







Lucene 源码剖析
4.3 索引创建过程
文档的索引过程是通过DocumentsWriter的内部数据处理链完成的,DocumentsWriter可以实现同时添加多个文档并将它们写入一个临时的segment中,完成后再由IndexWriter和SegmentMerger合并到统一的segment中去。DocumentsWriter支持多线程处理,即多个线程同时添加文档,它会为每个请求分配一个DocumentsWriterThreadState对象来监控此处理过程。处理时通过DocumentsWriter初始化时建立的DocFieldProcessor管理的索引处理链来完成的,依次处理为DocFieldConsumers、DocInverter、TermsHash、FreqProxTermsWriter、TermVectorsTermsWriter、NormsWriter以及StoredFieldsWriter等。
索引创建处理过程及类的主线请求链表如下图所示:
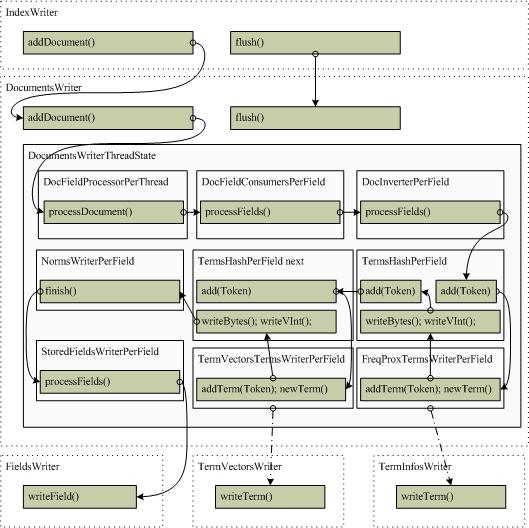
下面介绍主要步骤的处理过程
4.3.1 DocFieldProcessorPerThread.processDocument()
该方法是处理一个文档的调度函数,负责整理文档的各个fields数据,并创建相应的DocFieldProcessorPerField对象来依次处理每一个field。该方法首先调用索引链表的startDocument()来初始化各项数据,然后依次遍历每一个fields,将它们建立一个以field名字计算的hash值为key的hash表,值为DocFieldProcessorPerField类型。如果hash表中已存在该field,则更新该FieldInfo(调用FieldInfo.update()方法),如果不存在则创建一个新的DocFieldProcessorPerField来加入hash表中。注意,该hash表会存储包括当前添加文档的所有文档的fields信息,并根据FieldInfo.update()来合并相同field名字的域设置信息。
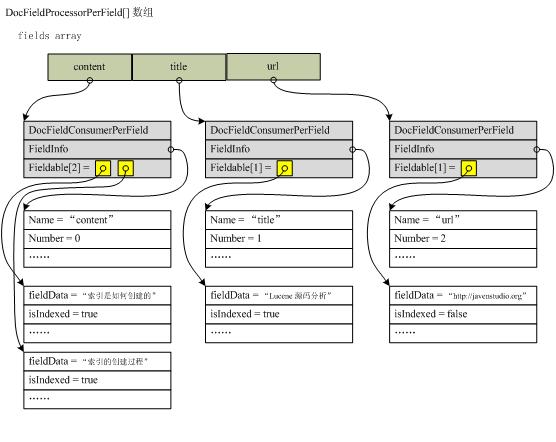
建立hash表的同时,生成针对该文档的fields[]数组(只包含该文档的fields,但会共用相同的fields数组,通过lastGen来控制当前文档),如果field名字相同,则将Field添加到DocFieldProcessorPerField中的fields数组中。建立完fields后再将此fields数组按field名字排序,使得写入的vectors等数据也按此顺序排序。之后开始正式的文档处理,通过遍历fields数组依次调用DocFieldProcessorPerField的processFields()方法进行(下小节继续讲解),完成后调用finishDocument()完成后序工作,如写入FieldInfos等。
下面举例说明此过程,假设要添加如下一个文档:
| 文档域 | 内容 | 是否索引 |
| title | Lucene 源码分析 | true |
| url | http://javenstudio.org | false |
| content | 索引是如何创建的 | true |
| content | 索引的创建过程 | true |
下图描述处理后fields数组的数据结构
http://www.cnblogs.com/eaglet/archive/2009/02/16/1391506.html















 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









