有情况下,我们发现学习的方法都表现良好。
FORMULATION & DEFINITIONS
我们在一个零索引的排序数组𝐷上定义了一个索引结构𝐼,作为一个整数查找键𝑥∈Z之间的映射
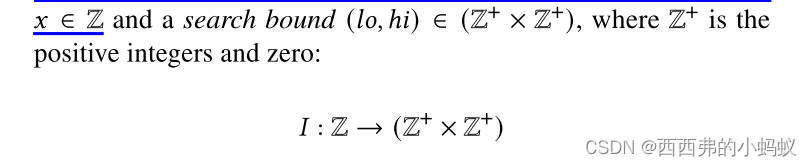
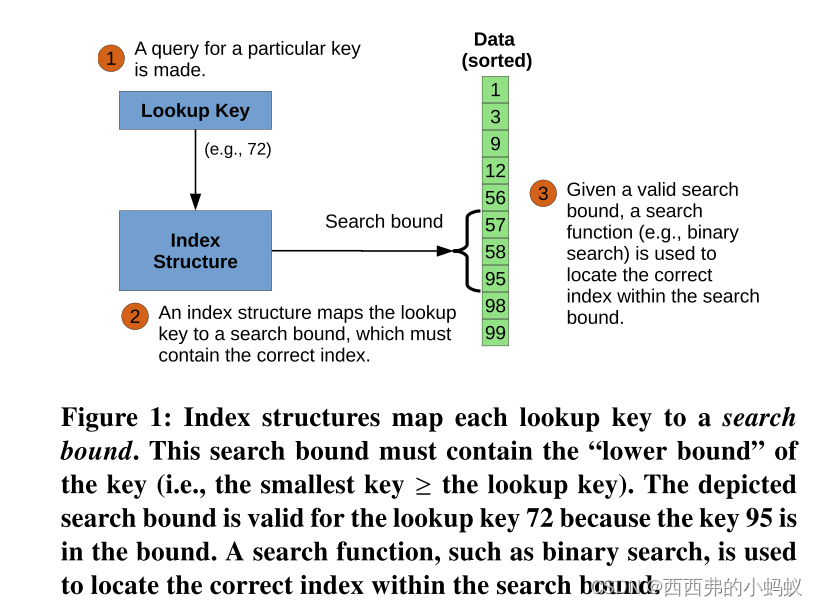
Approximating the CDF
学习索引结构使用机器学习技术,从深度神经网络到简单回归,以建模一个排序数组[18]的累积分布函数,或CDF。这里,我们使用术语CDF表示函数将键映射到它们在数组中的相对位置
给定数据集的CDF,用CDF𝐶𝐷𝐹𝐷在数据集𝐷中找到查找键𝑥的下界很简单:只需计算𝐶𝐷𝐹𝐷(𝑥)× |𝐷|。通过使用学习的模型(例如,线性回归)逼近数据集的CDF来学习索引结构函数。当然,这样的学习模型并不完全准确


LEARNED INDEX STRUCTURES
本文评估了三种不同的学习索引结构:递归模型索引(RMI)、基样条索引(RS)和分段几何模型索引(PGM)的性能。虽然这三种技术都近似于底层数据的CDF,但构建这些近似的方式各不相同。接下来,我们将对每种技术进行高层次的概述,然后讨论它们的差异。
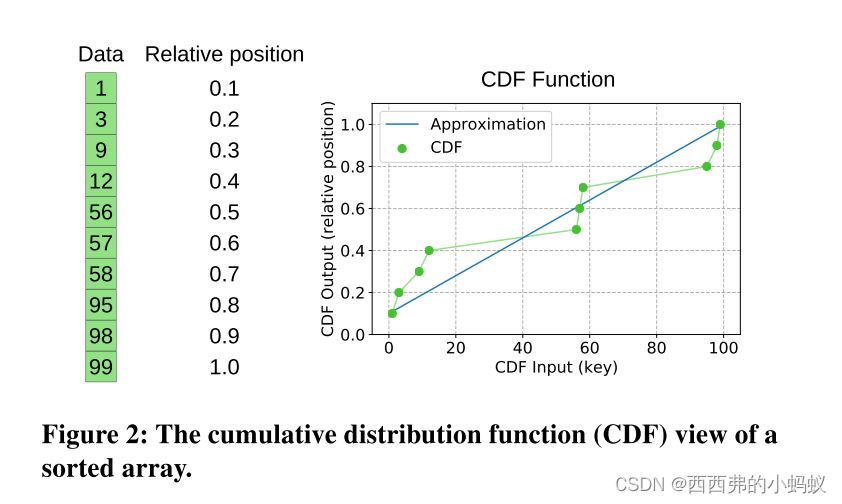
1)Recursive model indexes (RMI)
RMIs使用多阶段模型,将更简单的机器学习模型组合在一起。例如,如图3所示,一个有两个阶段的RMI,一个线性阶段和一个立方阶段,首先使用一个线性模型对特定密钥的CDF进行初始预测(阶段1)。然后,基于该预测,RMI将从几个立方模型中选择一个来细化这个初始预测(阶段2)。
Structure.


