






一、关于决策树
1.决策树是一种机器学习算法,用于解决分类和回归问题。它通过对数据集进行分割,并在每个分割点上基于特征属性做出决策,最终形成一个树状结构。
决策树的核心思想是通过一系列的判断节点来将数据集划分成不同的子集,直到达到某个终止条件,例如所有样本都属于同一类别或者达到了树的最大深度。在每个判断节点上,根据特征属性的取值进行划分,使得划分后的子集中同类别的样本尽可能地聚集在一起。
二、决策树的实现步骤
1. 数据准备:收集并整理用于训练决策树的数据集。确保数据集包含特征属性和目标变量。
2. 特征选择:根据某种指标(如信息增益、基尼系数等),选择最佳的特征作为判断节点。
3. 构建决策树:从根节点开始,根据选定的特征进行数据集的分割,并生成新的子集。递归地对每个子集进行相同的操作,直到满足终止条件。
4. 终止条件:决策树的构建可以通过以下几种方式终止:
- 所有样本属于同一类别。
- 达到了预定义的树的最大深度。
- 没有更多特征可供选择。
5. 树的修剪(可选):为了避免过拟合,可以对决策树进行修剪操作,剪去一些不必要的叶节点。
6. 决策树的评估:使用测试数据集来评估构建的决策树模型的性能,并计算准确率、精确率、召回率等指标。
7. 使用决策树进行预测:将新的未知样本输入到决策树中,根据每个节点的判断条件进行划分,最终得到预测结果。
8. 可视化决策树(可选):将决策树以图形的形式展示出来,便于理解和解释决策过程。
三、信息熵
信息熵的计算公式如下: H(X) = - Σ p(x) * log2(p(x))或者也可以表示为
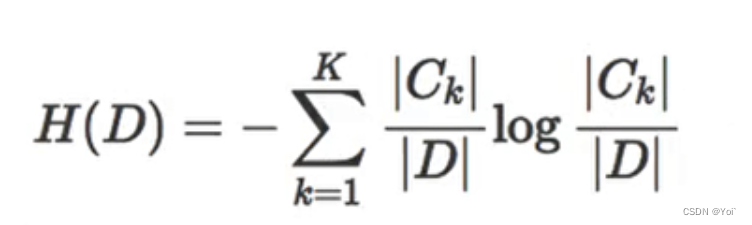
其中,H(X)表示随机变量X的信息熵,p(x)表示随机变量X取值为x的概率,D表示数据集样本个数,|Ck|表示属于类Ck的样本个数。 信息熵的值越大,表示数据集的不确定性和混乱程度越高;而信息熵的值越小,表示数据集的纯度和有序程度越高。
例如,考虑一个二分类问题,数据集中有20个样本,其中10个属于类别A,10个属于类别B。则该数据集的信息熵可以计算如下: H(X) = - (10/20) * log2(10/20) - (10/20) * log2(10/20) = 1 这表示该数据集的信息熵为1,即数据集的不确定性和混乱程度较高。
信息熵在决策树算法中常用于选择最佳分割点,以使得划分后的子节点的纯度最大化。通过计算每个特征的信息增益(父节点的信息熵与子节点信息熵的差值),决策树可以选择最优特征来构建决策树的分支。这样可以在构建决策树时,尽量减少不确定性和混乱程度,从而提高决策树的预测能力。
四、决策树代码实现
以下是实现决策树的示例代码
import numpy as np
class Node:
def __init__(self, feature=None, threshold=None, left=None, right=None, value=None):
self.feature = feature
self.threshold = threshold
self.left = left
self.right = right
self.value = value
def gini_index(y):
classes = np.unique(y)
n_samples = len(y)
gini = 0
for c in classes:
p = np.sum(y == c) / n_samples
gini += p * (1 - p)
return gini
def split_dataset(X, y, feature, threshold):
left_mask = X[:, feature] <= threshold
right_mask = X[:, feature] > threshold
X_left, y_left = X[left_mask], y[left_mask]
X_right, y_right = X[right_mask], y[right_mask]
return X_left, y_left, X_right, y_right
def find_best_split(X, y):
best_gini = np.inf
best_feature = None
best_threshold = None
n_features = X.shape[1]
for feature in range(n_features):
thresholds = np.unique(X[:, feature])
for threshold in thresholds:
X_left, y_left, X_right, y_right = split_dataset(X, y, feature, threshold)
gini = (len(y_left) * gini_index(y_left) + len(y_right) * gini_index(y_right)) / len(y)
if gini < best_gini:
best_gini = gini
best_feature = feature
best_threshold = threshold
return best_feature, best_threshold
def build_tree(X, y):
if len(np.unique(y)) == 1:
return Node(value=y[0])
best_feature, best_threshold = find_best_split(X, y)
X_left, y_left, X_right, y_right = split_dataset(X, y, best_feature, best_threshold)
left_child = build_tree(X_left, y_left)
right_child = build_tree(X_right, y_right)
return Node(feature=best_feature, threshold=best_threshold, left=left_child, right=right_child)
def predict(node, sample):
if node.value is not None:
return node.value
if sample[node.feature] <= node.threshold:
return predict(node.left, sample)
else:
return predict(node.right, sample)
# 示例数据集
X = np.array([[2, 2], [2, 3], [3, 2], [3, 3], [4, 2], [4, 3]])
y = np.array([0, 0, 1, 1, 1, 0])
# 构建决策树
tree = build_tree(X, y)
# 预测新样本
sample = np.array([3.5, 2.5])
prediction = predict(tree, sample)
print("预测结果:", prediction)
运行结果为:
四、总结
决策树可以直观地表示特征与目标之间的关系,易于解释和理解。它们生成的规则类似于人类进行决策的方式。并且在训练之前不需要进行数据归一化或标准化等预处理步骤。它们生成的规则类似于人类进行决策的方式。对于机器学习的分类问题,决策树还能够实现如垃圾邮件过滤、图像识别和文本分类等领域。















 1326
1326











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









