







机器学习中,我们需要通过一些训练数据来学习一个模型运用到测试数据中去,当这个模型的复杂度很高,即参数很多时,往往在训练数据上表现很好,但在测试数据上表现很差,造成测试结果与训练结果差异很大的现象,即过拟合。这就需要我们增加模型的泛化能力,降低模型的复杂度,这就是正则化的作用。
1.L1、L2
比较通用的增加模型泛化能力的方法就是为模型增加一个惩罚项,这个惩罚项一般有L1范数、L2范数以及L1与L2范数耦合。
加了正则化项之后的目标函数为
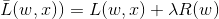
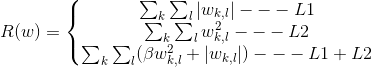
2.dropout
dropout就是在前向网络中,随机置0一些神经元,即让神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
加入dropout后的函数:y=fw(x)——>y=fw(x,z) (z为dropout掩码)
dropout掩码为一个随机值,在测试中平均化这个随机值:
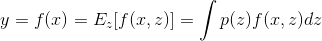
Δ:可以在测试时乘一个dropout概率p,或者在训练时乘p,测试时不乘(训练时一般使用GPU速度很快,乘以p基本不会增加耗时)。
Δ:加了dropout只在未置0地节点上传递梯度,所以每次只更新一部分小样本,所以训练时间变长。
3.批量归一化 BN
与dropout思想一样,在训练时用随机小样本的状态(均值与标准差)来归一化,测试时用固定的一个状态量(所有状态量的均值)
4.数据增强 Data Augmentation
通过改变数据(翻转、旋转、颜色抖动等)来改变数据。如一只猫的图片翻转过来仍然是一只猫的图片,可用翻转的图片也进行训练。
训练时,在随机裁剪和缩放的图片中采样;
测试时,在固定的裁剪中取均值,通常为4个角、中心位置以及它们的翻转图。
5.Data Connection
与dropout相似,不过随机置0地是权重矩阵中地一些权重值。
6.部分最大池化 Fractional Max Pooling
训练时随机选取最大池化的区域,测试时取某个固定的区域平均的结果
7.随即深度 Stochastic Depth
训练时随即消除一些层,在测试时用全部层来进行测试















 100
100











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