为两个阶段选择正确的模型(𝑓1和𝑓2),并为特定数据集选择最佳的分支因子,这取决于RMI所需的内存占用以及底层数据。在本工作中,我们设计了CDFShop RMI自调优器[21]。
 2)Radix spline indexes (RS)
2)Radix spline indexes (RS)
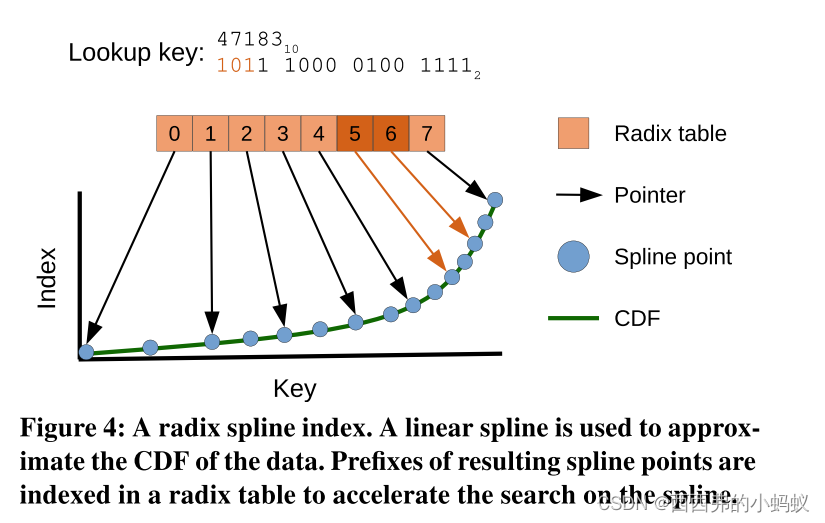
RS索引[17]由近似于数据的CDF的线性样条[24]和索引样条点的基数表(图4)组成。RS以自底向上的方式构建。独特的是,RS可以在单次传递中构建,每个元素的最坏情况代价是恒定的(PGM提供恒定的平摊代价)。
3) Piecewise geometric model indexes (PGM)
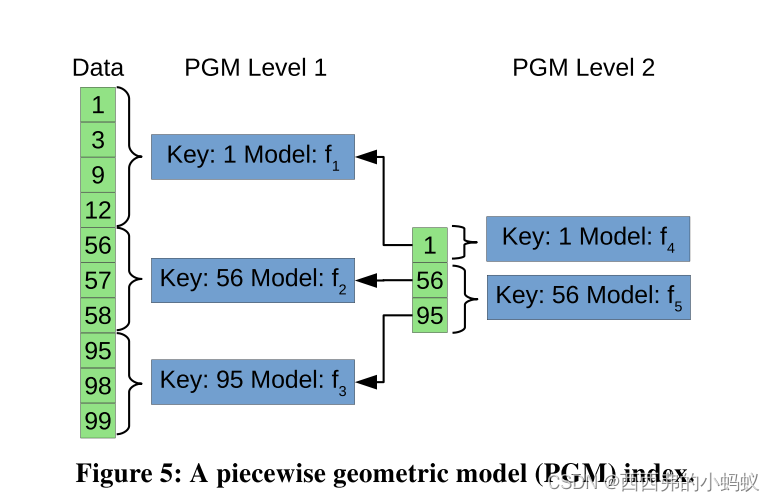
PGM索引是一个多层次的结构,其中每一层代表一个误差有界的分段线性回归[12]。图5描述了一个示例PGM索引。在第一级,数据被分成三个部分,每个部分用一个简单的线性模型表示(𝑓1,𝑓2,𝑓3)。通过构建这些线性模型,每个线性模型都可以在预设的误差范围内预测对应段中键的CDF。然后将第一级的划分边界作为它们自己的排序数据集,计算另一个误差有界的分段线性回归。这样重复,直到PGM的顶层足够小。
Structure. 分段线性回归将数据划分为𝑛+1段,其中包含一组点𝑝0,𝑝1,…,𝑝𝑛。将整个分段线性回归表示为分段函数:
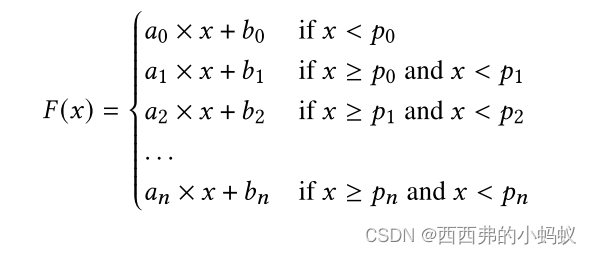
PGM指数中的每一个回归都是用一个固定的错误界限𝜖构造的。这样的回归可以很容易地用作近似指标。PGM指数递归地应用这个技巧,首先在底层数据上构建一个错误有界的分段回归模型,然后在第一次回归的分区点上构建另一个错误有界的分段回归模型。通过搜索每个索引层执行键查找,直到对底层数据进行回归。
4)Discussion
RMIs、RS索引和PGM索引都近似于底层数据的CDF。然而,具体情况各不相同:
