







 本文介绍了机器学习中的监督学习方法,包括数据特征提取、线性回归示例以及提升算法中的AdaBoosting。通过实例演示了如何使用线性回归分析变量关系,并探讨了如何通过弱分类器的组合形成强大分类器,涉及霍夫丁不等式和PAC理论。
本文介绍了机器学习中的监督学习方法,包括数据特征提取、线性回归示例以及提升算法中的AdaBoosting。通过实例演示了如何使用线性回归分析变量关系,并探讨了如何通过弱分类器的组合形成强大分类器,涉及霍夫丁不等式和PAC理论。
这一章围绕机器学习中的一个重要方法——监督学习展开,分别从机器学习的基本概念,线性回归分析,提升算法三个方面来介绍。
一·机器学习: 从数据中学习知识
机器学习:
1.
原始数据中提取特征
2.
学习映射函数
𝑓
3.
通过映射函数
𝑓
将原始数据映射到语义空间,即寻找数据和任务目标之间的关系
机器学习的分类 :
1.监督学习
(supervised learning)
数据有标签、一般为回归或分类等任务
2.无监督学习
(un-supervised learning)
数据无标签、一般为聚类或若干降维任务
3.强化学习
(reinforcement learning)
序列数据决策学习,一般为与从环境交互中学习
可以将1,2合称为半监督学习


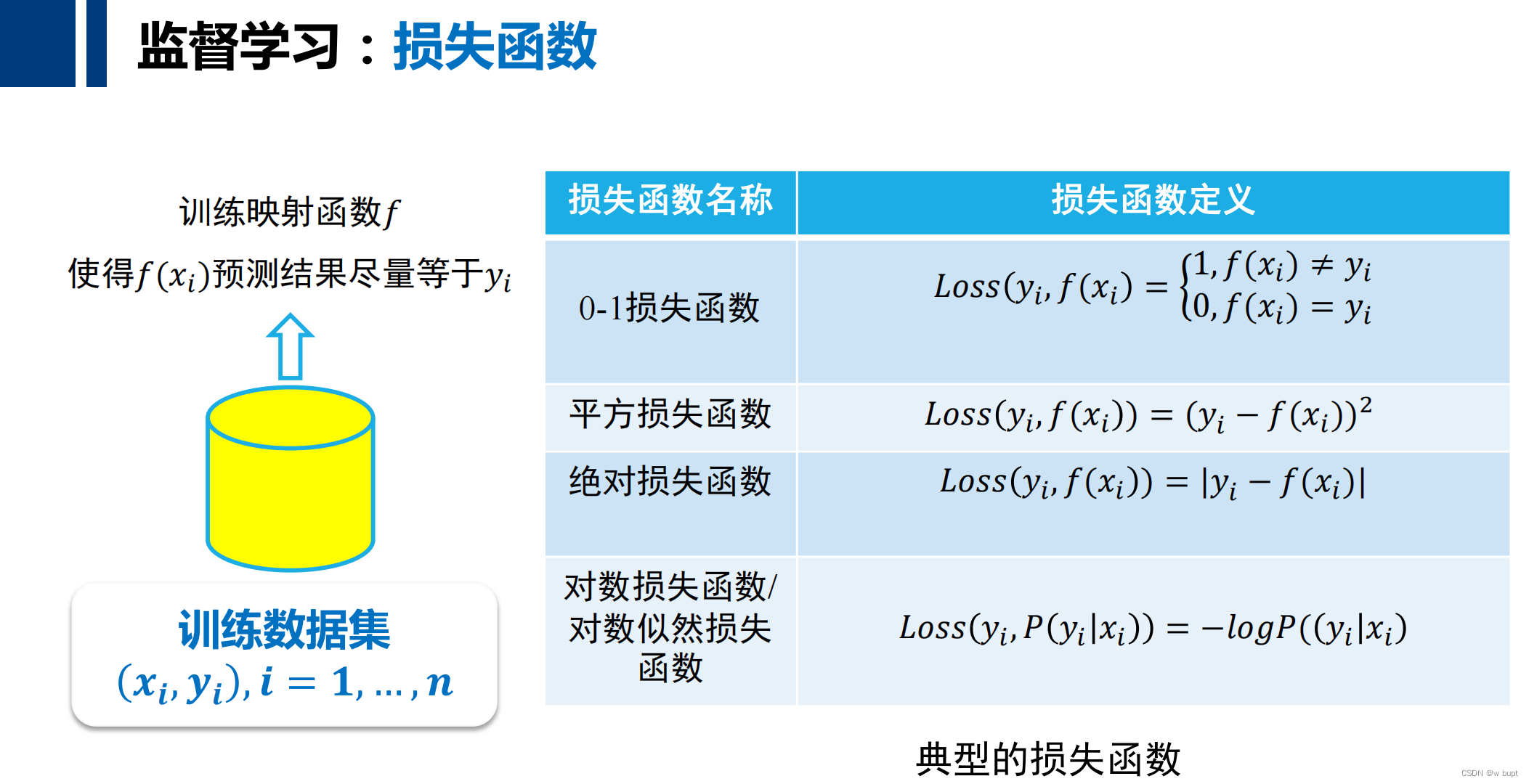
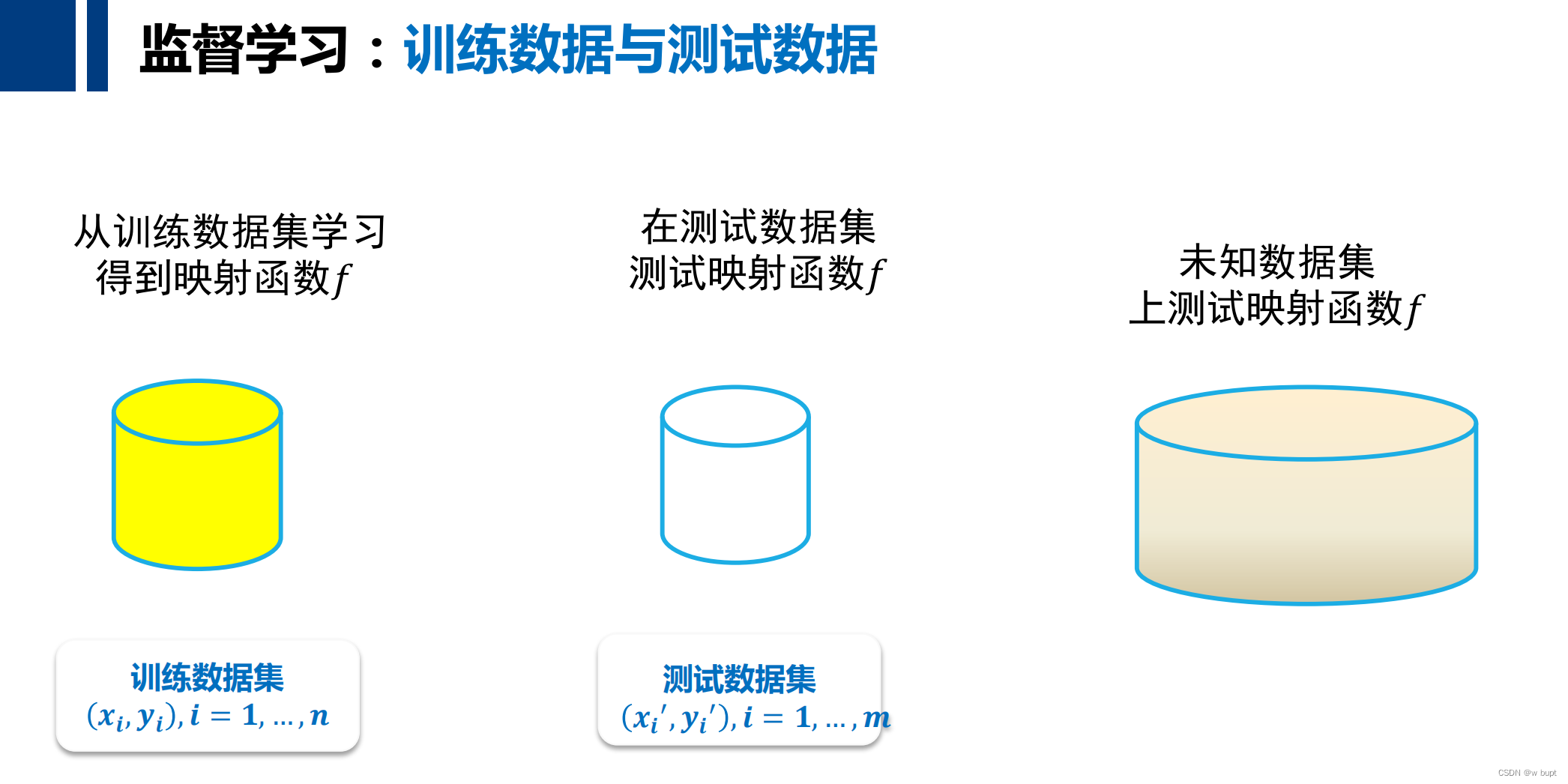
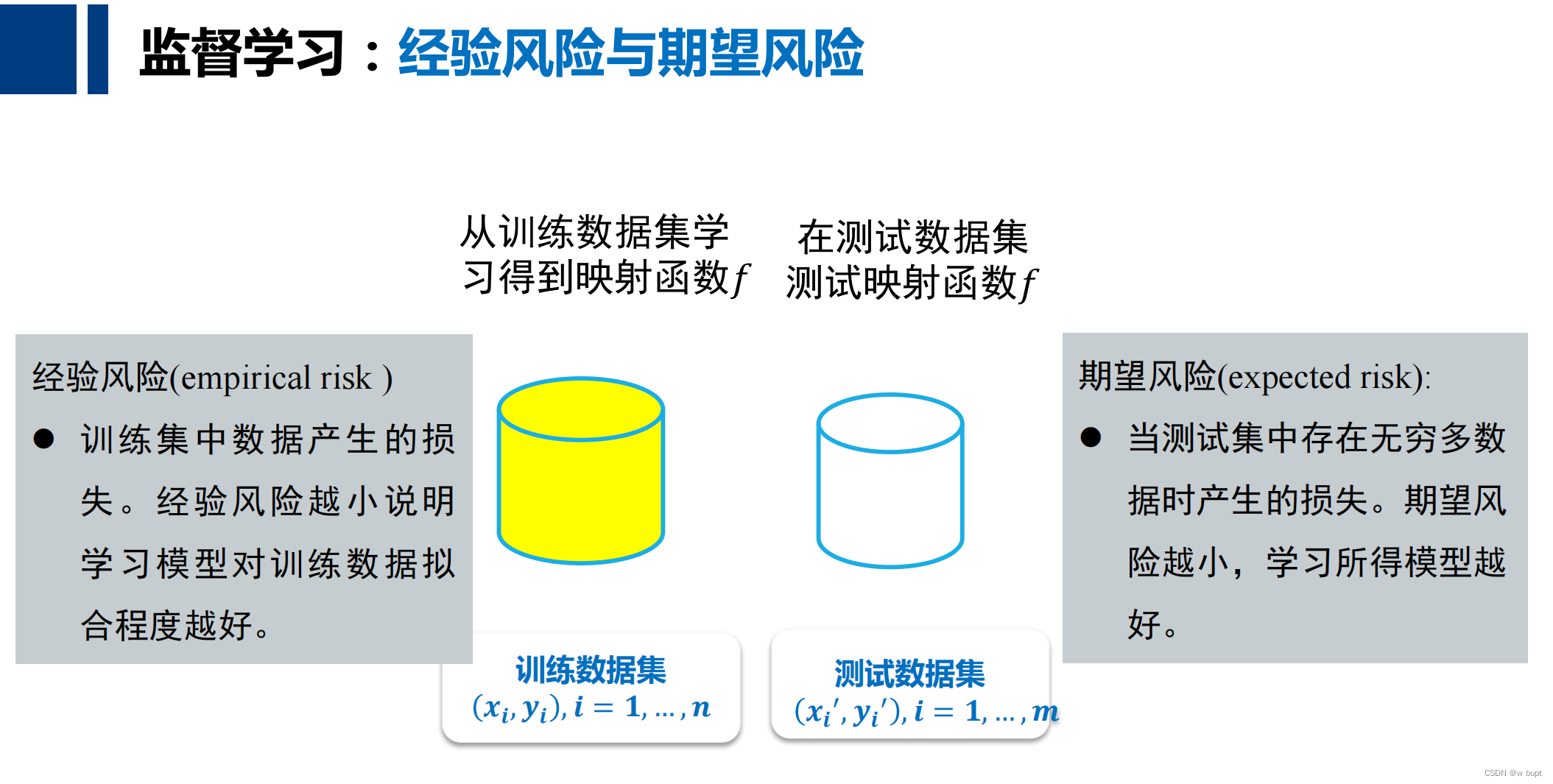


















