





记忆与知识:RAG、Memory 与状态管理核心解析
请关注公众号【碳硅化合物AI】
摘要
智能体需要"记忆"才能持续对话,需要"知识"才能回答专业问题。AgentScope 提供了完整的记忆系统和 RAG(检索增强生成)能力,让智能体既能记住对话历史,也能从知识库中检索相关信息。本文将深入分析 Memory、RAG 和状态管理三个核心系统的实现,包括它们的类设计、工作流程,以及嵌套状态管理这个巧妙的设计。通过阅读本文,你会理解智能体如何管理短期和长期记忆,如何从向量数据库中检索知识,以及状态序列化的实现原理。
入口类与类关系
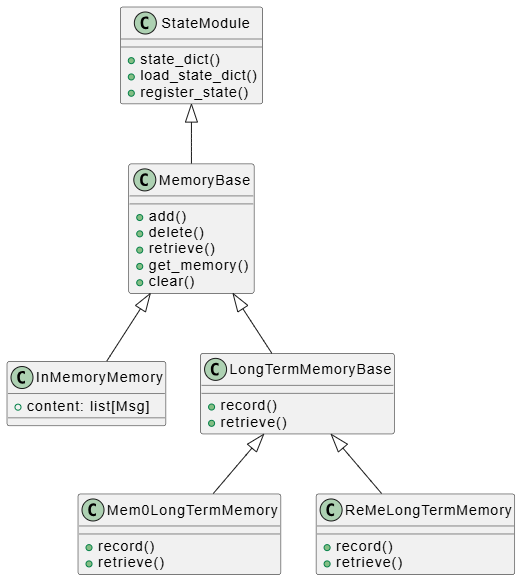
记忆系统的类层次
AgentScope 的记忆系统分为短期记忆和长期记忆,它们都继承自 MemoryBase:
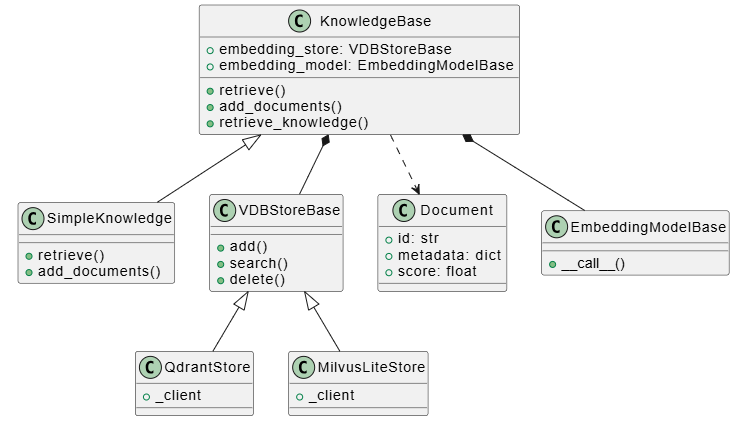
RAG 系统的类层次
RAG 系统由知识库、文档读取器和向量存储组成:
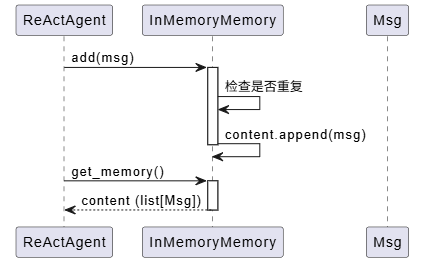
关键代码:MemoryBase 接口
让我们看看 MemoryBase 定义了哪些核心方法:
class MemoryBase(StateModule):
"""The base class for memory in agentscope."""
@abstractmethod
async def add(self, *args: Any, **kwargs: Any) -> None:
"""Add items to the memory."""
@abstractmethod
async def delete(self, *args: Any, **kwargs: Any) -> None:
"""Delete items from the memory."""
@abstractmethod
async def retrieve(self, *args: Any, **kwargs: Any) -> None:
"""Retrieve items from the memory."""
@abstractmethod
async def size(self) -> int:
"""Get the size of the memory."""
@abstractmethod
async def clear(self) -> None:
"""Clear the memory content."""
@abstractmethod
async def get_memory(self, *args: Any, **kwargs: Any) -> list[Msg]:
"""Get the memory content."""
这个接口非常简洁,但涵盖了记忆系统的所有核心操作。InMemoryMemory 是内存实现,直接存储 Msg 对象列表。
关键流程分析
Memory 存储和检索流程
短期记忆的流程非常简单直接:
InMemoryMemory 的实现非常直观:
async def add(
self,
memories: Union[list[Msg], Msg, None],
allow_duplicates: bool = False,
) -> None:
"""Add message into the memory."""
if memories is None:
return
if isinstance(memories, Msg):
memories = [memories]
# 检查重复(默认不允许重复)
if not allow_duplicates:
existing_ids = [_.id for _ in self.content]
memories = [_ for _ in memories if _.id not in existing_ids]
self.content.extend(memories)
async def get_memory(self) -> list[Msg]:
"""Get the memory content."""
return self.content
这种设计的好处是简单高效,适合大多数场景。如果需要持久化,可以使用长期记忆。
RAG 检索流程
RAG 的检索流程稍微复杂一些,涉及向量化和相似度搜索:
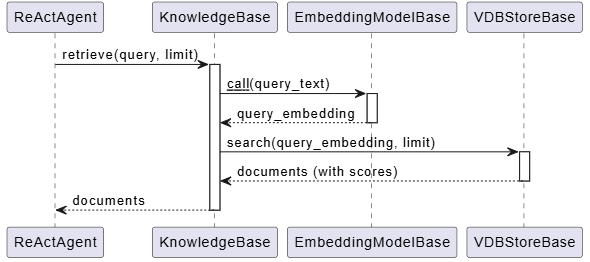
让我们看看 SimpleKnowledge 的检索实现:
async def retrieve(
self,
query: str,
limit: int = 5,
score_threshold: float | None = None,
**kwargs: Any,
) -> list[Document]:
"""Retrieve relevant documents by the given queries."""