Model types. RS指数和PGM指数仅使用单一类型的模型(分别为样条回归和分段线性回归),RMIs可以使用多种模型类型。这为RMI提供了更大程度的灵活性,但也增加了调优RMI的复杂性。虽然可以通过调节两个旋钮来调整PGM索引和RS索引,但自动优化RMI需要更复杂的方法,比如[21]。PGM指数的作者和RS指数的作者都提到集成其他模型类型是未来的工作[12,17]。
Top-down vs. bottom-up RMIs进行自上而下的训练,首先拟合最顶层的模型,然后训练随后的层来纠正错误。PGM和RS指数自底向上训练,首先将最底层拟合到固定精度,然后建立后续层,快速在最底层搜索相应的模型。因为PGM和RS索引都需要搜索这个最底层(PGM可能需要搜索几个中间层),所以它们可能需要比RMI更多的分支或缓存丢失。虽然RMI使用其最顶层模型直接索引到下一层,完全避免搜索,但RMI的最底层没有固定的错误界限;任何底层模型都可能存在较大的最大误差
RS索引和PGM索引在搜索最底层的方式上也有所不同。PGM索引递归地分解问题,本质上是在最底层的顶部构建第二个PGM索引。因此,PGM索引可能有许多层,在推断期间必须对每一层进行搜索(在固定的范围内)。另一方面,RS索引使用基数表来缩小搜索范围,但不能保证搜索范围的大小。如果radix表提供了与PGM索引的上层相当的搜索范围,然后RS索引通过相对便宜的操作(位移和数组查找)定位适当的最终模型。如果基数表提供的搜索范围不窄,则可能会花费大量时间搜索适当的底层模型
EXPERIMENTS
Experiments are conducted on a machine with 256 GB of RAM and an Intel(R) Xeon(R) Gold 6230 CPU @ 2.10GHz.
Index。在本节中,我们将描述我们评估的索引结构,以及如何调整它们的大小/性能折衷。表1列出了每种技术及其功能。
Learned indexes. 我们比较了RMIs、PGM索引和RadixSpline索引(RS),
Tree structures

