





智能体的心脏:ReActAgent 深度解析
请关注公众号【碳硅化合物AI】
摘要
ReActAgent 是 AgentScope 框架中最核心的智能体实现,它完美诠释了"推理-行动"(Reasoning-Acting)循环的精髓。本文将深入分析 ReActAgent 的类继承关系、核心执行流程,以及状态管理、钩子机制、实时介入等关键技术点。通过阅读本文,你会理解智能体如何与模型交互、如何执行工具、如何处理中断,以及这些机制背后的设计考量。
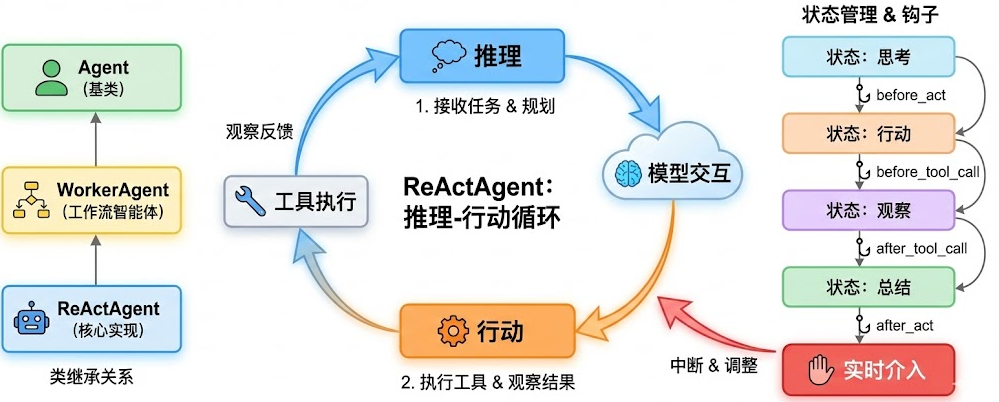
入口类与继承关系
类继承层次
ReActAgent 的类继承关系非常清晰,体现了良好的设计:
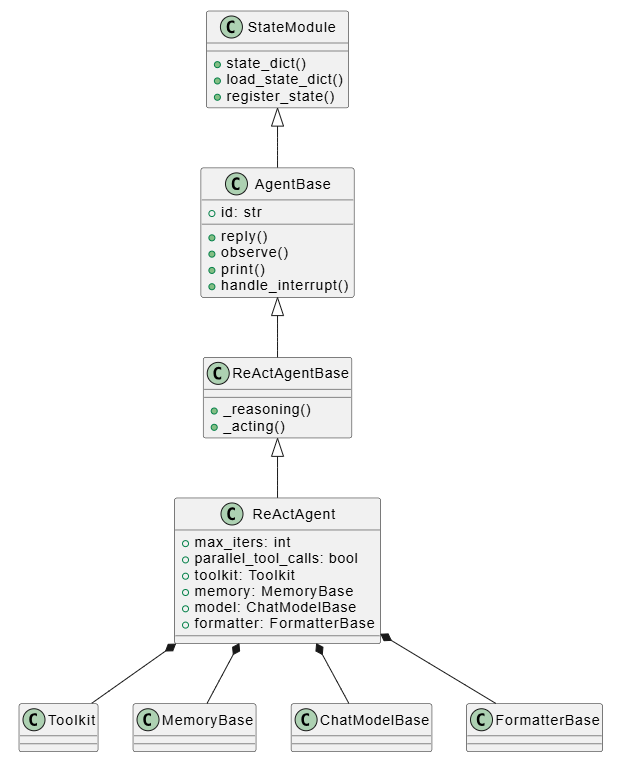
这个继承层次的设计非常巧妙:
- StateModule:提供状态管理能力,让智能体可以保存和恢复状态
- AgentBase:定义智能体的基本行为(reply、observe、print)
- ReActAgentBase:抽象出推理和行动两个核心方法
- ReActAgent:实现具体的 ReAct 逻辑
关键代码:AgentBase 的核心方法
让我们看看 AgentBase 是如何定义智能体基本行为的:
async def reply(self, *args: Any, **kwargs: Any) -> Msg:
"""The main logic of the agent, which generates a reply based on the
current state and input arguments."""