对于监督学习所达到的效果,我们期望的是经验风险和期望风险都很小,除了这一种可能性,往往还会出现以下可能情况。
二·线性回归(linear regression)
线性回归是监督学习的主要学习任务之一。在现实生活中,往往需要分析若干变量之间的关系,如碳排放量与气候变暖之间的关系、某一商品广告投入量与该商品销售量之间的关系等,这种分析不同变量之间存在关系的研究叫回归分析,刻画不同变量之间关系的模型被称为回归模型。如果这个模型是线性的,则称为线性回归模型。
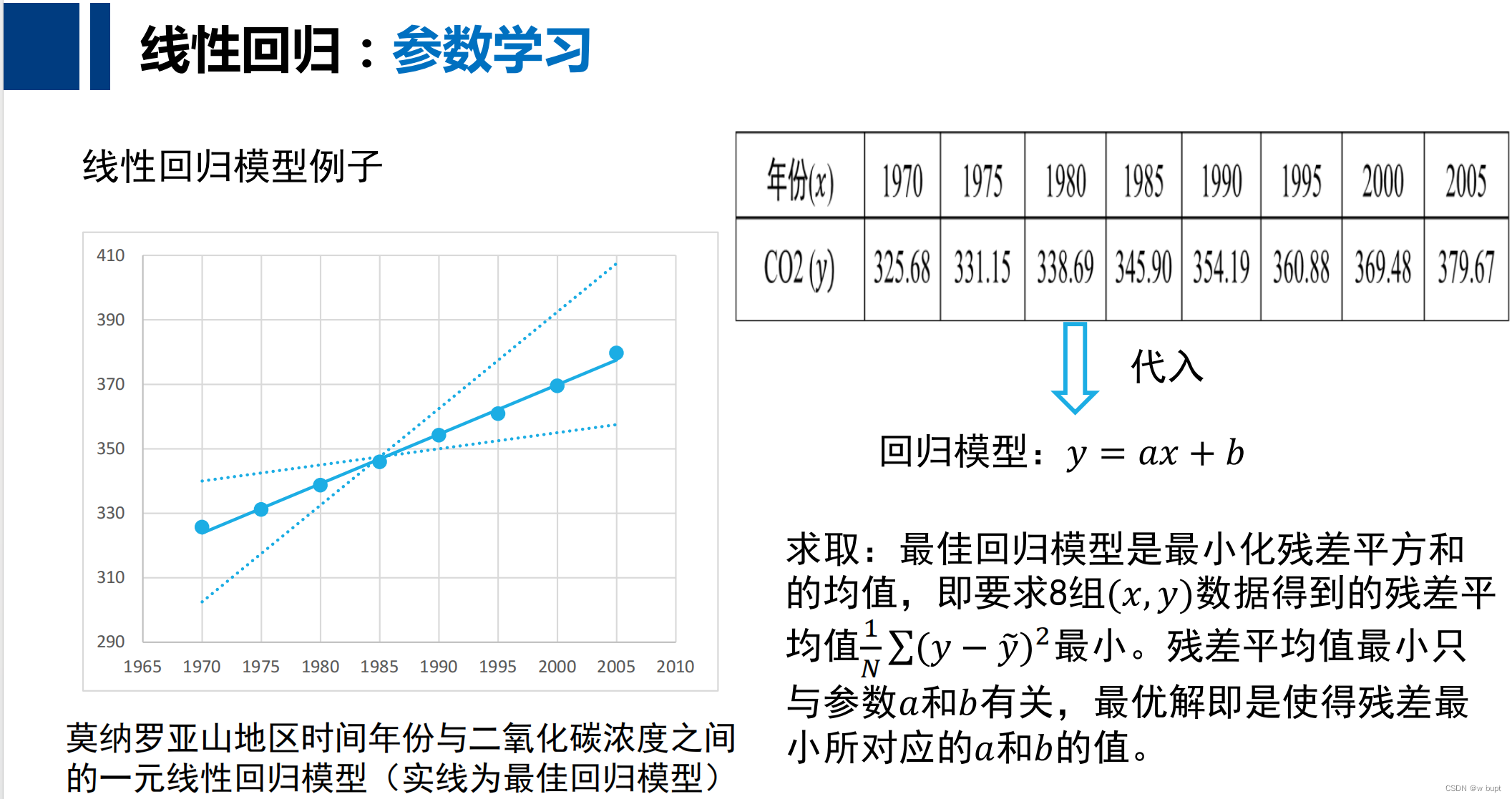
下面以莫纳罗亚山(夏威夷岛的活火山)从1970年到2005年每5年的二氧化碳浓度为例,介绍线性回归。