# 1. 将查询向量化
res_embedding = await self.embedding_model(
[
TextBlock(
type="text",
text=query,
),
],
)
# 2. 在向量数据库中搜索
res = await self.embedding_store.search(
res_embedding.embeddings[0],
limit=limit,
score_threshold=score_threshold,
**kwargs,
)
return res
这个过程分为两步:
- 向量化查询:使用 EmbeddingModel 将文本查询转换为向量
- 相似度搜索:在向量数据库中找到最相似的文档
向量数据库(如 Qdrant、Milvus)使用高效的近似最近邻(ANN)算法,即使有百万级文档也能快速检索。
状态管理流程
状态管理的核心是序列化和反序列化:
关键技术点
1. RAG 的向量化存储和检索
RAG 系统的核心是向量相似度搜索。当你添加文档时:
# 1. 读取文档并分块
documents = await reader(text="...")
# 2. 向量化并存储
await knowledge.add_documents(documents)
在 add_documents 内部,会:
- 使用 EmbeddingModel 将每个文档块向量化
- 将向量和元数据存储到向量数据库
- 建立索引以支持快速检索
检索时,系统会:
- 将查询向量化
- 在向量数据库中搜索最相似的文档
- 根据相似度分数过滤结果
这种设计让智能体能够从大量文档中快速找到相关信息,而不需要遍历所有文档。
2. 短期记忆和长期记忆的区别
AgentScope 对短期记忆和长期记忆的区分很灵活:
-
短期记忆(MemoryBase):
- 存储对话历史
- 通常保存在内存中(
InMemoryMemory) - 快速访问,但会话结束后丢失
- 适合存储当前对话的上下文
-
长期记忆(LongTermMemoryBase):
- 持久化存储重要信息
- 支持语义检索(如 Mem0、ReMe)
- 可以跨会话使用
- 适合存储用户偏好、历史经验等
实际上,AgentScope 并不强制区分它们。你可以只使用一个强大的记忆系统,也可以组合使用。这种设计体现了"需求驱动"的理念。
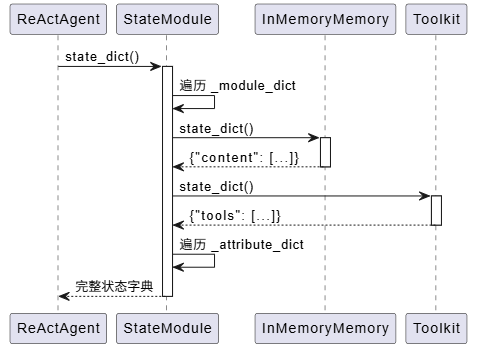
3. 嵌套状态管理机制
这是 AgentScope 的一个巧妙设计。StateModule 通过 __setattr__ 自动追踪子模块:
def __setattr__(self, key: str, value: Any) -> None:
"""Set attributes and record state modules."""
if isinstance(value, StateModule):
if not hasattr(self, "_module_dict"):
raise AttributeError(...)
self._module_dict[key] = value
super().__setattr__(key, value)
当你创建一个 ReActAgent 时:
agent = ReActAgent(
memory=InMemoryMemory(), # 自动被追踪
toolkit=Toolkit(), # 自动被追踪
...
)
这些子模块会自动被纳入状态管理。当你调用 agent.state_dict() 时:
def state_dict(self) -> dict:
"""Get the state dictionary of the module."""
state = {}
for key in self._module_dict:
attr = getattr(self, key, None)
if isinstance(attr, StateModule):
state[key] = attr.state_dict() # 递归调用
for key in self._attribute_dict:
attr = getattr(self, key)
to_json_function = self._attribute_dict[key].to_json
if to_json_function is not None:
state[key] = to_json_function(attr)
else:
state[key] = attr
return state
这种递归设计让状态管理变得非常强大。你可以保存整个智能体的状态,包括它的记忆、工具集等所有子组件。
4. 状态序列化和反序列化
状态序列化支持两种方式:
- 自动序列化:对于 JSON 可序列化的属性,直接序列化
- 自定义序列化:通过
register_state注册自定义的序列化函数
def register_state(
self,
attr_name: str,
custom_to_json: Callable[[Any], JSONSerializableObject] | None = None,
custom_from_json: Callable[[JSONSerializableObject], Any] | None = None,
) -> None:
"""Register an attribute to be tracked as a state variable."""
attr = getattr(self, attr_name)
if custom_to_json is None:
# 确保属性是 JSON 可序列化的
try:
json.dumps(attr)
except Exception as e:
raise TypeError(...)
self._attribute_dict[attr_name] = _JSONSerializeFunction(
to_json=custom_to_json,
load_json=custom_from_json,
)
这种设计让你可以:
- 保存复杂对象的状态
- 控制序列化的粒度
- 实现自定义的序列化逻辑
总结
Memory、RAG 和状态管理是 AgentScope 框架中非常重要的三个系统:
- Memory 系统:提供了灵活的短期和长期记忆管理,让智能体能够记住对话历史和重要信息
- RAG 系统:通过向量相似度搜索,让智能体能够从知识库中检索相关信息
- 状态管理:通过嵌套状态管理和自定义序列化,让智能体的状态可以完整保存和恢复
这三个系统的设计都体现了 AgentScope 的核心理念:模块化、透明、可扩展。在下一篇文章中,我们会分析模型、MCP 和工具系统的实现,这些组件为智能体提供了与外部世界交互的能力。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