raise NotImplementedError(
"The reply function is not implemented in "
f"{self.__class__.__name__} class.",
)
这是一个抽象方法,子类必须实现。AgentBase 还提供了 observe 和 print 方法,分别用于接收消息(不返回响应)和显示消息。
AgentScope 整体架构
框架整体架构图
在深入 ReActAgent 之前,我们先看看 AgentScope 的整体架构,这样能更好地理解智能体在整个框架中的位置:
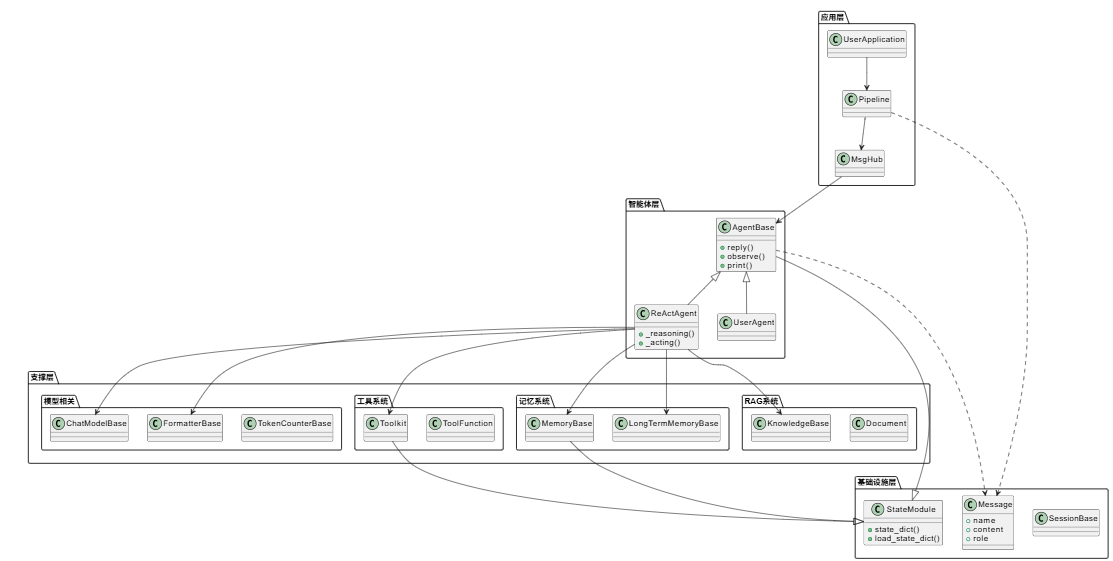
这个架构图展示了 AgentScope 的四层设计:
- 应用层:Pipeline 和 MsgHub 负责多智能体的编排和消息路由
- 智能体层:AgentBase 及其子类(ReActAgent、UserAgent)是框架的核心
- 支撑层:模型、工具、记忆、RAG 等为智能体提供各种能力
- 基础设施层:StateModule 和 Message 提供基础能力
关键文件目录结构
了解源码目录结构,能帮你快速定位相关代码。AgentScope 的源码主要位于 src/agentscope/ 目录下:
src/agentscope/
├── __init__.py # 框架入口,包含 init() 函数
├── _logging.py # 日志系统
├── _run_config.py # 运行时配置
│
├── agent/ # 智能体模块
│ ├── __init__.py
│ ├── _agent_base.py # AgentBase 基类(核心)
│ ├── _agent_meta.py # Agent 元类,处理钩子机制
│ ├── _react_agent_base.py # ReActAgentBase 基类
│ ├── _react_agent.py # ReActAgent 实现(核心)
│ ├── _user_agent.py # UserAgent 实现
│ └── _user_input.py # 用户输入处理
│
├── model/ # 模型模块
│ ├── _model_base.py # ChatModelBase 接口
│ ├── _openai_model.py # OpenAI 实现
│ ├── _dashscope_model.py # DashScope 实现
│ └── ...
│
├── formatter/ # 格式化器模块
│ ├── _formatter_base.py # FormatterBase 基类
│ ├── _openai_formatter.py
│ └── ...