Hashing.


Datasets:
We use four real-world datasets for our evaluation. Each dataset consists of 200 million unsigned 64-bit integer keys. We generate random 8-byte payloads for each key

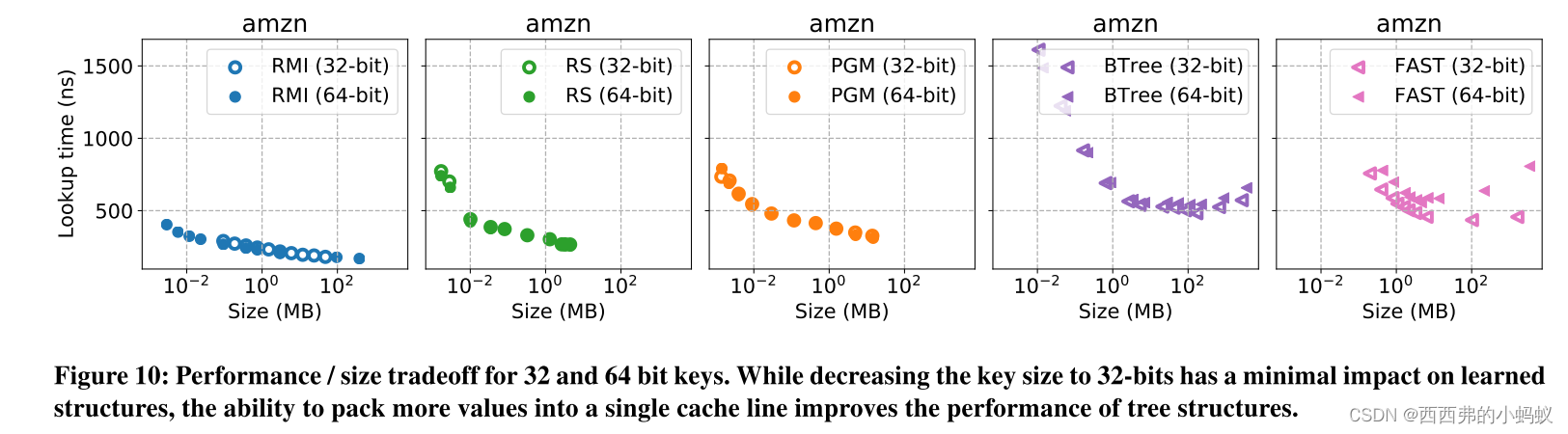
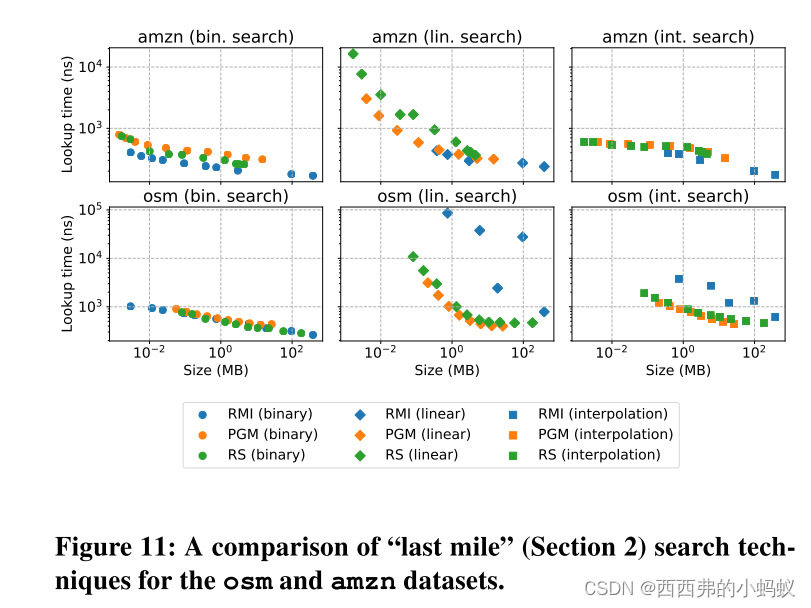














 1870
1870











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