根据表中的x,y可以求解出a,b的值。因此可以得到:预测莫纳罗亚山地区二氧化碳浓度的一元线性回归模型为“ 二氧化碳浓度 =1.5344 × 时间年份 − 2698.9” , 即𝑦 = 1.5344𝑥 − 2698.9。
三·提升算法
3.1Boosting (adaptive boosting, 自适应提升):
对于一个复杂的分类任务,可以将其分解为若干子任务,然后将若干子任务完成方法综合,最终完成该复杂任务。
将若干个弱分类器
(weak classifiers)
组合起来,形成一个强分类器(strong classifier)
。
3.2计算学习理论:
霍夫丁不等式(Hoeffding’s inequality)
概率近似正确 (probably approximately correct, PAC)
对于统计电视节目收视率这样的任务,可以通过不同的采样方法(即不同模型)来计算收视率。 每个模型会产生不同的误差。 问题:如果得到完成该任务的若干“弱模型”,是否可以将这些弱模型组合起来,形成一个“强模型”。该“强模型” 产生误差很小呢?这就是概率近似正确(PAC)要回答的问题。
3.3Ada Boosting 实现:
思路描述
Ada Boosting
算法中两个核心问题:
在每个弱分类器学习过程中,如何改变训练数据的权重:提高在上一轮中分类错误样本的权重。
如何将一系列弱分类器组合成强分类器:通过加权多数表决方法来提高分类误差小的弱分类器的权重,让其在最终分类中起到更大作用。同时减少分类误差大的弱分类器的权重,让其在最终分类中仅起到较小作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