│
├── tool/ # 工具模块
│ ├── _toolkit.py # Toolkit 实现
│ ├── _types.py # 工具类型定义
│ └── _coding/ # 代码执行工具
│
├── memory/ # 记忆模块
│ ├── _memory_base.py # MemoryBase 基类
│ ├── _in_memory_memory.py # 内存记忆实现
│ ├── _long_term_memory_base.py
│ └── _reme/ # ReMe 长期记忆
│
├── message/ # 消息模块
│ ├── _message_base.py # Msg 类定义
│ └── _message_block.py # 消息块(TextBlock、ToolUseBlock 等)
│
├── module/ # 基础模块
│ └── _state_module.py # StateModule 基类(状态管理)
│
├── pipeline/ # 管道模块
│ ├── _msghub.py # MsgHub 实现
│ ├── _class.py # Pipeline 类
│ └── _functional.py # Pipeline 函数式接口
│
├── rag/ # RAG 模块
│ ├── _knowledge_base.py # KnowledgeBase
│ ├── _document.py # Document
│ └── _store/ # 向量存储
│
└── ... # 其他模块(session、tracing、evaluate 等)
关键文件说明:
agent/_agent_base.py:智能体的基类,定义了reply、observe、print等核心方法agent/_react_agent.py:ReActAgent 的完整实现,包含推理-行动循环module/_state_module.py:状态管理的基础实现,所有有状态对象都继承自它message/_message_base.py:消息类的定义,是框架中最重要的数据结构tool/_toolkit.py:工具集的实现,管理工具的注册和执行
当你想要深入某个功能时,可以从这些关键文件入手。比如想理解状态管理,就从 _state_module.py 开始;想理解工具执行,就从 _toolkit.py 开始。
关键流程:ReAct 执行循环
ReAct 循环的完整流程
ReActAgent 的核心是 reply 方法,它实现了完整的推理-行动循环:
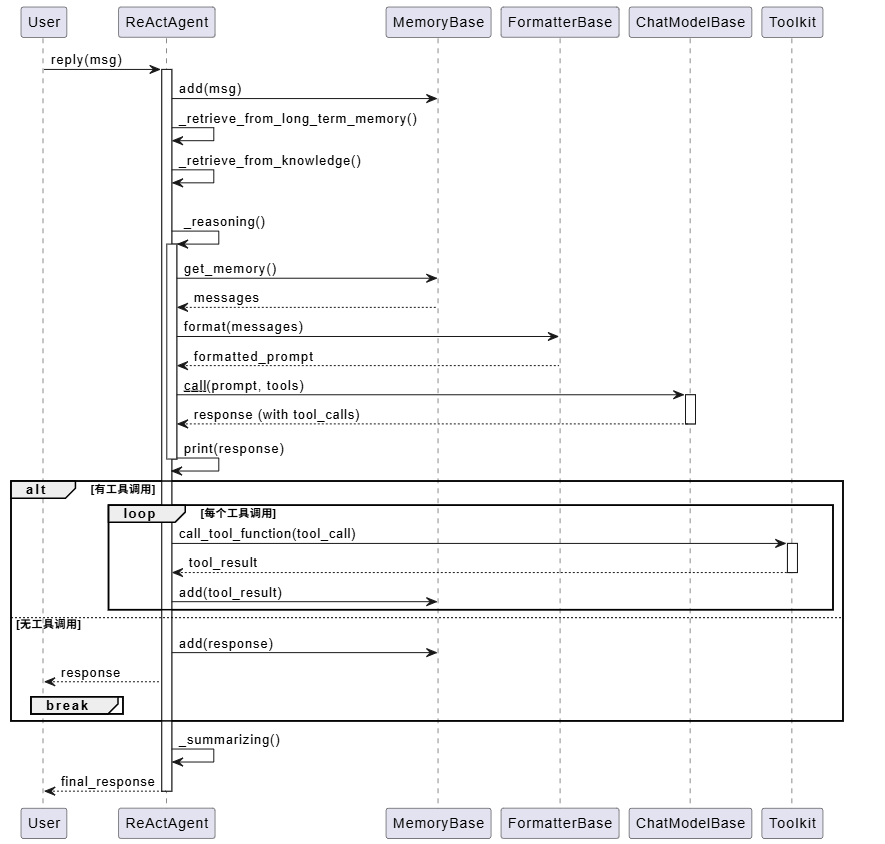
这个流程展示了 ReAct 模式的核心:智能体在推理和行动之间循环,直到生成最终答案或达到最大迭代次数。
关键代码:reply 方法的核心逻辑
让我们看看 reply 方法的关键部分:
# -------------- The reasoning-acting loop --------------
for _ in range(self.max_iters):
# -------------- The reasoning process --------------
msg_reasoning = await self._reasoning(tool_choice)
# -------------- The acting process --------------
futures = [
self._acting(tool_call)
for tool_call in msg_reasoning.get_content_blocks("tool_use")
]
# Parallel tool calls or not
if self.parallel_tool_calls:
structured_outputs = await asyncio.gather(*futures)
else:
# Sequential tool calls
structured_outputs = [await _ for _ in futures]
# -------------- Check for exit condition --------------
if not msg_reasoning.has_content_blocks("tool_use"):
# Exit the loop when no tool call is needed
return msg_reasoning
这段代码展示了几个关键点:
- 循环控制:最多执行
max_iters次 - 并行工具调用:如果启用
parallel_tool_calls,工具会并行执行 - 退出条件:当没有工具调用时,返回结果
关键技术点
1. 状态管理机制
ReActAgent 继承自 StateModule,这意味着它可以自动管理状态。当你给 ReActAgent 设置 Memory 或 Toolkit 时:
agent = ReActAgent(
memory=InMemoryMemory(), # 自动被纳入状态管理
toolkit=Toolkit(), # 自动被纳入状态管理
...
)
这些子模块会自动被 StateModule 追踪,支持嵌套状态序列化:
def __setattr__(self, key: str, value: Any) -> None:
"""Set attributes and record state modules."""
if isinstance(value, StateModule):
if not hasattr(self, "_module_dict"):
raise AttributeError(...)
self._module_dict[key] = value
super().__setattr__(key, value)
这样,你可以轻松保存和恢复整个智能体的状态,包括记忆、工具集等所有子组件。
2. 钩子(Hook)机制
AgentScope 提供了强大的钩子机制,让你可以在关键节点插入自定义逻辑。ReActAgent 支持以下钩子类型:
pre_reasoning/post_reasoning:推理前后pre_acting/post_acting:行动前后pre_reply/post_reply:回复前后pre_print/post_print:打印前后
钩子可以是类级别的(所有实例共享)或实例级别的(仅当前实例使用)。这种设计让你可以:
- 在推理前修改输入参数
- 在行动后处理工具结果
- 在打印前格式化输出
- 等等
3. 实时介入(Realtime Steering)
这是 AgentScope 的一个亮点功能。智能体在执行过程中可以被中断:
except asyncio.CancelledError as e:
interrupted_by_user = True
raise e from None
finally:
# Post-process for user interruption
if interrupted_by_user and msg:
# Fake tool results
tool_use_blocks: list = msg.get_content_blocks("tool_use")
for tool_call in tool_use_blocks:
msg_res = Msg(
"system",
[
ToolResultBlock(
type="tool_result",
id=tool_call["id"],
name=tool_call["name"],
output="The tool call has been interrupted by the user.",
),
],
"system",
)
await self.memory.add(msg_res)
当用户中断时,框架会:
- 捕获
CancelledError - 为未完成的工具调用生成"假"结果
- 将中断信息加入记忆
- 智能体可以在下一轮推理中感知到中断
这种设计让智能体能够优雅地处理中断,而不是简单地崩溃。
4. ReAct 模式的实现
ReAct 模式的核心是分离推理和行动。让我们看看 _reasoning 和 _acting 的实现:
推理过程(_reasoning):
async def _reasoning(
self,
tool_choice: Literal["auto", "none", "required"] | None = None,
) -> Msg:
# 格式化消息
prompt = await self.formatter.format(
msgs=[
Msg("system", self.sys_prompt, "system"),
*await self.memory.get_memory(),
*await self._reasoning_hint_msgs.get_memory(),
],
)
# 调用模型
res = await self.model(
prompt,
tools=self.toolkit.get_json_schemas(),
tool_choice=tool_choice,
)
# 处理流式输出
# ...
行动过程(_acting):
async def _acting(self, tool_call: ToolUseBlock) -> dict | None:
tool_res_msg = Msg(...)
try:
# 执行工具调用
tool_res = await self.toolkit.call_tool_function(tool_call)
# 处理流式结果
async for chunk in tool_res:
# ...
except Exception as e:
# 错误处理
# ...
这种分离让代码更清晰,也更容易扩展和测试。
总结
ReActAgent 的设计体现了 AgentScope 框架的几个核心理念:
- 模块化:通过组合不同的组件(模型、格式化器、工具集、记忆)来构建智能体
- 透明性:所有关键流程都对开发者可见,可以精确控制
- 可扩展性:通过钩子机制和状态管理,可以轻松扩展功能
- 异步优先:充分利用 Python 异步编程,支持并发和流式处理
理解 ReActAgent 的实现,是深入 AgentScope 框架的关键。在下一篇文章中,我们会分析 RAG、Memory 和状态管理系统的实现,这些组件为智能体提供了"记忆"能力。

















 2153
2153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









